CS 111 Winter 2015 - Lecture 15 Scribe Notes
Notes by: Gil Bar-Or and Nikhil Gupta
We ended the last lecture with a discussion on page tables and Return-Oriented Programming (ROP).
We will begin this lecture by reviewing page tables and page fault mechanisms and then delving into the topics of page fault policy and distributed systems .
A page table is a data structure which maps virtual addresses to physical addresses. Virtual memory is used by an operating system to provide the illusion that a process has a large contiguous chunk of memory, when in reality its memory is actually scattered throughout different areas of physical memory or possibly even located to another hard disk. A page table is used to find the physical address of the data a process is trying to find using its virtual address.
Page Fault Mechanism
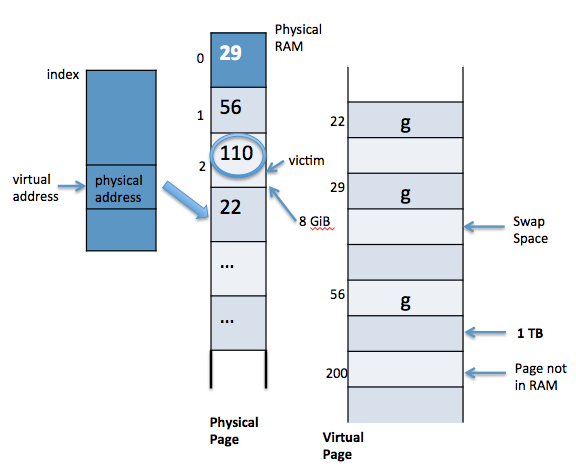
A page fault is an interrupt (a trap) made by the hardware when a program tries to access a memory page mapped in the virtual page but not loaded in physical memory.
If a page fault occurs (with a valid virtual address), the following mechanism is followed:
1. Choose a "victim" page from physical memory.
2. Write out the victim page to a swap space (an empty page in virtual memory).
3. Read new desired page into the victim's former page in physical memory.
The following diagram represents an example of dealing with a page fault in the kernel:
Page Fault Policies
A page fault policy decides how to select victims. When choosing a policy, there are two competing qualities:
1. Efficiency - not a lot of CPU resources within the kernel
2. Avoids thrashing (constant state of paging)
FIFO - First In First Out (simple policy)
A reference string is a list of virtual page numbers.
First In First Out means we choose the entry which has been in memory for the longest time.
Suppose we take a toy reference string with 5 pages of virtual memory: 0, 1..., 4.
Take the trace: 0 1 2 3 0 1 4 0 1 2 3 4
0 |
1 |
2 |
3 |
0 |
1 |
4 |
0 |
1 |
2 |
3 |
4 |
|
A |
Δ0 |
0 |
0 |
Δ3 |
3 |
3 |
Δ4 |
4 |
4 |
4 |
4 |
4 |
B |
Δ1 |
1 |
1 |
Δ0 |
0 |
0 |
0 |
0 |
Δ2 |
2 |
2 |
|
C |
Δ2 |
2 |
2 |
Δ1 |
1 |
1 |
1 |
1 |
Δ3 |
3 |
Cost = 9 Page Faults (Number of Deltas)
What happens if we buy more RAM?
0 |
1 |
2 |
3 |
0 |
1 |
4 |
0 |
1 |
2 |
3 |
4 |
|
A |
Δ0 |
0 |
0 |
0 |
0 |
0 |
Δ4 |
4 |
4 |
4 |
Δ3 |
3 |
B |
Δ1 |
1 |
1 |
1 |
1 |
1 |
Δ0 |
0 |
0 |
0 |
Δ4 |
|
C |
Δ2 |
2 |
2 |
2 |
2 |
2 |
Δ1 |
1 |
1 |
1 |
||
D |
Δ3 |
3 |
3 |
3 |
3 |
3 |
Δ2 |
2 |
2 |
Cost = 10 Page Faults
This is an illustration of Belady's anomaly, that more memory can sometimes actually increase the number of page faults and make things slower.
However, usually more memory actually speeds up the process.
LRU - Least Recently Used
Least Recently Used means we choose the victim to be the entry which has not been accessed for the longest time.
0 |
1 |
2 |
3 |
0 |
1 |
4 |
0 |
1 |
2 |
3 |
4 |
|
A |
Δ0 |
0 |
0 |
Δ3 |
3 |
3 |
Δ4 |
4 |
4 |
Δ2 |
2 |
2 |
B |
Δ1 |
1 |
1 |
Δ0 |
0 |
0 |
0 |
0 |
0 |
Δ3 |
3 |
|
C |
Δ2 |
2 |
2 |
Δ1 |
1 |
1 |
1 |
1 |
1 |
Δ4 |
Cost = 10 Page Faults
Oracle of Delphi
This policy has the ability to look ahead and see which page is not needed for the longest time.
0 |
1 |
2 |
3 |
0 |
1 |
4 |
0 |
1 |
2 |
3 |
4 |
|
A |
Δ0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
Δ2 |
2 |
2 |
B |
Δ1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
Δ3 |
3 |
|
C |
Δ2 |
Δ3 |
3 |
3 |
Δ4 |
4 |
4 |
4 |
4 |
4 |
Cost = 7 Page Faults!
Paging Optimizations
There are two main ways to implement paging optimizations: demand paging and dirty bit.
Demand Paging
Demand paging allows only pages that are demanded to be brought into memory. Two ways are possible to start up using demand paging:
1. Load the 1st p pages into RAM, then run.
+ Better throughput if program uses 1st p pages
2. Load only the 1st page into RAM, then run it.
+ Startup is faster
Dirty bit
A dirty bit records whether a page on RAM is the same as what is on disk.
Dirty bits are implemented into the page table using the "r, w, x" permission bits.
Cost of a page fault
We can break down the cost of a page fault to the following parts:
1. CPU for policy decision. (Negligible)
2. Trap overhead (Negligible)
3. Write out victim's contents (skip if victim hasn't changed since read in)
4. Read in faulting page
Use and efficiency of Virtual Memory using Programs
Emacs
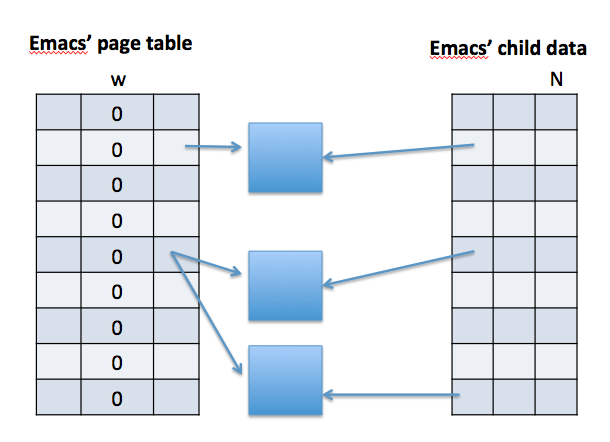
Problem: Fork() has to copy all of Emacs' virtual memory.
Solution: Child doesn't get parent's data, merely pairs it to its data.
Instead of cloning all memory just clone page table.
(e.g. 6 GiB ---> couple MiB)
See the diagram below for a demonstration on Emacs' page table after a fork:
Performance Problem: Copy of page table.
Solution: vfork() syscall
- Allows parent/child to share everything (including virtual table clones) but since both programs access shared memory, parent "freezes" until the child execs or exits.
- If exec: replaces memory, so parent has sole access
- If exit: child loses memory, so parent has sole access
This solution is controversial, but fast.
Malloc Implementation
p = malloc(1000);
p is now a pointer to a virtual address in virtual memory, after malloc finds 1000 unused bytes.
mmap(...)
- Lets app modify its own page table (alters your process' page table).
- Typical use: map a file's pages into RAM.
- E.g. DNA Data (CGATCCCG...): use mmap to put that data into RAM.
- This will only work for files, not streams.
Apache
There are other ways to make multiple requests run even faster, and we demonstrate this using a large program like Apache.
for (;;){
fd=accept(...);
read(fd, ...);
handle(fd, ...);
close(fd);
}
The lines from "read" to "close" are the Apache code in the child thread.
Using threads has the following pros and cons:
+10-40 times faster than fork
-More brittle
In this case, 1000 requests = 1000 threads, and since we only have 8 CPUs, context switching is a significant cost.
An even faster approach would involve just 8 threads (1/CPU), each with its own event queue, and using an event-oriented async.
Distributed Systems and Remote Procedure Calls (RPC)
We will briefly introduce distributed systems in this lecture.
Before now, we focused on virtualization to enforce hardware modularity.
A distributes system is a system where components from multiple computers communicate and interact with each other.
Similar to how we use system calls to switch control from a process to the kernel, distributed systems use remote procedure calls (RPC) to request a service from a program on another computer.
The following diagram demonstrates how a distributed system works. An application located on the client RAM can interact with the server RAM that it is connected to on a network. This server RAM works like a "kernel".

However, there are several characteristics of an RPC that differ from system calls:
- Caller and callee do not share memory.
- No call by reference allowed.
- Caller and callee might use different hardware architecture.
An example of this last characteristic is if you have x86, x86-64, and SPARC machines all on the same network. In this case, a "long" in x86 is 4 bytes but in x86-64 it is 8 bytes. Meanwhile, SPARC uses big endian, as opposed to the other two machines which use little endian.
Marshalling (Serialization/Pickling)
We can solve this issue by using a technique known as marshalling, which is the process of converting the memory representation of an object into a format that can be transferred to other machines.
Marshalling is similar to a technique known as serialization.