Lecture 15: VM and processes; distributed systems
Page Faults
Page faults occur when a process tries to access a page in virtual memory and not in RAM. This results in a hardware trap.
Page Fault Mechanism
The way that a page fault mechanism works is a victim is first chosen from the physical memory. This victim is written out to swap space and the new page is read into physical memory.
Policies
Now that we have the mechanism, we need to decide on a page replacement policy. To do this, we need to select victims. We want this selection to be first of all fast and efficient (we don't want this process to take a lot of CPU) while also avoiding thrashing, which is when we put pages in and out without getting any real work done. These 2 policies tend to compete against each other, but we're aiming to find a sweet spot.
But how do you tell which policy avoids thrashing better? Simply run the policy with real programs. Whichever thrashes less, wins. When comparing these policies, the focus is on when the program accesses a different page. Because of this, the data that we look at are strings of page accesses. These keep track of which pages the program accesses in the order it accesses it. For our examples, we'll be using the toy reference string:
0 1 2 3 0 1 4 0 1 2 3 4
The numbers 0 through 4 represent 5 different pages of virtual memory, and in future diagrams ? represents junk memory and a delta represents a page cache which is costly!
Policy 1: First In First Out
The first policy that we'll look at is FIFO. It's a simple policy and it may not be great in general but it's very efficient. Looking at the diagram below, we see that running FIFO on the toy string results in a cost of 9.
This cost doesn't really mean much by itself, but it's a good baseline to compare the other policies to.
Hardware Policy: Just Add More RAM!
What if we take a hardware approach instead of a software approach? If we increase our RAM and keep using FIFO, we should see less page faults, right? If we look at the diagram, though, our increased RAM actually increased our cost to 10!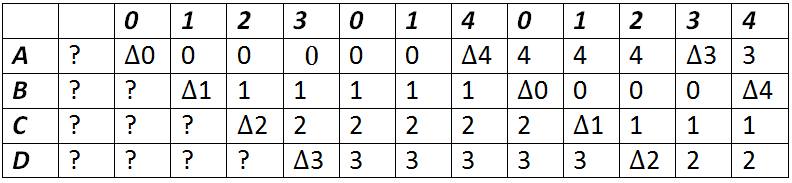
This larger cost is due to Belady's anomaly. In general, if you throw more cache at a problem, you'll get better results; but on occasion, it may actually make things slower so be careful!
Policy 2: Least Recently Used
What if we try a least recently used approach? Looking at the diagram, we actually get a cost increase to 10, just like with the increased RAM situation. 
This is again somewhat of an anomaly due to the sneakily crafted toy string. Looking at the string, we see that the page hits 'wrap around', so the LRU algorithm keeps getting page faults. So how do we bypass this problem? Well, what if we focused purely on minimizing page faults and didn't care about efficiency?
Policy 3: Oracle
If we look to the 'future' instead of looking at the past and replaced the page least used in the future, rather than in the past, then this should give us the best possible algorithm. This 'oracle' algorithm (not the real name, just something Eggart calls it), results in 7 page faults, making it clearly the most optimal if we ignore efficiency. 
There still is a big problem, though: the program needs to be run twice to use this policy. You need to run it once just to obtain the reference string and then run it a second time to actually run the policy. Generally this is obviouslly too costly to do, but this policy is extremely useful for programs that get run over and over again. For example, if you need to run a data mining operation every night, you can simply use the string from the previous run to optimize the current run.
Implementing LRU
Let's look at how to implement LRU on an x86 machine. Ideally, everytime something is accessed, the machine would store it in a timestamp column, and the machine can just look at the timestamps when picking victims. Unfortunately, x86's hardware doesn't allow this, so we'll have to use a software approach instead and create a software page table. This software page table can only get updates when the kernel gains control, so mainly during clock interrupt, system call, and most importantly page fault. LRU is basically always implemented this way, which is why x86 does not have the hardware to support the hardware approach.
Paging Optimization
There are two ways that paging optimization are done: demand paging and dirty bit.
Demand Paging
When starting a program, there are two ways to start it: load the first p pages into RAM, then run, or use demand paging where only the first page is loaded, then the program is run. The advantage to loading the first p pages is that you get better throughput if the program uese the first p page. The advantage to using demand pages is that the startup is a lot faster, but there's a disadvantage that there are more page faults.
Dirty Bit
First, let's talk about the cost of a page fault. These are the CPU for a policy decision, the trap overhead, the cost of writing out a victim's contents, and the cost of reading in a faulting page. The last two are the most costly, so those are what we want to reduce the most. The advantage of the dirty bit is that it reduces the cost of writing out a victim's contents. We can use a dirty bit to skip writing out a victim's contents if the victim hasn't been changed on disk since the read in. If the dirty bit is 0 (no changes), we can just discard the victim to save time. This dirty bit can be implemented using r-w-x bits, so we have hardware support.
Emacs
Let's talk about the implementation of emacs really quickly. More specifically, we'll be looking at fork() and vfork().
fork(); //clones all of emac's virtual memory
With fork(), emac's child copies the page table and shares the data table with emacs.
vfork(); //clones, but parent is frozen until child either execs or exits
With vfork(), emac's child shares the parent's page table and data table.
Malloc Implementation
How exactly does malloc work? Suppose we want to allocate a lot of memory:
p = malloc(1000);
Here, p is a pointer into virtual memory. Malloc can use the mmap( ... ) system callto alter a process's page tables. This allows it to map a file's pages into RAM (malloc maps free memory into virtual memory), which allows malloc to run faster. Given how great mmap is, doesn't this make read obsolete? Well, the downside to mmap is that it's much simpler but also slower. When you access memory with mmap, you're at the mercy of the OS's page replacement policy, and they guess wrong too often. mmap is good, just don't assume it's perfect.
Apache
Apache uses forks to deal with network requests. Let's take a look at how this could be implemented:
use fork() to run
{
read(fd, ... );
handle(fd, ... );
close(fd);
}
Unfortunately, this is a slow solution because each fork() needs to clone virtual memory. The solution to this problem would be to use pthread to make a thread for each request. This solution is a whole 10-40x faster than fork, but the tradeoff is that it's more brittle. Furthermore, using threads presents a lot of other problems. If we have 1000 request, we'll have 1000 threads which is absurd when you only have 8 CPUs trying to run 1000 threads. This presents the idea that context switching is a very significant cost. One way to solve this problem is to just have 8 threads (one per CPU), giving each an event queue.
Distributed Systems
We've been focusing on virtualization to enforce modularity. With virtualization, we see:
pid p = fork();
With RPC (distributed system), we see:
int n = read(fd, ...);
Let's compare RPC against syscalls. With RPC, the caller and calle don't share memory, there is no call by reference, and the caller and callee might not use the same hardware architecture. We use marshalling (serialization/pickling) to handle the situation of having two different architectures. The client sends data from RAM to server by first formatting the data before sending it.