Lecture 16: Robustness, parallelism, and NFS
David Yang
Contents:
Potential Failures in Flash Drives
Flash storage drives are vulnerable to failures in a couple of ways. In a paper written by Mai Zheng et al, a number of failure points for drives were investigated:
- Bit corruption - When a bit flips, data may be damaged in a critical manner; the balance on a bank account could be changed, for example. This is predicted in the Lampson-Sturgis assumptions, which states that storage can decay, and that errors can be detected and handled.
- Flying writes - Flash drive controllers are not infallible, and may accidentally write a file to a different location to where it is recorded in the inode.
- Shorn writes - When a flash drive is pulled out in the middle of a write, a file may be left in an incomplete state.
- Metadata corruption - The virtual layer that keeps track of available memory blocks can sometimes malfunction, due to power failure or faulty firmware. This can lead to otherwise valid blocks being considered bad/unusable sectors.
- Dead device - Flash devices can stop working entirely, cause by significant damage to metadata or poor voltage regulation in the flash drive leading to physical damage to the device.
- Unserialisability - Flash drive firmware can decide to write data in a non-linear order for the sake of wear-levelling or because it's faster in a certain configuration. Sometimes, the firmware is buggy, and it writes data out in a manner that it cannot read back, which leads to lost data.
Solutions to Drive Failures
Flash and spinning media alike are vulnerable to faults. A few things can be done to remedy this:
- Only buy foolproof drives - Brands like Isilon and Netapp sell drives that they assure to be rigorously tested. Such drives are prohibitively expensive for the average user though.
- Use a system that can overcome disk errors - like RAID.
RAID
RAID stands for Redundant Array of Independent Disks, and it is a method for combining disks to improve reliability, performance or create larger effective drives. Different types of RAID include:
- RAID 0 - Concatenation. RAID 0 combines drives by joining the drives togethor to make one big drive. Two one-terabyte drives in RAID 0 create an effective two terabyte drive. Very large hard drives can become cost inefficient, and combining multiple smaller, cheaper drives can get around that.
- RAID 1 - Mirroring. RAID 1 makes every drive in a RAID 1 array carry the exact same data. Because each drive contains the same data, no data is lost if one of them becomes non-functional. Reading data off a RAID 1 array is also faster, because the read heads can read off different parts of a file at the same time, or read off two halves of a file that are physically far away from each other on the disk. On the flip side, if you mirror with three 1 terabyte drives, you have an effective 1 terabyte drive available to you, for the price of three drives. There is also a minor slowdown in writing to the disks, as instructions must be sent to write data to each drive, but the bottleneck in drive writes tends to be in the physical writing process, which a RAID 1 array can do concurrently, minimizing additional time spent writing.
- RAID 4 - Parity. One drive is reserved for keeping parity, and each bit in the parity drive is the XOR of the corresponding bits in each of the other drives. For example, say we have drives A, B, C, D and E and we wanted to implement RAID 4 across them. Suppose drive E is our parity drive, the data in drive E is equal to:
A^B^C^D=E
XOR is chosen because in the case of failure, data in the broken drive can be restored from the other drives. For example, if drive B were to fail, the following operation could be done across the rest of the drives to rebuild drive B:
A^C^D^E=B
To show why this works, first we expand E using the operation we used to generate the data in drive E to begin with:
A^C^D^(A^B^C^D)=B
XOR is fully commutative and distributive, so the brackets can be disregarded and the equation rearranged:
A^A^B^C^C^D^D=B
We know that the following are true with XOR:
X^X=0
0^X=X
Where X is some arbitrary pattern of bits. Using this, we can simplify:
0^B^0^0=B
B=B
Which gives us the value of the data in the destroyed disk, using the data from the other drives and the parity bit. Because each bit must be generated from a corresponding bit from each other drive, if one drive is larger than another, the excess data cannot be used as the extra bits have no equivalent in the other drive, and so the other drives cannot be used to act as parity for the excess space. This means some storage space is wasted in a RAID 4 array of mismatching drives, a tradeoff made for more reliability.
This does not work if a second drive is damaged as well however; there is not enough data present in that case to rebuild the contents of either failed drive. In situations where this is critical, servers can use hot spare drives, backup disks that damaged drives can be replaced with and rebuilt in the moment a drive failure is detected. By rebuilding damaged drives immediately, the likelihood of data being lost from simultaneous drive failures is greatly reduced, and the server operator does not need to be on-site to replace broken drives immediately; the server can continue to rebuild lost drives for as long as it stil has functioning spare drives. Also note that the parity drive may be placed under high strain under RAID 4. Every time a new bit is written, the parity bit must be recalculated: this can mean that the parity drive is written to several times more often than any other individual drive in the array, four times as much in our above example with five drives. To remedy this, two parity drives can be used with a slightly more complex recovery algorithm to share the load between them.
RAID 4 arrays are also easy to expand. Adding an empty drive to an existing RAID 4 array requires no change to the parity drive because the new drive is empty, and we know that:
0^X=X
- RAID 5 - Striped RAID. Similar to RAID 4, but instead of a dedicated drive, parity is spread across each drive, like so:
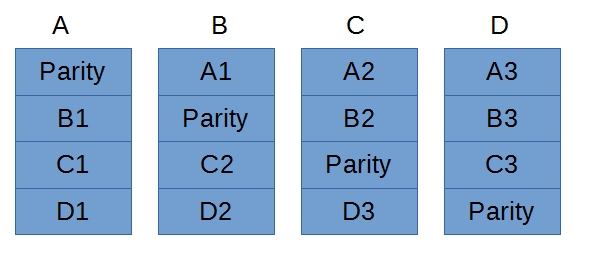
Parity bits are calculated from the other non-parity bits in the same fashion as RAID 4, but now the parity bits are spread across all the drives. This reduces the amount of load imposed on any one drive, which improves performance. RAID 5 is harder to expand than RAID 4 because parity bits are woven into each drive, and an expensive operation must be performed to extract and redistribute parity bits across new drives.
RAID can be implemented in either hardware or software. Hardware RAID has the benefit of being designed by the makers of the drive, which allow for very hardware-specific optimizations. On the other hand, physical RAID controllers can be expensive and only work with a certain brands of hard drive. In contrast, software RAID can be less efficient and low-level than hardware RAID, but is cheaper.
The following graph illustrates the reliability of data storage under different conditions:
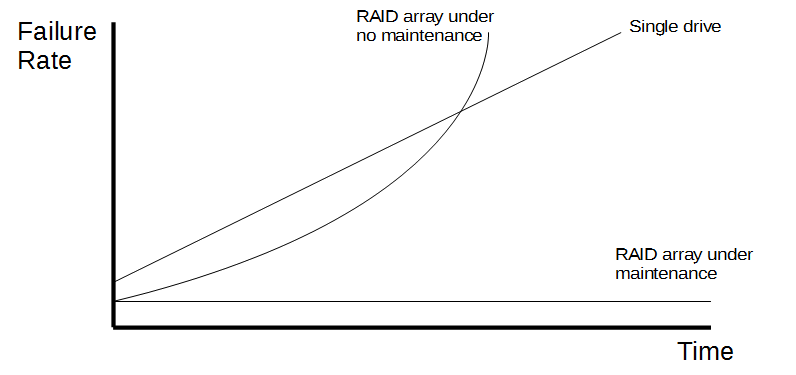
The above graph illustrates three cases:
- A single drive out-of-the-box is fairly reliable, but decays over time and the odds of mechanical failure increase the longer it is used.
- A well-maintained RAID array is more reliable than a single drive when first established as it has layers of redundancy to ensure that it does not lose data. It remains at a constant level of reliability over time as the operator replaces faulty drives regularly.
- An unmaintained RAID array, such as the memory on board a space rover, starts off as reliable as the maintained RAID array. It is more solid than a single drive up to a point due to its redundancy, but at a certain point the unmaintained RAID array becomes less stable than the single drive as multiple drives serve as multiple potential points of failure.
Potential Failures in Remote Procedure Calls (RPC)
Commands such as HTTP GET, which requests webpages, and X draw, which sends pixel draw requests to the X window manager, are remote procedure calls. They send a signal to an external server of some kind requesting that a task be done, and the server fulfills that request. Sometimes, the server fails to carry out a remote procedure call (RPC) and it can be for a few reasons:
- Messages can be lost in transmission
- The network can go down
- The server can go down or be unresponsive because of other priorities.
Errors from the above can manifest in a few ways. The call could time out without a reply, or hang forever. When this happens, a policy is needed for how to deal with no response.
Workarounds to Remote Procedure Call Failures
When a remote procedure call fails, a number of policies can be taken to remedy it. The simplest is to just resend the procedure call whenever it fails. Doing this indiscriminantly may result in unexpected behavior however; maintaining a strict policy for how to deal with errors can lead to better behavior for your specific application. For applications where duplicate messages are not backbreaking like a display server like X where it is fine to say that you want to draw a red pixel at a certain location twice, it is acceptable to resend whenever an error occurs. This is called at-least-once-RPC. In a bank, it is not acceptable to send a widthdrawal request twice, as a "failed" request could very well be caused by the bank server being slow, or the transaction confirmation being lost. In these cases, the at-most-once-RPC policy is employed, where you only ever send the procedure call once because you don't want to widthdraw twice as much from a user's bank account. Finally, there is exactly-once-RPC, for applications where it is essential that a procedure call is only ever called once. Exactly-once-RPC can be expensive to implement.
A couple of other measures can be taken to improve the efficiency of RPCs. A higher-level API can reduce the amount of calls required to perform a task. In the case of the X server, we can use calls to draw full windows and shapes instead of drawing pixels one-by-one. Programs can also use pipelining to improve the speed of RPCs. Instead of sending a call and waiting on a response, the client program can instead send multiple calls in quick succession for the server to work on at once. This improves efficiency as the client program doesn't need to waste time waiting for responses between each call, but the it must also be able to handle error messages from RPC that were sent several requests ago, which means it has to keep track of them somehow. A client program can also cache the server state, using what it knows about the calls it has already sent to build a local model of what is remotely stored so that the client can make calls ahead of time based on those assumptions. This is a gain in performance, but inconsistencies can arise between what the server remembers and what the client caches if another client program attempts to modify the same data, or the server performs hidden operations on data sent by the client. Caching the server state also requires much more complex client code.
NFS
NFS stands for Network File System. It is a system for treating remote servers as storage drives, so that administrators can back up a single server's worth of drives instead of having to maintain drives on hundreds of workstations in a building. To a local program, files on an NFS drive are accessed in the same way as on a regular UNIX file system. The program uses a file mounter to turn a regular file command such as open("/home/me/file", READONLY) and turns it into a form that the NFS server can recognise. The following are a few sample NFS calls:
lookup(dirfh, name) - The NFS server looks up the name of the file and returns the file header.
remove(dirfh, name) - The NFS server looks up the name of the file and deletes it, returning a success status.
create(dirfh, name, attr) - The server creates a file in the directory indicated by dirfh, with the attributes indicated by attr.
read(fh, offset, count) - Server finds the file indicated by fh (file header), starts at the specified offset within the file and reads off a number of bytes equal to count, returning the read data.
A more complete list can be found here. dirfh is the current working directory on the NFS server. The file header is composed of the filesystem number and the inode number appended to each other, and is used to identify files on the NFS server. NFS is a stateless server, which means that unlike UNIX, the server does not remember what directory you are in, it doesn't lock files and it doesn't keep track of things like the file pointer for clients. Instead, the client must keep track of everything. When a program runs open() on a file, it saves the returned file header locally and saves that as the file header for the file. NFS uses file headers instead of file names to reference files to avoid race conditions with multiple clients; consider the following:
Client 1: rename(foo, bar), rename(baz, foo)
Client 2: write(foo, buffer, n, data)
In the example above, client 1 renames file foo to bar, then renames file baz to foo. In the meantime, client 2 sends a request to write data to file foo. If NFS referred to files by their names, the write command would behave differently depending on how many of client 1's requests have already been processed. If client 1's first rename has not run yet, the write will go the the correct file. If the first rename has been executed, the write will go to an empty file and return an error. If both renames have already been processed, the write will write to the file formerly known as baz. Because of this, NFS uses numerical file headers based on inode numbers that do not change when the filenames change, so that if one client runs a rename operation on a file while another client is working on it, the second client does not accidentally destroy data or cause inconsistencies.