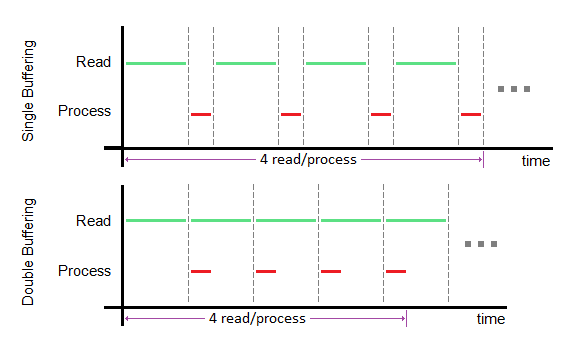
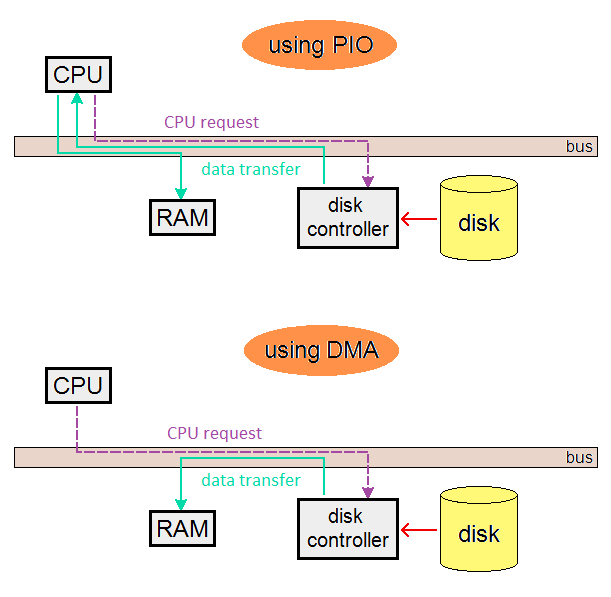
In order to measure the effectiveness of modularity on a system – or, in our case, a wc program – we define metrics to describe how well modular boundaries provide interaction between the environment and module itself (known as
abstraction
):
-
Performance: A downside of using modularity is that the inherent boundaries create overhead and latency due to call and ret commands. Also, modularity introduces “secrets”, meaning that modules do not know how other modules are implemented and cannot capitalize on more efficient methods.
-
Robustness: We can measure how robust a modular system is by observing whether failures are isolated to individual modules.
-
Lack of Assumptions / Flexibility / Neutrality: Describes how many constraints the system imposes on the user.
-
Simplicity: How easily can the user use and learn the system/program?
To demonstrate the effect of metrics on how we define our modular parts, let’s look at an integral function for the BIOS, the boot loader, and our wc program: read_ide_sector. Ideally, we would like to make one function to satisfy the needs of the all three programs. There are several approaches we can take to modularize the read_ide_sector function.
-
In the BIOS: By having the boot loader and the wc program call the read_ide_sector function in the BIOS, we make the BIOS the basis of developing the boot loader and the wc program. However, systems will to continue grow more complicated and demand different functionalities, thus requiring updates. These updates may necessitate adjustments to the read_ide_sector (or any other function that is called from BIOS), but it is very tedious to alter the BIOS on a frequent basis.
-
In the MBR (Master Boot Record): While placing the read_ide_sector in the MBR would allow for easier updates, it would be very limited to functionality because the MBR only have 512 bytes of memory.
-
In the kernel (software): By implementing the read_ide_sector function in the software, it overcomes the previous issues of updating and limited size.
-
Simplicity: How easily can the user use and learn the system/program?
Let’s take a look at how we can improve our implementation of this function.
The starting function takes two parameters – the sector number (int type) and the starting address (int type) of the buffer – and returns nothing (void type):
void read_ide_sector(int s, int a);
To improve, let’s allow the caller to specify the number of disks to read. Based on metrics, this would make the function (module) more complicated but also more flexible.
void read_sector(int disknum, int s, int a);
But, what happens if the read_sector fails to read properly? To solve this, we can have the function return an integer indicating how many sectors the function read, or a negative number to indicate it failed to read properly/anything. Also, let’s allow the caller to specify the number of sectors it wants to read from the disk.
int read_sector(int disknum, int s, int a, int nsecs);
Up to this point, we have been assuming the size of a sector. In order to be compatible with different disks, we should instead specify how many bytes we want from the disk. So, we change the sector number and number of sectors parameters into their byte counterparts.
int read_bytes(int disknum, int byteoffset, int a, int nbytes);
ssize_t read(int fd, void *a, size_t nbytes);
Comparing the read_bytes function to the read function (standard C function), we can see several similarities. Both function return signed integers meant to signify the number of bytes read (or to account for error). Parameter wise:
-
‘fd’ indicates file description and serves a similar purpose to ‘disknum’;
-
‘a’ is a pointer to a char buffer (cast as a void *) and is similar to the ‘a’ in read_bytes;
-
‘nbytes’ in both functions serve to state how many bytes are to be read in (though size_t describes the purpose of the parameter better since a number of bytes should be nonnegative)
However, the read function lacks a byteoffset parameter to describe where in the disk the function should begin reading. This indicates that the read function operates at a higher level of abstraction and already knows where in the file to read.