Scribe Notes for Lecture 4
Operating System Organization
Jan 15th, 2015
Scribe notes by Yueyang Mi and Ken Yan
Brief Review
The last lecture was about two ways to improve operating systems' performance: modularity and abstration. Simple ways of implementing modularity is discussed, and now we will talk about it in more details.
Modularity
Modularity breaks solutions down to smaller pieces and is a way to help OS Organization.
There are two main ways of implimenting it: hard and soft modularity
Soft Modularity
Modularize by functions
Hard Modularity
- Client-Server
- Virtualization
The last type of hard modularity, virtualization, is special as it "creates" multiple machines while keeping them firewalled off.
Virtualization
It is the simplest approach. (Like QEMU)
It involves writing a simulator of x86 (or whatever architecture needed) architecture
The simulator "clones" the x86 architecture, except that:
- It uses a subset of the real machine's memory
- It uses a safe subset of the real machine's instructions
- It has a set of new, higher level instructions
- it is SLOW, because it does hardware work with software
This process is so popular that there is hardware assistance for fast simulators.
The aforementioned "safe subset" is a subset where instructions that attempts to access the outside world, such as inb and half, is blocked
This is known as an "unprivileged" set
The other "unsafe subset" is the "privileged" set.
Like the instruction set, the hardware has a "privileged" or "unprivileged" mode.
In unprivileged mode, only the unprivileged set can be used; In privileged mode, both can be used.
By convention, if an application runs a certain privileged instruction, such as INT, it is treated as something else
How does this work?
If INT is executed in unprivileged mode, it'll trap.
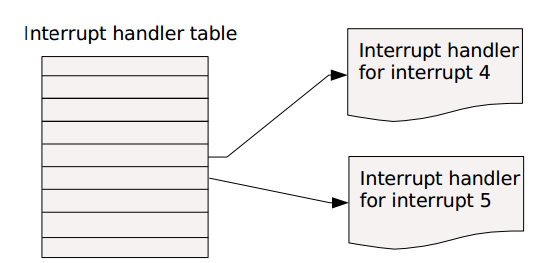
As seen in the image above, when the trap occurs, it'll jump the code to some interrupt handler which is in the kernel.
This allows functions to execute kernel code indirectly.
When executing such traps, the machine goes through an equivalent of the following assembly language:
1 push ss //stack segment
2 push esp //stack pointer
3 push eflags //is it privileged?
4 push cs //code segment
5 push eip //instruction pointer
6 ....
Notice that it pushes quite a lot of registers on the stack and tends to be slower compared to function calls
The linux convention in doing this is to put the syscall number in the %eax pointer,
and %ebx, %edx, %esi, %edi, %ebp as the arguments and using RETI, which is return interrupt
This convention is so popular that the recent versions of the linux kernel has the two new functions:
SYSENTER //sets cs, eip, ss, esp to values in machine-specific reister
(enters privileged mode)
SYSEXIT //does the reverse and exits privileged mode
An even faster way to do this is to use Virtual Dynamically Linked Shared Object (VDSO)
A VDSO is a shared library that allows application in user space to perform some kernel actions without as much overhead as a system call.
Multi-layer kernel
The hardware may be designed in multiple layers as the following.
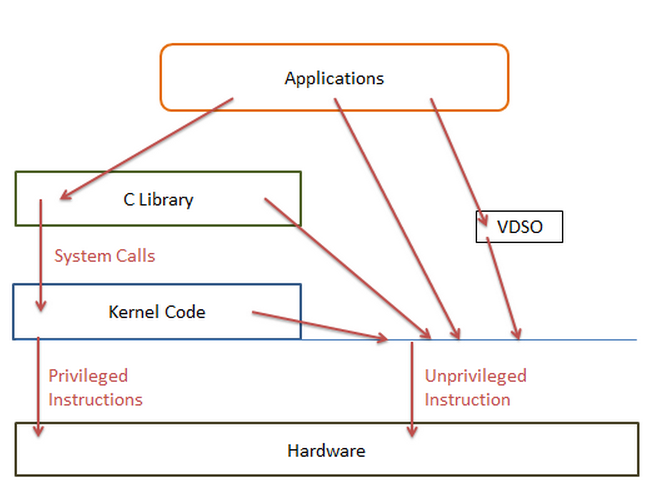
As seen in the image, applications can access privileged instructions via System calls
Multiple layers provides better modularity as each code in upper levels cannot mess with code in lower levels
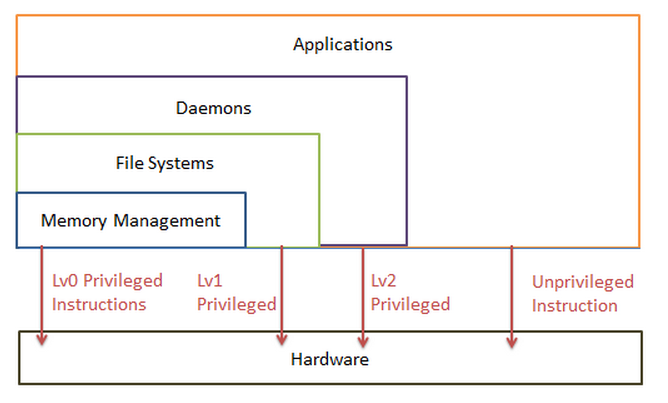
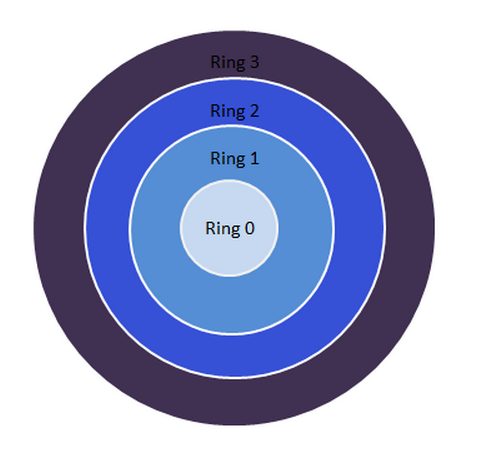
For x86 architecture, there are 4 levels of privilege, as the following "wedding cake"
It may also look like a multi-layered ring diagram
On the other hand, linux only has 2 layers. Why is that?
- More layers means less speed because applications need to pass through more layers to reach the privileged instructions
- Can't change memory directly in multilayers model
The tradeoff is that the user may easily delete important system files in Linux
Process: A program in execution on an isolated domain
pid_t, as defined in /usr/include/sys/types.h, shows:
typedef int pid_t;
The pid_t is an integer that numbers individual processes.
System Call 1: get process id
pid_t getpid (void); //returns the process id(pid) of the current processSystem Call 2: "clone" or fork processes
1 pid_t fork(void) //"clones" the current process
2 {
3 if in child process, return 0;
4 if in parent, return child_pid;
5 if on failure, return -1;
6 }
Playing with fork() ~
1 int main (void)
2 {
3 for (int i=0; i < 3; i++)
4 fork();
5 return 0;
6 }What would happen:
when i = 0, 1 process => 2 process
when i = 1, 2 process => 4 process
when i = 2, 4 process => 8 process
when i = 3, all process returns
The first three loops would look like the following.
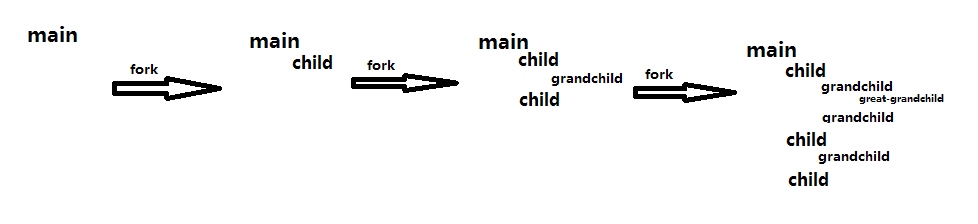
Fork Bomb
If an unusually high number of processes are created (say if we change the for loop above to for(int i=0; i < 1000;i++))
Then that would quickly overload most computers and is thus called a "fork bomb"
To prevent "fork bombing", normally there is a limit on the number of processes.
Child != Parent
While the child is pretty much a "clone" of the parent, it isn't exactly the same, in the following ways:
- They have different return values of fork(), pid, ppid (parent pid), and the file desciptor.
- The execution times are accumulated.
- Child does not inherit file locks from parent.
- Child does not inherit pending signals.
- Differnet file desciptor tables pointing to same stuff:
Child process doesn't have to run what its parent process runs.
System Call 3: Blow away existing program, sub in program fib
1 int execvp (char const *fib, char* const *argv)
//fib is pointer to new program, argv is pointer to arguement list
2 returns -1;
3 sets errno;
-This code does not make sense... What does "return -1" do?
-The reason is that if execvp succeeded, the code should never reach line 2. Reaching line 2 means that execvp failed.
System Call 4: kill the process gently...
1 void exit (int)
2 //clean up I/O buffer, then stop the processSystem Call 5: kill the process without mercy!
1 void _exit (int)
2 //simply kills the process, the int is exit status, 0~255System Call 6: How a process truly ends (Collect the body of the dead process)
1 pid_t waitpid (pid_t pid, int* status, int flags);
2 // parent calls waitpid, waits for child process.Note: A process can be: 1. runnable 2. waiting for waitpid to finish it
Example
Now, we want to implement the following "date" program.
1 $ date
2 Jan 15 2015
3 $ which date
4 /usr/bin/dateExample code of "printdate" using fork and execvp:
1 bool printdate (void){
2 pid_t p =fork();
3 if (p < 0) {return false;} //failed when forking
4 if (p==0) //if child
5 {
6 execvp("/usr/bin/date", (char* []) {"date", "-u", NULL});
7 exit(127);
8 }
9 int status;
10 if (waitpid(p, &status, 0) < 0)
11 {return false;}
12 return (WIFEXITED(status) && WEXITSTATUS(status)==0);
13 }Improvement: fork and execvp works better if combined:
int posix_spawnp(pid_t *restrict pid,
const char *restrict file,
const posix_spawn_file_actions_t *file_actions,
const posix_spawnattr_t *restrict attrp,
char *const argv[restrict],
char * const envp[restrict]); Note: restricted pointer prevents aliasing for the pointer.