Lecture 5: Orthogonality, Processes, and Pipes
CS 111 Winter 2015 Scribe Notes
Gloria ChanOrthogonality
As we are designing a system, we want to take into consideration the orthogonality of the design. That is, how well does the design support a separation of concerns and produce consistent results? How well does one part of a system stand up to a change in another part of the system?
Let's consider how we access files and also devices. We could implement it this way:| Access to files: | Access to devices: |
|---|---|
| open | connect |
| close | disconnect |
| read | send |
| write | receive |
But to make the API here simpler, let's just combine the two. We will treat devices as if they are files. This is the implementation Linux has chosen.
| Access to files and devices: |
|---|
| open |
| close |
| read |
| write |
Functions such as read or write, which we traditionally use with files, we will now also use to access devices.
- open("/dev/sd/O5", O_RDONLY) (reading data off a disk)
- open("/dev/tty/O7", O_RDONLY) (reading data off a serial port)
The command cp /dev/sd/01 /dev/sd/02 is valid because of our orthogonal design. Our design is what allows us to write generic code that could work for both files and devices. Yet, there are some flaws to this design, such as in security, where we may try to write to a network card and accidentally leak information. Also, say we are copying data from the keyboard into a file: cp /dev/tty/03 transcript. This could potentially run forever since there is no EOF.
Devices can be classfied into two types:| Network/Serial: | Storage Disk: |
|---|---|
| - Spontaneous data generation/ data comes in when it wants | - Data is requested and a response given immediately |
| - Stream of data | - Random access, when you want it |
| - Infinite data | - Finite data |
We must consider the usage of some different functions on these two types of devices. For example, read(fd, buf, size) may take a very long time to read from a device and could hang indefinitely. We would need to take this fact into consideration as we write our programs, and possibly redirect this command to execute in another thread. The function lseek(fd, offset, seektype), which repositions the offset of the file associated with the file descriptor fd, does not work on serial devices, where the data comes in a stream; it would fail and return -1. In this case, our design is lacking in orthogonality.
Processes
So far, we have looked at OS organization via virtualization. Our machine must have a CPU, with an ALU and registers, RAM/primary memory, and a bus of devices. We must also consider the dimension of time, in which we allow our machine to run.
Just as with files and devices, processes are another axis in our system for which we have functions such as fork, waitpid, and _exit that enable us to access processes. Each process has a process descriptor (for example, of size 8GB) inside RAM (see figure below), which contains a copy of registers, memory information (is a "copy", further explanation to be given in later lectures), and file descriptor entries(from 0 to 1023). The fd entries sector of the process descriptor that is associated to each process keeps track of a process's access of certain files. This is not to be confused with a table of file descriptions (found on disk), where actual permanent information pertaining to a file is stored.

Each time fork is called, this process descriptor is cloned. A change in the file descriptors of the child process will not affect those of the parent. For example, closing fd 1 in the child process does not close 1 in the parent process.
How to model OS resources in a program:
- A small int (eg. pid, fd number):
This int is considered to be a "handle" or opaque identifier. If someone simply refers to '39', you don't know what they're talking about unless given the context; it is the job of the OS to supply this context to us. - A pointer to an object representing the resource:
process *fork() would return a pointer to the process descriptor. With this method, more mistakes could be caught compared to using an int, where the int seems to be a lot more ambiguous.
- allows indirection, secrets can be kept by the kernel
- is more robust
typedef long pid_t; typedef int fd_t; pid_t p; fd_t f; p=f;
char c = getchar(); waitpid(c, ...);
If we had taken the pointer approach, it would have been harder for the OS to catch these mistakes.
Redirections and Pipes
Redirection: How would we implement this command: cat <a >b?
int status;
pid_t p = fork();
if (p == 0)
{
close(0);
close(1);
int afd = open("a", O_RDONLY);
int bfd = open("b", O_WRONLY, ...);
execlp("/bin/cat", (char *[]){"cat",0});
}
waitpid(p, &status, 0);
Pipes: How would we implement this command: du | sort -n? (This is a useful command which sorts files by their disk usage.) How about using a simple tmp file?
du >tmp sort -n <tmp rm tmp
The best option here is to use pipes. Pipes use the file API to read/write as a stream.
int pipe(int fd[2]) creates a pipe with fd[0] referring to the read end and fd[1] referring to the write end. Call close() on all the pipe ends to "destroy" the pipe.
pipe(fd);
dup2(fd[0], 0);
dup2(fd[1], 1);
fork();
fork();
execlp("du",...);
execlp("sort",...);
To go one step further, how would we implement du | sort -n | less? The solution would be to do it recursively.
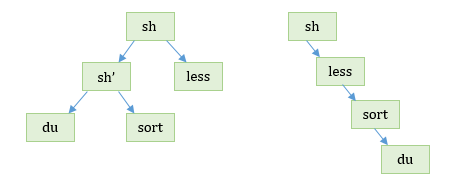
These two trees show two possible implementations. One way we don't want to implement this is with a tree of the form sh->du->sort->less because then the shell would have no way of knowing the exit status of less.
What can go wrong with pipes?
- Want to read, but the pipe is empty and writer never writes. Program will hang. Example:
int fd[2]; pipe(fd); char c; read(fd[0], &c, 1);
- Want to read, but pipe is empty and there are no writers. Read returns 0.
These first two situations look very similar, but the second situation is highly preferred over the first, since we can just do a simple error check with read's return value. It is easy to think you are in the second situation when you actually have the first situation. Let's say that the shell (parent process) calls pipe(), and then the shell forks twice, calls dup2(), etc. In this situation, the parent (shell) better remember to close the pipe. When working with pipes, you must make sure that only the ends you are working with are open and all other ends are closed.
- Want to write, but pipe is full and reader never reads. Program will hang.
- Want to write, but pipe is full and there are no readers. What happens?
- Write may continuously retry to write.
- Return -1 and set errno.
- Signal SIGPIPE and process automatically dies.
-