Lecture 5 - Orthogonality
by: Paul Eggert
January 21, 2015
Notes by: Mario Tinoco, Chris Orcutt, and Kaitlin Navarro
Eggert's Car
- Recently, Professor Eggert's car developed a problem, such that whenever he would turn the steering wheel - the air vents would blow hot air into his face
- This problem is an example of a failure in orthogonality
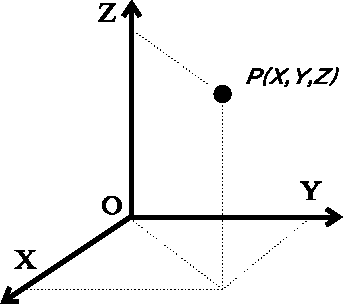
- Orthogonality as a system design property can be visualized through the mathematical representation of 3D space:
- Wherein we have the X, Y, and Z axes, at right angles of each other
- if we pick an X, Y, and Z value that results in a location P(X, Y, Z), point P will faithfully represent our choice in any one axis - without having to worry about our choice of the other two axes.
- In the case of Eggert's car, the steering system and the air system were failing to be orthogonal (independent), because his choice along one axis, was interfering with another.
File Orthogonality
- In the case of operating systems we have to worry about orthogonality even further, because an OS is very complex
- The problem is multiplied to hundreds of axis
- Proper orthogonality can help us in the design of the operating system because it supports separation of concerns: it allows us to understand parts of the system in isolation.
- If we are designing an OS, then there are several areas where we would want to use orthogonality.
- One of those areas is access to files
- The standard UNIX model is to have a small set of primitives that let you access the files:
- open, close, read, write, lseek, ...
- These primitives can be thought of as either one long axis, or in more detail: a series of axes.
- Additionally we will also want access to devices
- Devices tend to be more complicated because there is extra operations we can do, therefore it is tempting to design the OS with devices as a separate axis, with different primitives
- connect, disconnect, send, receive, ...
- However, Unix chose to make devices act like files, and use the same APIs to get at both files, and devices.
Because of the decision to make files and devices act similarly, we can do things such as:
open ("\dev\sd\os", ...); // reading disk directly
open ("\dev\tty\07", ...); // reading a serial port
// USB, Network Cads, Mouses, etc ...
- One benefit, is that it is simple, with only one API
- Utilities can work on devices as if they were files, because we have an orthogonal design.
An example problem, suppose you want to copy the bytes that you are reading of a serial port:
cp /dev/tty/03 transcript
- The problem with this command, is that it will never finish (No EOF)
- This is because in there are some differences between devices that we are ignoring
In general, we can categorize the reading of devices into two kinds
| Spontaneous data generation: data comes whenever it wants |
Request and Response: data comes when we ask for it |
| Stream of data: once the data is read, it is gone |
Random access: we can go back and read previous data |
| infinite: the data comes in as long as the device is there |
finite: there is a fixed length of data |
- We would like to have system calls that are orthogonal, and just-work - despite working on different device types.
- This means, that we need to develop with the understanding that
- a read : may hang for a long time
- an lseek : may fail on a serial device
Process Orthogonality
- Another area were we want orthogonality is with access to processes
- For UNIX, the standard primitives are: fork, waitpid, exit
- We will look at the case of an OS organized by virtualization.
- In order to decide how to design the virtual machines as orthogonally as possible, and efficiently as possible, we need to list the components of the machine:
| CPU - ALU |
High |
| CPU - Registers |
High |
| RAM - Primary Memory |
High |
| BUS - Devices (I/O) |
Low |
| Time |
|
- In order to accomplish this virtualization, each process will need access to an ALU, Register, etc..
- This is accomplished by providing each process with access to the real component for a time slice
- The time sharing will need to be modeled by having a process descriptor:
- While the process is not in its time slice, its process descriptor will store its state in RAM
| actual copy |
abstract description of the ram |
array of pointers providing indirect file access |
- File descriptors are done in two levels of indirection
- the process has pointers to file descriptor entries, which hold the state of the process's access to the file
- the file descriptor entries have pointers to file description objects, which hold the state of the file
- (on disk) holds file size, last access, ...
Representing Operating System Resources
When writing programs, oftentimes it is useful (or perhaps necessary) to begin new processes or manipulate files. The operating system is responsible for keeping track of these resources and must be able to uniquely identify each process, and each file available for manipulation within a particular process. Many operating system implement this resource tracking with either small integers or pointers.
Modeling via Small Integers
The operating system keeps track of resources via process IDs and file descriptors. Process IDs uniquely identify each running process on a system and file descriptors indicate which files a particular process may read or write.
Because the numbers assigned to each resource have no meaning without context, the operating system stores additional information which provides context for each number.
Advantages: Provides a level of indirection--the operating system stores the context of each number and can choose whether to provide the context of any number.
Disadvantages: Numbers can become easily confused and developers may make the mistake of using a process ID when they meant to use a file descriptor.
Modeling via Pointers
- The operating system will use pointers to process and file descriptor objects, which uniquely identifies each system resource.
Advantages: Harder to confuse distinct objects.
Disadvantages: Applications have direct access to the resources, no indirection.
The Unix Way
- Typically, UNIX utilizes the small integer approach. Although the small integer approach is less robust than the pointer approach, it is faster and has the benefit of providing a layer of indirection.
To create a new process, the fork() system call is used:
pid_t fork(void);
Note that pid_t is just a redefinition of a signed integer type.
- To obtain read or write access to a particular file, the
open() and close() system calls are used:
int open(const char *path, int oflag, ... );
int close(int fildes);
Note that the return types for open() and close() are both signed integers.
An Example: Fork, Open, and Close
Goal: To successfully run the following program in the shell.
cat < a > b
Solution 1
int afd = open("a", O_RDONLY);
int bfd = open("b", O_WRONLY());
execlp("/bin/cat", (char*[]){ "cat", 0 }
Problem:
execlp() replaces the current process with a new one- the above program would entirely replace the shell with the cat program--that's bad!
Solution 2
int afd = open("a", O_RDONLY);
int bfd = open("b", O_WRONLY());
int status;
pid_t p = fork();
if (p == 0) {
execlp("/bin/cat", (char*[]){ "cat", 0 }
}
waitpid(p, &status, 0);
Problem:
cat reads from stdin- we have opened the files
a and b, but we aren't reading or writing to them yet
Solution 3
close(0);
close(1);
int afd = open("a", O_RDONLY);
int bfd = open("b", O_WRONLY());
int status;
pid_t p = fork();
if (p == 0) {
execlp("/bin/cat", (char*[]){ "cat", 0 }
}
waitpid(p, &status, 0);
Problem:
stdin and stdout are now represented by a and b respectively, but we changed the file descriptors in the parent process as well!
Solution 4
int status;
pid_t p = fork();
if (p == 0) {
close(0);
close(1);
int afd = open("a", O_RDONLY);
int bfd = open("b", O_WRONLY());
execlp("/bin/cat", (char*[]){ "cat", 0 }
}
waitpid(p, &status, 0);
- This will create a new process, read from
a, write to b, and run the cat program, all without destroying the shell or altering the parent process--success!
Modeling Pipes
du -s | sort –n
- du:
- indicates how much disk space we are using
- prints out one line for each directory that is present as well as the number of blocks that particular directory is using
- sort:
- sorts the information given by du in ascending numerical order
This allow us to see where our biggest directory is and be able to clean it out when we run out room
How can we implement this?
internally:
//invoke du and output to a temporary file
$ du > tmp
//sort from that same temporary file
$ sort -n < tmp
//remove the temporary file
$ rm temp
So, the shell could implement:
du -s | sort -n
as if it were:
du > tmp
sort -n < tmp
rm temp
Although simple, there are problems with this implementation.
Potential Problems
- Requires lots of disk space!
- It's more than just an issue with space, it slows us down
- This is because we have to read to and write from disk memory (slow device access)
What if we arrange part of the memory to act like a file system?
- in main memory file system
- runs very fast!
- what if we put tmp in here to speed things up?
- Problems with this approach:
- can’t run the programs in parallel
- forces us to serialize our actions, but we want things to be run in parallel
- in the case of du -s | sort , sort can start all it’s thinking while du is running
How can we represent this approach orthogonally?
- du must write to file descriptor
1: write(1, …)
- sort will read from file descriptor
0 : read(0, …)
We want this communication mechanism between du and sort to still look like a file, with respect to read and write system calls.
Pipes
A pipe is an interprocess communication that looks like a file, but set it up like a device.
- It uses a file API to read and write and acts as a stream
- because it is a stream, lseek will not work
Need a new operator to create a pipe, since ordinary operators talk about file names (which pipes do not have)
Pipes are just bounded buffers in the kernel connecting process A to process B
- Within the pipe:
- When writing to a full pipe when nothing else is reading, then the pipe will hang
- This is like writing to a device that is not ready to accept data
- When reading from an empty pipe and there are no bytes to read, then the pipe will hang
- This is like reading from a serial port or network device and no packets are coming in
Modeling a pipe in the program:
int pipe(int fd[2]);
- This will create the pipe with:
- fd[0] as the read end
- fd[1] as the write end
To destroy a pipe:
close();
This closes all file descriptors so that the system can reclaim memory for later use
What can we do with a pipe?
$ du | sort
Dancing Pipes Problem This in effect will:
pipe(fd);
fork();
//second call to fork() prevents the shell from being replaced
fork();
execlp("du");
execlp(“sort”,”-n”);
//when we call pipe and fd[] is filled:
fd[0] = 12;
fd[1] = 14;
//copy the file descriptors
dup2(fd[0], 0);
dup2(fd[1], 1);
Now suppose we have more than one pipe:
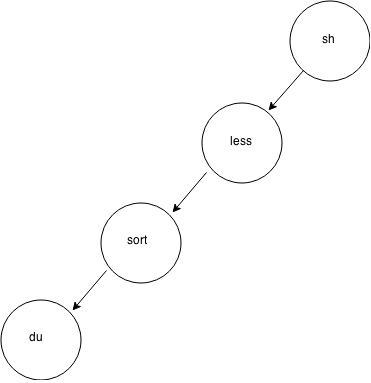
du | sort –n | less
- In this case, use recursion to your advantage.
We solved the first part of this pipe in the previous example, let's call it program A, so pipe this to less:
A | less
We can continue to do this and create as long of a pipeline as we wish
Let's take a look at the process tree:
- With pipes, we only care about the exit status of the last part of the pipe.
Problems with Pipes
Read Problems:
- Trying to read when the pipe is empty
- The pipe will hang waiting for the writer, that never writes (wait forever)
It's very easy to make this mistake! :
int fd[2];
pipe(fd);
read(fd[0], &c, 1);
- Trying to read when the pipe is empty, and there are no writers
- All the processes that once had write access to this pipe have closed their files descriptions or have exited
- This gets modeled orthogonally the same way that reading from a device or a file when there is no more data to read
- The read() system call will return 0 indicating there are no more bytes to be read
- Problem
This situation is very similar to the previous one, with one slight difference: the writers in this situation have gone, while those in example 1 have stuck around
- example
Suppose we have a shell where we wanted to implement the second example, but accidentally implemented the first
// parent calls pipe() -- didn’t close the pipe inside the
// parent (otherwise shell will count as writer to the
// pipe and reader from the pipe)
pipe(fd);
fork();
dup2();
close(fd[0]);
fork();
dup2[];
Both commands du and sort will run, du will finish, and sort will continue to read even though du has exited.
Problem:
- The parent shell called pipe(), but it didn't close the pipe inside the parent
- After the parent has done the forks, it needs to close the pipe. Otherwise, the shell itself will count as a writer to and reader from the pipe. Which leads us back to the problem in (1)
- Make sure that every pipe should have only the the ends that you want open and all other ends closed
ex
cat a&
cat b
- Where cat a will run in the background, calling fork() and exec(), but does not have a waitpid
- This means that the parent and the child are running at the same time and BOTH writing to stdout.
- Looking at the output file afterward, a's data and b's data will be intermingled depending on which process was able to do the write first.
Example
Now, consider the following:
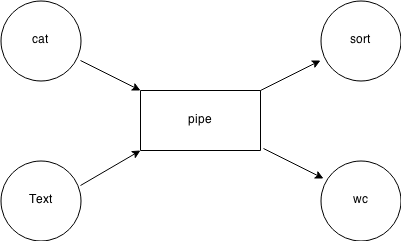
Multiple Readers and Multiple Writers
(cat a&
sed /x/y/ b) | sort
- Here, sort will see as its input the contents of processes a and b in parallel (intermixed)
- If a and b are on different disk devices, it could give us better performance by reading from both disks in parallel
Furthermore, if we want to really cause trouble, we could have (a very strange example):
(cat a&
sed /x/y/ b) | (sort &
wc)
- Here, we have created a single pipe with two processes writing to the pipe: cat and sed, and two processes reading from the pipe: sort and wc.
- Whenever sort and wc do a read, they will receive any data currently in the pipe
Write Problems:
- Attempt to write, but pipe is full and reader never reads
- In this case, we will hang as in the first case.
- Make sure that the pipe is accidentally closed when it should be open for reading.
- Attempt to write but pipe is full and there are no readers
If we apply process 4 to this, then write will return -1, causing printf to return a -1, meaning we will write forever chewing up CPU.
- So, instead of returning -1 and setting errno, send the program a signal called SIGPIPE
- SIGPIPE is like an asynchronous interrupt, which causes the process it is called on to die
Now:
while(something == true)
printf(“%d\n”, something_else());
du | less
//type q to exit
//du keeps writing
SIGPIPE
//du dies