Lecture 7: Scheduling Algorithms
by Guillaume Lam
Scheduling Threads
For cases where we have more CPUs than threads, scheduling is relatively simple. In the event that we have more threads than CPUs however, we have to determine how to manage the execution of threads. The reason for this is because when we have more threads than CPUs, we must determine how to allocate CPU time to each thread. We look for many characteristics when designing schedulers, such as fairness and efficiency, many of which will be covered in a later section. A general case for a scheduling with more threads than CPUs that could be written as:
To properly schedule threads, we need to account for the following:
- Policies: high level abstract rules
- Mechanisms: low level operations that the scheduler needs to work correctly
Policies and mechanisms are extremely important to scheduler design because they more or less determine all of a scheduler's behavior during runtime. In designing our policies and mechanisms for our scheduler, we should look to make the two categories orthogonal so that altering one will not affect the other.
Issues with Schedulers
Most problems that occur when designing schedulers fall into two categories: metric-based and scale-based:
- Metrics
- Speed: a well-designed scheduler will be fast
- Performance: we want our scheduler to execute with minimal problems
- Fairness: a good scheduler should allocate approximately equal amounts of time to each thread
- Scale
- Long Term:
- we worry that the scheduler will become overloaded with too many threads in the long term
- one solution is to simply limit which threads are admitted to the system initially
- Medium Term:
- to optimize the scheduler, we want to have a way of checking which process will be able to fit into RAM and load correctly at any instance
- this is to avoid thrashing, in which the scheduler copies process data from secondary memory but is unable to paste it into RAM due to the process not fitting into the available RAM
- we want to avoid thrashing so that we don't waste time copying process data between the system memory and the virtual memory without actually executing something
- Short Term:
- we need to decide how the scheduler should choose which threads to run
Policies
Policies can be complicated; there are cases in which we will want different policies for different process types. Implementing and managing all these policies adds complexity to the scheduler, and as a result we will want to limit variance in policies when possible. Demonstrating an real-world implementation of varying policies, SEASnet groups prioritizes difference metrics for different process types:
- System Processes (high priority)
- Interactive Processes: text editors, etc (good latency)
- Batch Processes: project grading, etc (good throughput)
One category of important policies is real-time scheduling. Assymmetric priorities in functionality per scheduler necessitate a thorough understanding and implementation of the specific type of realtime scheduling a scheduler will use. Overall, realtime scheduling can be separated into two general subcategories: hard realtime and soft realtime:
Hard Realtime
Hard realtime scheduling is used when meeting deadlines is imperative and missing them is possibly fatal. This type of scheduling favors predictablity over performance, often times striving towards simplicity in order to reduce the variance in results. An example would be disabling caches in order to not have to account for varying fetch times.
Soft Realtime
Whereas in hard realtime, all deadlines must be met, soft realtime scheduling handles deadlines more leniently as its name implies. Only most deadlines have to be met, and the few that are not met can be cast aside. An example would be a video player in which we occasionally see groups of pixels not loaded while the video plays. There are many possible algorithms for implementing soft realtime schduling, several of which are:
- First-Makeable Deadline: in which we meet the nearest possible deadline and cast away the unmakeable ones
- Priority-Based: in which the deadlines are met in order of relative importance to the program
- Rate-Monotonicity: in which we throttle CPU allocation for each process uniformly thus creating a "fairer" scheduler
Mechanisms
Ideally, switching between processes would be instantaneous and would look something like the following in the case that we only have one CPU:
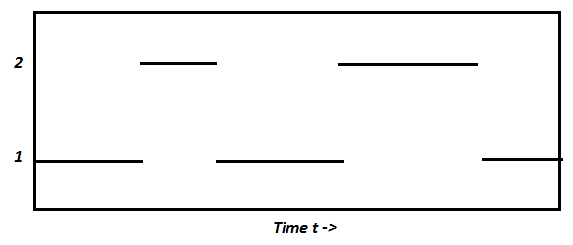
In the picture above, we can see the time spent on two processes running under one CPU. That being said, it does not account for one key element: the scheduler's transition time in between processes. To give control of the CPU to another process, the current process will first yield control of the CPU back to the scheduler. From there, the scheduler will determine the next runnable process and give it control of the CPU. The picture below shows a more accurate representation of process switching.
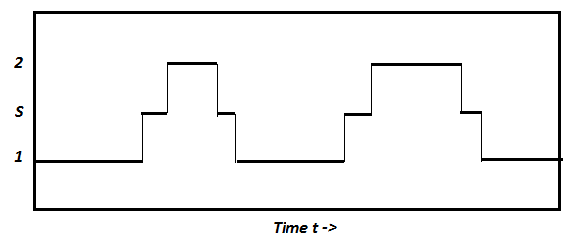
As we can see above, time is spent transitioning between processes, as represented by the thinner, vertical lines in the image. Transitioning between processes involves two main steps: process to scheduler and scheduler to process. In the picture above the transition from process 1 to process 2 is broken down into process 1 to scheduler S and scheduler S to process 2. Going from scheduler S to process 2 is easy, as it simply looks to run the next runnable process. Going from process 1 to scheduler S however is difficult in that we have to decide on how process 1 should give up control of the scheduler-if process 1 should give up control voluntarily or involuntarily.
Cooperative/Voluntary Multitasking & I/O
A simple way of implementing cooperative scheduling, or scheduling in which processes voluntarily give up control of the CPU, is to have certain places within a process that call the following function:
void yield(void)
When called within a process, this function essentially says "this is a good time to give up control of the CPU." Ideally, we would simply add yield()s all over a process's code, but that is not a very efficient manner of implementing cooperative scheduling. In Linux, every system call calls yield() before terminating, and because of this we do not need to ever have call yield in order to give up control of the CPU. A race condition occurs however in the event that no system call is ever made. As a result, the CPU being used within the code that does not contain a system call is never relinquished and the program running is forced to run with a reduced amount of CPU to allocate.
We have three plausible methods for tackling this issue:
- Busy Waiting:
while(isbusy(dev))
continue;
read(dev,...);
Busy waiting involves having a conditional statement that hangs indefinitely until the condition is satisfied. In the example above the condition is when a specific device is ready to be read from. Because busy waiting does not yield CPU control while waiting, it is considered unfair scheduling design. A potential problem is that the condition can hang indefinitely, and as a result the CPU that it controls will never be yielded to the scheduler.
- Polling:
while(isbusy(dev))
yield();
read(dev,...);
Polling involves yielding whenever it gets control of the CPU until its conditional statement is satisfied. The problem with this approach is that the scheduler will waste time scheduling the process while the conditional statement is not satisfied yet. This results in the process simply yielding without doing anything, and having multiple processes with this problem will sizably slow down execution time.
- Blocking:
while(isbusy(dev))
wait_for_ready(dev);
read(dev,...);
Blocking involves preventing the scheduler from scheduling a process with an indefinitely running condition until said condition has been satisfied. Blocked processes are stored in a part of the scheduler's process table and are associated with specific conditions so that when the conditions are satisfied the blocked processes can be scheduled again. Before scheduling the next process, the scheduler will look at the part of the process table that contains information on blocked processes. While scheduling, it will not try to run blocked processes, automatically skipping them.This solves the problem with polling where the scheduler wastes time by scheduling processes that only yield().
Uncooperative/Involuntary Scheduling
One way of having a process involuntarily give up control of the CPU is to use a timer. The motherboard will periodically send signals to the CPU and when the timer expires, it sends a signal to the CPU telling it to trap some kernel code. The process will then involuntarily call yield() and give up control of the CPU. In a sense, the process is automatically modified to call yield() every x seconds, normally 10 ms.
A problem with this is that we once again face the possibility of the process indefinitely running and taking up CPU. A solution to this is the SIGXCPU signal that is called just before the maximum CPU time limit is reached. The signal is preemptive in order to have enough CPU time to handle the signal. There is yet again another problem; the process could be in the middle of a critical command.
Scheduling Metrics
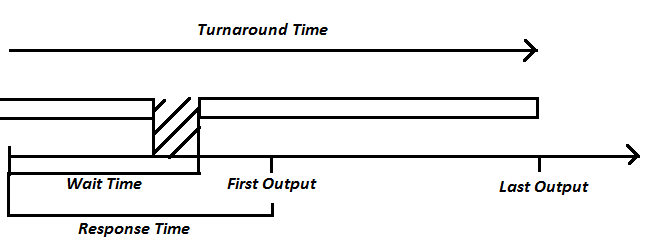
In order to assess and compare schedulers, we must be able to quantify performance results. The image above depicts several commonly used metrics:
- Wait Time: time between a command arriving and executing
- Response Time: time between a command arriving and its first output
- Turnaround Time: time between a command arriving and its last output
There are of course many other metrics that can be used such as:
- Average wait time over workload x
- Average response time over workload x
- Average turnaround time over workload x
- Variance/standard deviation of wait time
- Worst case wait time
- Utlization
- Throughput
Using Metrics to Compare Scheduling Algorithms
Supposed we have the following process batch to be completed:
| Job |
Arrival Time |
Run Time |
| A |
0 |
5 |
| B |
1 |
2 |
| C |
2 |
9 |
| D |
3 |
4 |
First Come First Served
In a First Come First Served scheduling policy, processes are executed in the order that they arrive in. Ideally, the wait times for this algorithm would be:
| Job |
Arrival Time |
Run Time |
Wait Time |
| A |
0 |
5 |
0 |
| B |
1 |
2 |
4 |
| C |
2 |
9 |
5 |
| D |
3 |
4 |
13 |
|
|
Average Run Time: 5 |
Average Wait Time: 5.5 |
We do not account for the time to switch between processes however, and in factoring the time t it takes to do so, we get the following:
| Job |
Arrival Time |
Run Time |
Wait Time |
| A |
0 |
5 |
0 |
| B |
1 |
2 |
4+t |
| C |
2 |
9 |
5+2t |
| D |
3 |
4 |
13+3t |
|
|
Average Run Time: 5 |
Average Wait Time: 5.5+1.5t |
Shortest Job First
In a Shortest Job First algorithm, we schedule the process with the shortest possible execution time to execute next. As a result, the processes A through D would be executed in the following order: A,B,D,C. Once again factoring in the time to switch between processes, we get the following results:
| Job |
Arrival Time |
Run Time |
Wait Time |
| A |
0 |
5 |
0 |
| B |
1 |
2 |
4+t |
| D |
3 |
4 |
4+2t |
| C |
2 |
9 |
9+3t |
|
|
Average Run Time: 5 |
Average Wait Time: 4.25+1.5t |
As we can see, the Shortest Job First algorithm has a much shorter average wait time compared to the First Come First Served algorithm. We would favor this algorithm in cases where we want a more consistent output stream. For batches where process order matters, we would use the First Come First Served algorithm.