Threads: like processes but share memory, field descriptors, ..etc. Downsides:
Apps get more complicated
Synchronization becomes a big deal
Scheduling Threads
Problem of scheduling (threads) is like any scheduling problem - nobody notices schedulers until they mess up.
So when writing an application, you either don't know the schedulers at all or you notice them when they mess up.
Let's take an example case:
Suppose the number of CPUs is equal to the number of threads.
There's nothing really wrong here because we now have one thread for every CPU. But, what do we do when we have more threads than CPUs? Which threads get to work?
So, we need two things:
Policies
The higher-level abstract rules that decide who's "stronger" between 2 classes/threads. e.g. like deciding which classes get the bigger rooms - you must arm wrestle for that room (policies).
Mechanisms
These are the low-level operations that a scheduler needs to do its work.
If done correctly, the policies and mechanisms are ORTHOGONAL (independent).
Issues
Application developers are always complaining why the schedulers are so bad,
so we must think about "metrics" for scheduler quality.
People who write our schedulers will listen to the metrics.
Metrics
Fast Scheduler: We want good performance, so we want a fast scheduler
Good Schedule: We want a good schedule; whatever threads get assigned to the CPU - we want them to be the right threads
High Performance Application: Having a good schedule while ensuring high performance.
Fairness: Making sure that everyone gets a turn and finishes. If lots of apps want to run, we want them to all get a fair share of the resources. More on this later.
Scale for CPU scheduling
Long-Term Schedule:Determines which threads are admitted into the system
We are worried about having our CPU overloaded (too many threads in the system) - how do we know
which threads/processes are admitted to the system in the first place? We address this by not letting bad threads into the system in the first place. In Linux, the fork() system call helps us manage this. e.g. fork() returns -1 to control longterm scheduling
Medium-Term Schedule:Determines which threads/processes fit into RAM(main memory) comfortably
What if we don't have enough memory? eg. We can run 10 processes, but we can't run 20 processes.
So here, we look at which threads/processes fit into RAM(main memory) comfortably while trying to avoid thrashing, i.e. constantly copying data from secondary memory to main memory.
If we're thrashing, we don't have enough time to really do anything.
Short-Term Schedule: Determines which thread, out of lots of easily runnable threads, will be running right now
Bunch of easily runnable threads/processes and enough memory;
however, we don't have enough CPU's. So, which ones will actually run?
The mechanisms for these issues are quite different, but what about the policies?
Policies
Policies can be complicated and processes can fall into different categories with different policies for each one.
For example, there are three types of processes on seasnet servers:
System (high priority, so schedule these first)
Interactive (good latency for logging like emacs)
Batch (good throughput, we want to grade as many programs in a given amount of time. don't really care about latency)
Real-Time Scheduling
Scheduling processes and threads involving real world interaction.
Hard real-time scheduling: (eg. controllers in Nuclear Power Plants, Automobile Brake Controllers)
You cannot miss the deadline. When you hit the big red button in a nuclear power plant, things must halt within a few milliseconds.
Predictability is key, performance is secondary. We don't care if its less efficient, we just want it to work.
Some implementations disable caches because they are not predictable enough since they can miss.
e.g. a real-time scheduler in a video game to arrange an explosion.
e.g. streaming video online.
Some possible algorithms
Earliest Makable Deadline First: Finds the task with the earliest deadline that you can make, and does that task, and moves all other tasks to the side. But what if we skip/lose an important task (like a key stroke in emacs)? Then we can use a soft realtime system with priorities!
Priorities: We designate tasks/applications with priority levels. What if there's still too much work to do?
Smallest Tasks First: Does smallest tasks first. Problem with the above two algorithms is that we may still miss important events. eg. In a game animation loop, a character triggers the "scared" state due to a bomb going off, but no bomb explosion images are seen because we processed the "scared" state and missed the explosions.
Rate-Monotonic Scheduling: If you have ten things needed to be done, but each is important, then slow everything down to fit.
Everybody loses a little bit (this is more fair than completely throwing something out).
eg. You see 80% of the explosions, 80% of the characters running around, so you get most of the feeling of the game, as opposed to missing out on either entirely.
Mechanisms
Let's assume we have:
1 CPU
n>1 Processes
(i.e. more processes than CPUs - although it doesn't matter if it's Processes or threads since we have to schedule both anyway)
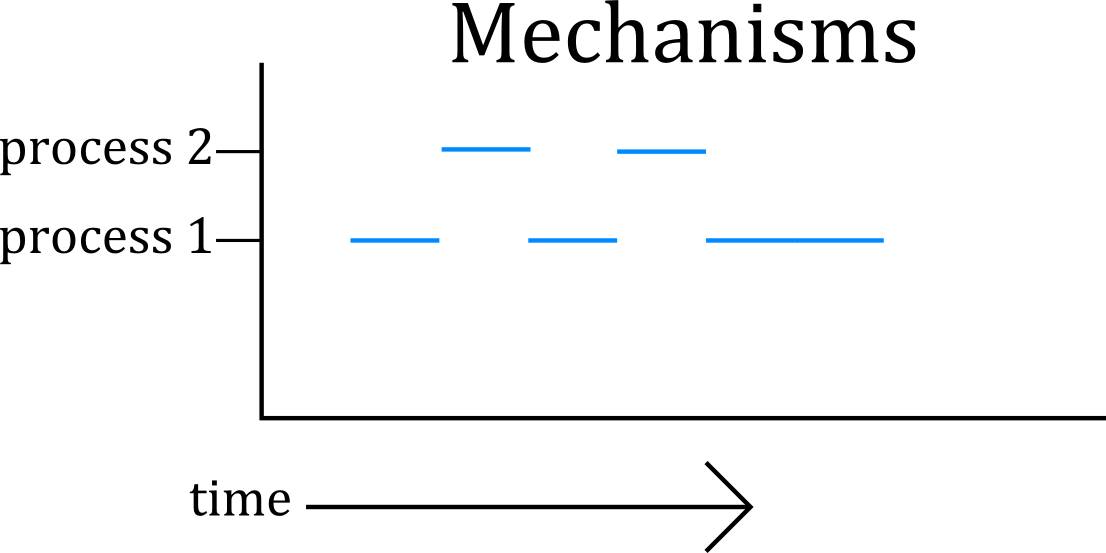
So in a graph against time, this is how the processes are executed:
Fig 1: Is this entirely accurate?
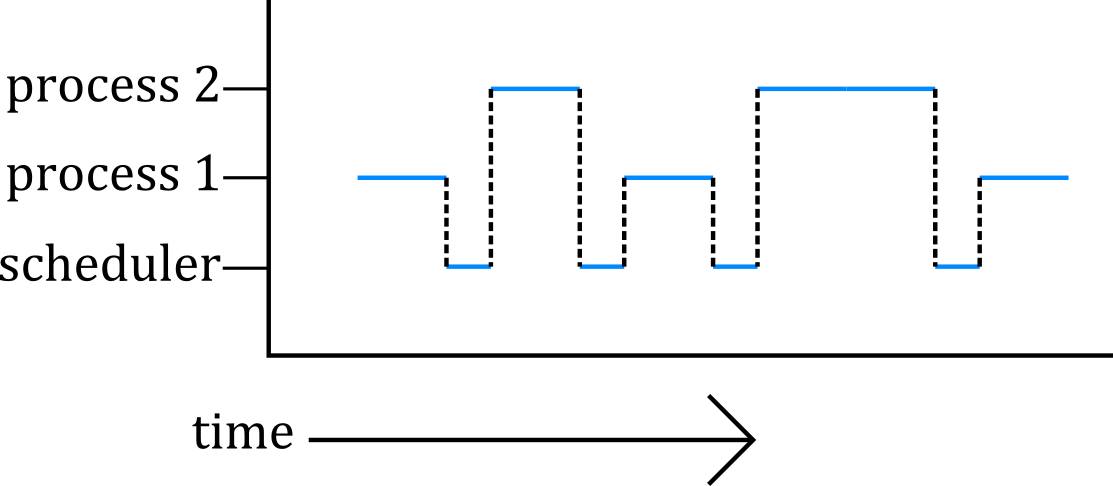
As we can see, this isn't entirely accurate because there is a third entity involved. In our Mechanism, who is in-charge of these transitions between Process A and Process B? There has to be some part of the CPU that actually does this - and the answer is the Scheduler.
Fig 2: The Scheduler decides who switches to who and handles this transition- producing (a little) overhead as a result.
Figure 2 is closer to the real world case, except that there is that each transition can take some time as the scheduler makes a decision, and so there is more of a gap between each cycle of Process 1 and Process 2.
So how does the Scheduler handle the transition?
For up transitions (from scheduler to process)
Scheduler can just resume the process (Linux on x86 can use the RTI, Return from Interrupt, instruction)
For down transitions (from process to scheduler)
This is harder than the up-transition, and so there are 2 types:
Voluntary Transition: Each process volunteers by calling the scheduler every now and then, and when it does call the scheduler it's prepared to give control away. It's prepared to deal with giving up the CPU.
So how do we do a voluntary transition?
We use: void yield(void) or void schedule(void) (the latter being preferred due to a more semantic name).
What these functions do (both do the same thing) is essentially give up control of the CPU for the current process. i.e. "This is a good time to give up CPU." So you'll look at your 10 million line C++ program and sprinkle the above function call at different, carefully chosen points.
That's not nice! So, instead of having to modify the original source code, we take advantage of the system calls (open, close, read, write) and have them call yield() since they drop into the kernel anyway. There's a catch: what happens if we have a loop in the program that is buggy? The system will then hang because the processor won't give up the CPU.
The solution of putting the yields inside the system calls is not enough. We need something better. We need something a little bit more involuntary.
Involuntary Transition: Even when the process doesn't want to give up the CPU, it has no choice. Therefore, in some sense, the kernel is always in charge. The process can lose the CPU at any time (well, if the process is in the middle of a particular instruction, it keeps the CPU until the end of that instruction).
Cooperative Scheduling/Multitasking
Busy Waiting holds onto the CPU/tie it up until we're not busy.
This approach isn't all that friendly in a cooperative multitasking system.
while(isbusy(dev))
continue;
read(dev,...);
Polling gives up control everytime the device is busy. Once it's not busy, we can read it.
This is a friendlier approach.
while (isbusy(dev))
yield();
read(dev..);
Problem: There are dozens/hundreds of processes, each waiting for its own device, each yielding and waiting.
The CPU will step through each one of these processes to check. This will take up a lot of time and resources as well. What we want is an approach where we don't run the process until it's done being busy.
Blocking doesn't bother yielding/scheduling until the device is actually available.
while(bus)
wait_for_ready(dev);
read(dev, ...);
For this to work, we need information about the device. One of the pieces of information is a list of processes that is 'blocked' (in the process table) or in the middle of a wait-for-ready call.
So, when the scheduler needs to think about what processes to run, it can ignore those in the blocked list.
An easy way to implement this is to have a column in the process table that holds the blocked processes. By blocking, we save the scheduler some time.
These processes are not nice, and don't always call yield.
Some techniques involved:
Timer Interrupt
The motherboard sends a signal to the CPU periodically.
This causes the CPU to trap - resulting in a switch to kernel mode, wherein the operating system performs some action before returning control back to the originating process.
It's like the program generated an INT 10, except it's the hardware doing the trapping via the interrupt service vector.
The hardware periodically calls yield for us. Therefore, we don't have to modify our program now since the hardware does it for us (typically) every 10ms(a value like 100ms would be too long for interactive stuff, while 10ms is too quick for anyone to notice the lag that arises from this interrupt.
In fact, there is NO yield() system call in Linux. We didn't solve the "halting problem" because we only suspended the process. It can still run forever.
SIGXCPU: We can put a limit on how much CPU time a process can get
If this process chews up more than the stated CPU time, then the SIGXCPU signal is sent to the process. This signal is typically sent when you could almost run out of time. eg. A process has 10 minutes of allotted CPU time but it's been running for 9 minutes and 55 seconds so the signal is sent. If we wanted to avoid this behavior: We could use the function : signal(SIGXCPU, SIG_IGN), which ignores the limit and keeps going.. but eventually the kernel will eventually stop anyway. THE BIG, BIG PROBLEM WITH PREEMPTIVE MULTITASKING:
What if the application is in the middle of doing something important?
Suppose 'gzip' is preempted! The files it was working on will then be left in an inconsistent state.
This is a problem for synchronization, which becomes very tricky here! But that's a topic for another day..
Scheduling Metrics
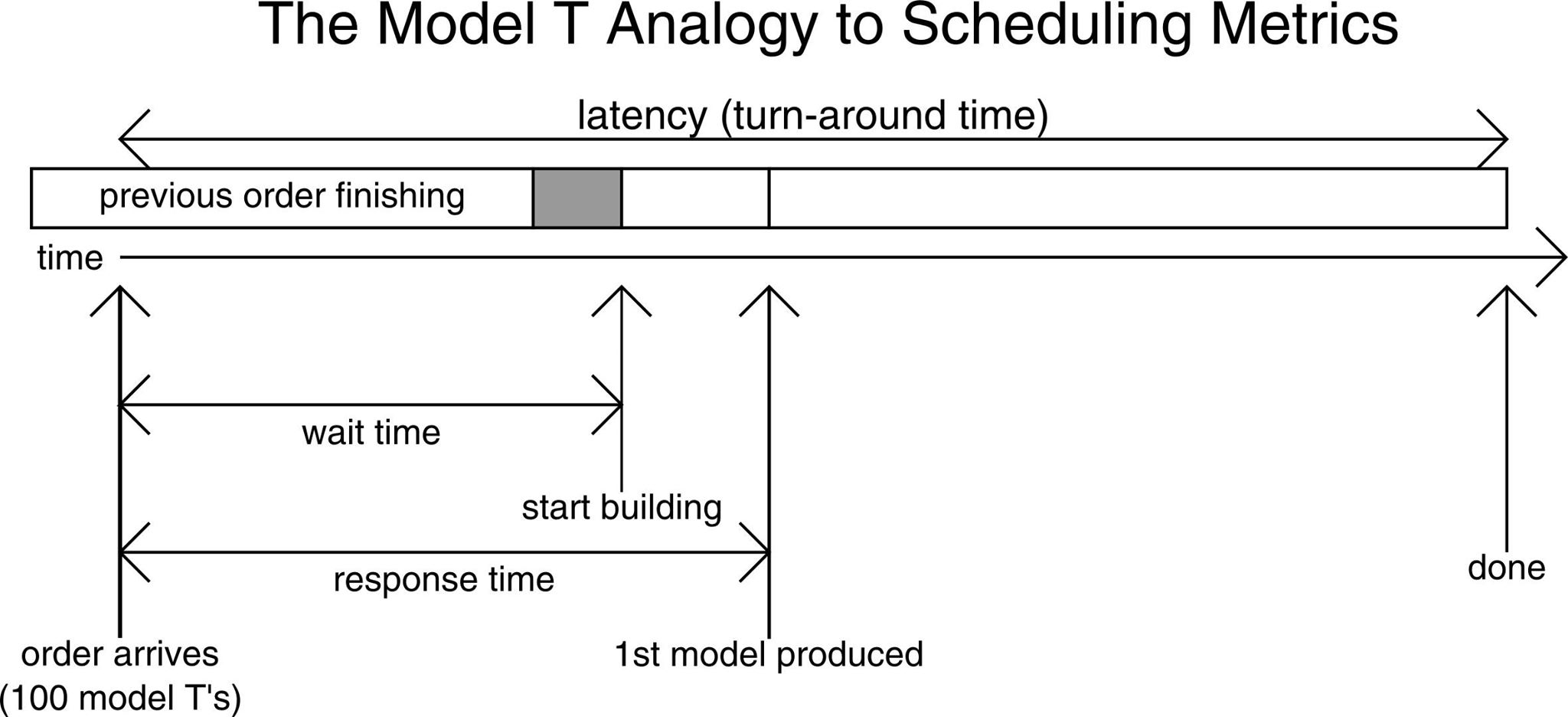
The metrics we're going to be using for scheduling.
Fig. 3: Using a factory analogy to understand what metrics we can use
These metrics are:
Latency: from time order arrives to time order is done (aka turn around time)
Wait time: time between order arrival and starting to build it.
Between a previous order and the start of building of the next order, there is some Wait Time to “retool the factory”.
Response time: time between order arrival and 1st model produced
Run time: time between the start of the building and the end/done
We can use these kinds of metrics in our system. We want to minimize all these times as much as possible.
We will, however, want fancier and more meaningful metrics, such as:
Average Times
Average Wait Time
Average Turn Around Time/Latency
..etc
Worst Case Times
Statistics
Variances and/or Standard Deviations of times such as Wait Time
Utilization: Percent of CPU doing useful work
Throughput: Number of jobs per second completed
So using these metrics, let's compare some scheduling algorithms to see which ones work better.
Comparing Scheduling Algorithms Using Scheduling Metrics
Let's say that we have the following processes to complete:
Process/Job
Arrival Time
Run Time
A
0
5
B
1
2
C
2
9
D
3
4
First Come First Served - FCFS Scheduler: Processes are executed in the order that they arrive
We can say, based on the definition, that the Arrival Time column here also acts as the Execution order (starting from 0).
So, the expected behavior is:
Process A arrives, we schedule A. We run it for 5 seconds (because it takes 5 seconds to run).
At t=5, we switch to B and run it for 2 seconds.
Then we run C for 9 seconds
Then we run D for 4 seconds
However, we also need to take into account the time taken by the Scheduler to transition between processes.
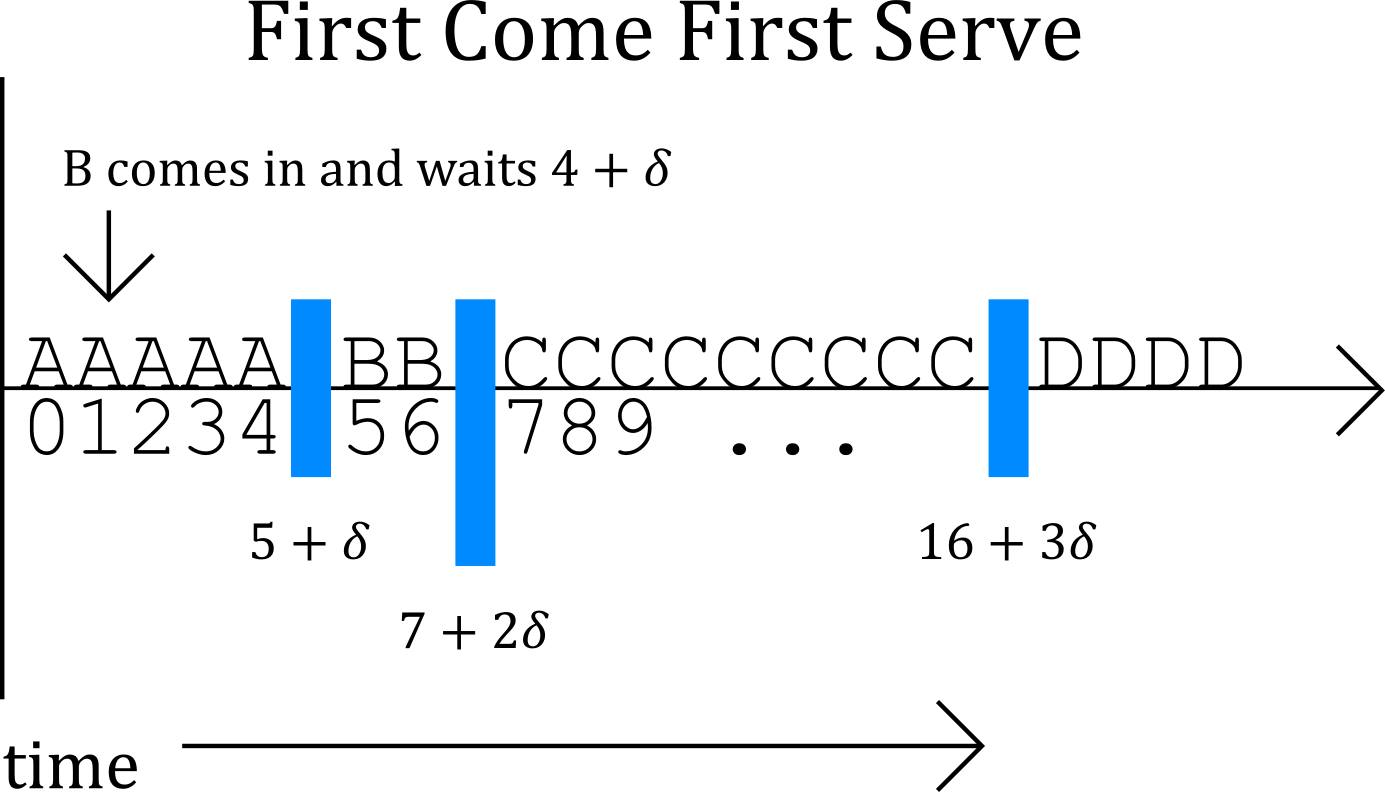
Fig. 4: First Come First Serve (FCFS) - with Time taken by Scheduler denoted as 'Δ' (the triangle symbol here is the same as the delta symbol used in the diagram)
What happens here is:
A starts at t=0.
B comes in and waits at t=1
C comes in and waits at t=2
D comes in and waits at t=3
A finishes at t=5 (its runtime was 5)
After we run A and before we run B, there’s some wait time 'Δ' for the transition to take place. So B doesn’t start at t=5, it starts at t=(5+Δ)
B finishes at t=7+Δ (total time so far includes the earlier wait time)
C starts at t=7+2Δ (assuming that the wait time will always be Δ)
C finishes at t=16+2Δ
D starts at t=16+3Δ
D finishes at t=20+3Δ
From this, we can calculate how long each process had to wait before it could be executed.
First Job First Served
Process/Job
Arrival Time
Run Time
Wait Time (FCFS)
A
0
5
0
B
1
2
4 + Δ
C
2
9
5 + 2Δ
D
3
4
13 + 3Δ
Before we make any conclusions here, let's take a look at another algorithm!
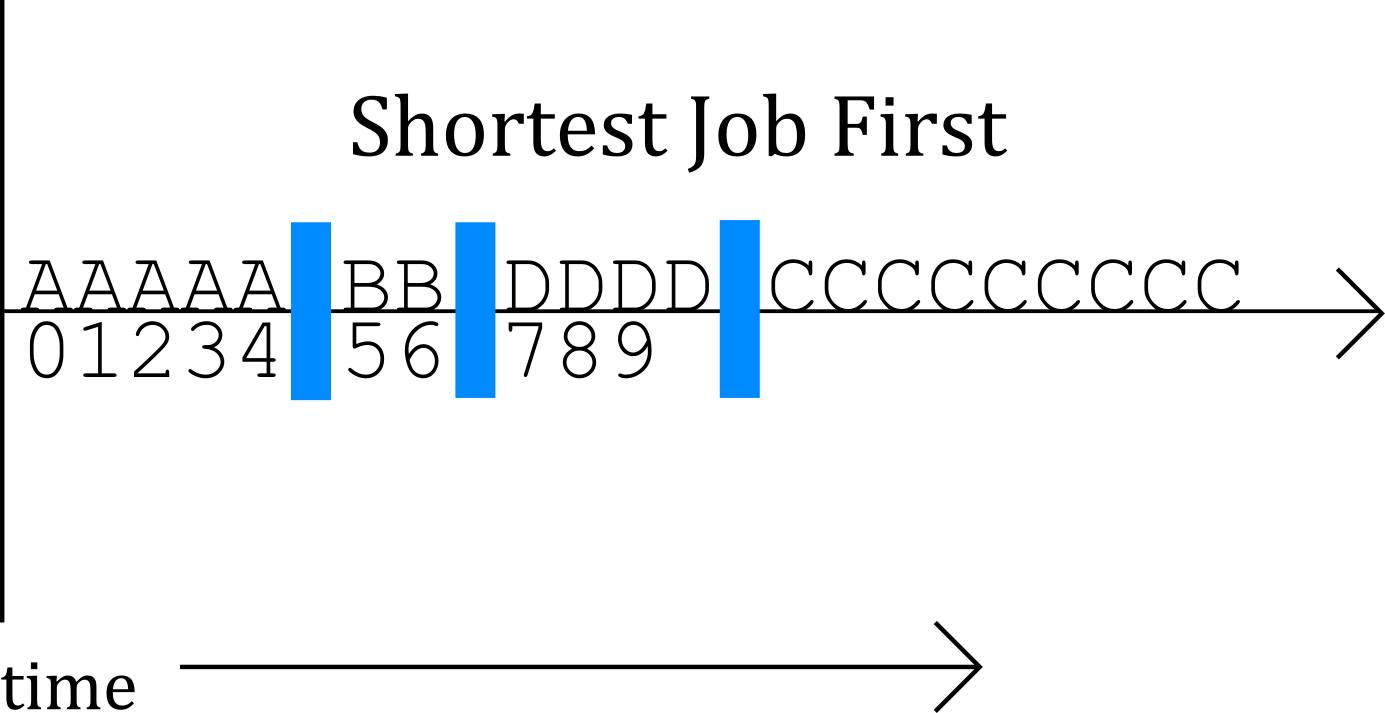
Shortest Job First - SJF Scheduler (or SJFS - First Served): Process execution order is based on how long a process takes to execute - with the shortest having the first priority.
Here we can say that the Run Time column acts as the Execution Order (in ascending order -> smallest first).
Fig. 4: Shortest Job First (SJF)
So what happens here:
A comes in at t=0 and starts
B(runtime=2) comes in at t=1 and will be the first process to execute after A
C(runtime=9) comes in at t=2 and, as its runtime is longer than B's runtime, it will be the second process to execute after A
D(runtime=4) comes in at t=3 and, as its runtime is longer than B's but shorter than C's, it will be the second process to execute after A.
C becomes the third process to execute after A. So execute order is now: ABDC
The rest can be calculated the same way as before
The resulting Wait Times will be:
Shortest Job First Served
Process/Job
Arrival Time
Run Time
Wait Time (SJF)
A
0
5
0
B
1
2
4 + Δ
C
2
9
9 + 2Δ
D
3
4
4 + 3Δ
Now let's put it all together and compare the two algorithms using some of our metrics.
Comparison With Metrics:
Comparing Scheduling Algorithms using Metrics
Job
Arrival Time
Run Time
Wait Time (FCFS)
Wait Time (SJF)
A
0
5
0
0
B
1
2
4 + Δ
4 + Δ
C
2
9
5 + 2Δ
9 + 2Δ
D
3
4
13 + 3Δ
4 + 3Δ
Average
don't care
5
5.5 + 1Δ
4.25 + 1.5Δ
Winner: Shortest Job First as it has a lower average wait time so overall it's a faster algorithm. So we should always use it and we're done... or are we? "But what's the catch?"
This algorithm will only work if we know ahead of time how long each job takes!
What if order of arrival matters to us? - then we'd simply use FCFS