UCLA CS 111 - Professor Eggert - Feb 2, 2015
Notes by Guanya Yang, Yu Xie
Consistency & Critical Sections
Preemptive Scheduling
Last time, we talked about scheduling policies like SJF (Shortest Job First) and FCFS (First Come First Serve). This time, let’s continue with preemptive scheduling, in which we break long jobs into series of shorter jobs. One type of preemptive scheduling is Round Robin (RR) Scheduling. In the following example, a possible implementation of RR is to split a long job into smaller jobs all of length less than 1.
Job | Arrival Time | Run Time | Wait Time |
A | 0 | 5 | 0 |
B | 1 | 2 | 𝛅 |
C | 2 | 9 | 2𝛅 |
D | 3 | 4 | 3𝛅 |
𝛅 = time for a context switch
We get this job sequence:
Pros and Cons
The downside to using RR is that it gives the CPU’s attention to different processes more often, resulting in more context switches. This reduces the overall throughput and utilization.
On the other hand, RR decreases the average wait time to 1.5𝛅, which is much better than SJF or FCFS.
There are two flavors of RR:
unfair RR - new arrivals go to the head of the run queue, so they basically cut in line; this causes earlier processes in the queue to starve
fair RR - new arrivals go to the tail of the run queue; there’s more waiting overall, but it’s spread out fairly and results in less starvation
Priority Scheduling
external priorities vs. internal priorities
(set by users) (set by the scheduler (the OS itself))
SJF, FCFS are both internal priorities, where SJF’s priority is the length of the job and FCFS’s priority is the arrival time. The priority of LJF (longest job first) would be the negative of the job length. We can even create a new policy called the “Eggert scheduling priority”, where the priority is the sum of the length of the job and the arrival time.
NOTE: A lower priority value refers to more important jobs. So a job with priority value of 1 would be more important than a job with priority value 5.
We can view the priorities of programs in Linux using the following command:
Priority (PRIO/PRI) is a function internal and external priority. An example of external priorities is the concept of niceness (NICE/NI). Niceness ranges from -19 (least nice and runs first) to 19 (most nice and runs last), where the default value is 0.
$nice make ← adds 5 to the niceness value
$nice -n9 make ← addes 9 to the niceness value
$nice -n-9 make ← subtracts 9 from the niceness value *
*this dangerous command can only be run by root, or else any user can allow a process to take over the system
However, with preemptive scheduling, we have two emerging problems. First, a lower-priority program could potentially be frozen and never run because higher-priority programs will always be run before it. Second, threads can lose their CPU at any time. These lead to the issue of synchronization.
Synchronization
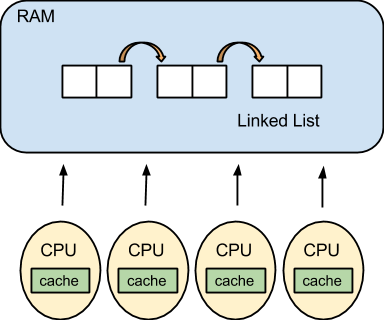
Synchronization is coordinating actions in a shared address space. For example, multiple CPUs may access the same data in RAM by manipulating the same linked list:
However, using a shared address spaces also introduces race conditions, when program behavior depends on the execution order of different threads. So one thread may change the structure of the linked list before another thread reads from the linked list. Fortunately, there are several different ways to prevent races from occurring.
Atomicity
Atomic actions are small, allowing for easier implementation (if they are small enough, the hardware can even do it). They are also indivisible, which means they cannot be broken down into smaller components. Atomic actions lead to more fair and efficient performance by decreasing the wait time.
There’s a danger, though, of “cheating” while implementing atomic actions. Take some bank account functions for example. We have an initial balance of $100 and three actions: A) deposit $10, B) withdraw $5, and C) look at balance. Thread 1 does A, thread 2 does B, and thread 3 does C. At the end, we should end up with a balance of $105. However, what happens if we peek at the balance between actions A and B? Maybe the bank balance will be $95 or even $85. It doesn’t matter to the bank, since all it needs to make sure is that the final balance is $105. The point is, the different threads can be performing other tasks during the series of actions and the combined result can be seen as a series of actions.
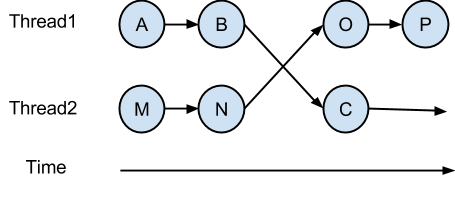
The coordination of action sequences is important because only certain sequences that are correct. The principle of serializability states that a sequence of actions is correct if every result is guaranteed to be one that could have been obtained from by some purely serial application of those same actions. Serializability is also special case of observability. If a sequence of actions are serializable, then the final state can be reached from different serializations. If we only observe the final state, then all serializations appear to be the same.
Explanation (sequence of actions): AMNBCOP
Critical Sections
Let’s take a closer look at the API behind deposit and withdraw:
bool deposit (long long pennies);
bool withdraw (long long pennies);
long long balance; bool deposit (long long pennies) { if (!(0 <= pennies && pennies <= LLONG_MAX - balance)) return 0; balance += pennies; return true; } bool withdraw (long long pennies) { if (!(0 <= pennies && pennies <= balance)) return 0; balance -= pennies; return true; } |
However, what if another thread withdraws from the balance before we can lower the balance in withdraw()? We can fix it by saving the balance in a local variable first:
bool withdraw (int pennies) { long long b = balance; if (!(0 <= pennies && pennies <= b)) return 0; balance = b - pennies; return true; } |
Unfortunately, we can still lose a deposit if another thread interrupts the running of the program before the line “balance = b - pennies.” We really want sections of the code to execute atomically without any interleaving functions of other threads. These highlighted sections are called critical sections.
A critical section is a set of instructions such that while your instruction pointer is executing that set, no other instruction is pointing at a critical section for the same object
A critical sections supports
Since mutual exclusivity and bounded wait have opposite requirements for the length of the critical section, we should adhere to the Goldilocks principle by making the length of our critical section “just right”.
Here’s another example of synchronization of threads in pipes:
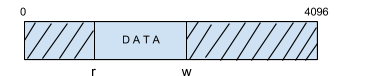
struct pipe{ char buf[PIPE_SIZE]; unsigned r,w; } char read(struct pipe *p){ return p->buf[p->r++]; } void write(struct pipe *p, char c){ p->buf[p->w++ % PIPE_SIZ] = c; } |
One problem here is if there is no data in the pipe, the function read will not return any data until something is written into the pipe. Therefore, we can change the data in the following way:
struct pipe{ char buf[PIPE_SIZE]; unsigned r,w; } char read(struct pipe *p){ while(p->r == p->w) continue; return p->buf[p->r++]; } void write(struct pipe *p, char c){ while(p->r == p->w) continue; p->buf[p->w++ % PIPE_SIZ] = c; } |
To solve the synchronization problem, we introduce a lock:
lock_t = alock; void lock(lock_t *); // can busy-wait while some other thread owns the lock // pre-condition: this thread doesn’t own the lock // post-condition: this thread owns the lock void unlock(lock_t *); // no waiting |
Now code becomes
lock_t = l; char read(struct pipe *p){ char c; lock(&l); while (p->w - p->r == PIPE_SIZE) continue; c = p->buf[p->r++ % PIPE_SIZE]; unlock(&l); return c; } void write(struct pipe *p, char c){ lock(&l); while(p->r == p->w) continue; p->buf[p->w++ % PIPE_SIZ] = c; unlock(&l); } |
The problem here is that when there is no available data in the pipe, the reader doesn't let go of the lock to allow other writers to write into the pipe, making the writers starve.
So to fix this problem, we have the following code:
lock_t = l; char read(struct pipe *p){ char c; lock(&l); while (p->w - p->r == PIPE_SIZE){ unlock(&l); lock(&l); } c = p->buf[p->r++ % PIPE_SIZE]; unlock(&l); return c; } void write(struct pipe *p, char c){ lock(&l); while(p->r == p->w) continue; p->buf[p->w++ % PIPE_SIZ] = c; unlock(&l); } |
This code is still subject to the two following problems:
Problem I:
Now that we’ve added locks to the code, we are safer, but things are more unfair. We’ve made critical sections too large, so we got a spinlock. Effectively, we keep spinning in the while loop as we repeatedly check if the lock is available.
Problem II:
Our lock is too coarse-grained, meaning it excludes access to parts of the code that aren’t a problem for synchronization. Let’s look at a simple example of two pipes:
A | B (pipe P) and C | D (pipe Q)
We have a single lock for all locks of both pipe P and Q, which doesn’t scale if we increase the number of pipes. Instead, we should make the lock finer-grained by having a lock per pipe rather than one lock for the entire program. If we have one lock for pipe P and one for pipe Q we can have them run in parallel.
Fine-grained locking is more fair and allows for parallelism, but also requires more memory and is more complex. We can make the example program extremely fine-grained by having both a read lock (rl) and a write lock (wl):
struct pipe { lock_t rl, wl; char buf[PIPE_SIZE]; unsigned r, w; } bool isempty(struct pipe *p){ lock(&p->rl); bool ise = p->r == p->w; unlock(&p->rl); return ise; } |
This code is too slow. Can we arrange to have all threads read the pipe but only one thread write at a time? To be continued next time...