1. First Look: Critical Sections in a Simple Environment
How would one implement critical sections given the following assumptions?
There is only one, unique processor.
The application will run in a system with no interrupts (e.g. there is no preemptive multitasking, etc...).
Note: This is about as simple as it gets when dealing with synchronization.
This is essentially a trick question. Given this scenario, locking and unlocking sections of the code is unnecessary
because if there is only one CPU and there are no interrupts, a running process cannot have its control over the CPU
taken away from it by another process. Therefore, a process can safely run critical section code.
So at a low level, lock() and unlock() would be implemented by no-ops.
2. Second Look: Critical Sections with Interrupts
Without the second assumption from the previous section, it is still fairly easy to implement
lock() and unlock(). Suppose Machine A
is about to do the following operation: (1+2). Meanwhile Machine B is about to do
the following operation: (1-3). Also, assume that there is a way to make interrupts go into a pending state.
Given this new set of assumptions:
At a low level, lock() would be implemented by the instruction:
splx(6); // SPL stands for Set Priority Level
The above code sets the process level register to 6, which means that the process won't get an
interrupt unless the interrupt is priority level 6 or greater. This makes the process less interruptible.
At a low level, unlock() would be implemented by the instruction:
splx(4);
The above code sets the process level register to 4, which means that interrupts of level 4 or greater
will be recognized by the process. This makes the process more interruptible.
This works well for a single processor environment, but most
modern CPUs have multiple processors.
3. Third Look: Critical Sections with Interrupts in a Multiprocessor Environment
Given that the earlier assumptions are removed, consider Machine C, a multiprocessor machine
running in an environment where interrupts are possible.
Consider this first attempt at an implementation of lock()
and unlock() under this new paradigm:
typedef int lock_t;
void lock(lock_t *lock)
{
while (*lock)
continue;
*lock = 1;
}
There are a few problems with this implementation:
The while loop and the assignment in the code above are not guaranteed to be atomic. A different process
can claim the lock as the current process goes into the assignment instruction.
When reading in the value stored at *lock while running the
while (*lock) instruction, the process could read a value that was never
actually stored at lock. For example, suppose you have a 16-bit bus on
a machine with 32-bit integer representation. Half of the integer will get read in and transferred through
the bus, but before the next half of the integer gets read in, another process may change the value of the
lock. This will load a different upper-half of the integer. As a result,
*lock does not evaluate to 0 or 1, but some garbage integer
(this is even more likely with larger number representations such as
long long types).
This implementation also assumes that loads and stores are atomic on modern machines.
How would one solve these issues (in particular, the second issue)?
II. Atomicity in Loads and Stores
On an x86 machine, watch out for:
Reading data that is larger than 4 bytes. Take the 16-bit bus machine and 32-bit integer type example above, but
with the x86's 32-bit bus and a 64-bit long long type instead. Half of the
long long will get read in one at a time (since the bus can only handle
32 bits) when doing load/store instructions, and as one thread loads/stores the
long long, another thread might modify part of that
long long before the initial thread has a chance to complete its second
load/store. When the first thread finishes, it modifies a garbage value, leading to inconsistent data.
... To preserve atomicity, data must not be too large.
Unaligned data access. Take a union A declared as the following:
union A
{
int a[2];
char c[8];
} u;
The following code would represent a critical section with respect to the union, but
with a possible problem:
// Section 1
u.c[0] = 'e';
u.c[1] = 'f';
char *p = &u.c[0];
p++;
... // Section 2
u.a[0] = 12;
u.a[1] = 97;
... // Section 3
int *q = (int *) p; // *q equals 97<<24, but is that what we want?
Given two threads Thread A and Thread B, where Thread A modifies
u as u.a and Thread B
modifies u as u.b, what happens
if Thread A and Thread B execute at the same time? Regarding the above code, what if
Thread B wanted to find u.c[1]'s ASCII integer code and
executed code in Section 3, but Thread A concurrently executed code from Section 2?
Thread B, if it does not execute fast enough, might end up with *q
as 97<<24, instead of 'f' as stored in section 1 (though not robust, this example shows the problem of
unaligned assignment).
... To preserve atomicity, data must be properly aligned.
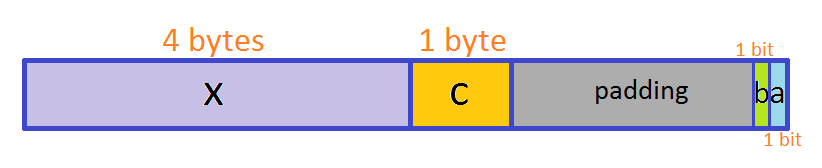
Accessing data smaller than 4 bytes. Take, for example, a struct like the following:
struct A
{
bool a:1;
bool b:1;
char c;
int x;
} s;
given that struct A has the following alignment in memory in a little endian machine:
Figure 1 - Data alignment of struct A in memory.
If two different threads manipulated this data in some way, they could work against each other.
For example, suppose that there two threads. Thread 1 runs the following line of code:
// Thread 1
s.a = 1;
Then Thread 2 runs the following line of code:
// Thread 2
s.b =1;
In the previous lines of code, Thread 1 modifies s.a
and Thread 2 modifies s.b. At a low level, either thread
takes the entire 4-byte memory segment, changes s.a or
s.b, and places the memory segment back in memory.
This presents a problem: what if both threads each handle load/store operations?
Say Thread 1 aims to modify s.a and Thread 2 aims to modify
s.b. Thread 1 loads the 4-byte word containing
s.a and s.b, modifies
s.a, then stores the 4-byte word back into memory. Before Thread 1
finishes, Thread 2 does the same for s.b. But Thread 2
contains old data for s.a since it starts before Thread 1
finishes and stores new data to s.a. Thread 2 then finishes
and stores the old s.a and a new s.b.
Thread 1's changes are lost.
... To preserve atomicity, data must not be too small.
To summarize, when dealing with multiple CPUs accessing the same memory, always assume the worst:
It is not going to work!
What will work, then?
. . .
Atomicity and x86 Machines
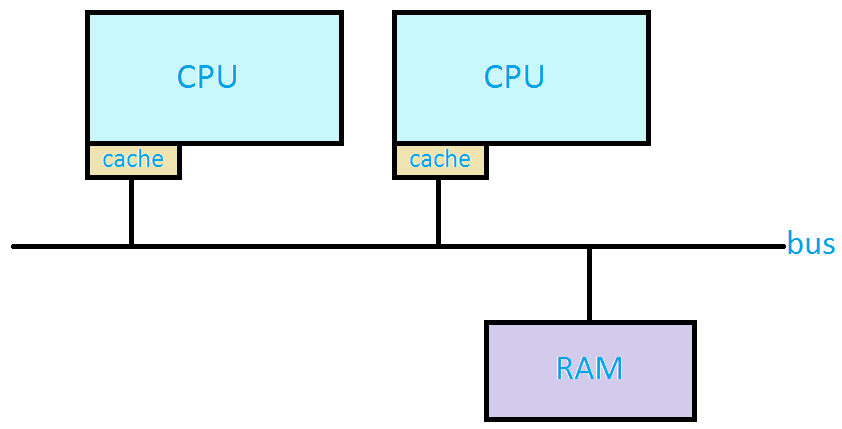
Consider this! In most modern multicore machines, such as the x86, one CPU, say CPU0, can snoop data going
across the bus to another CPU, say CPU1, to see and compare data in CPU0's cache. CPU0 might
snoop data going to CPU1, find matches in its own cache and realize that the matched data are incorrect
because they belong to CPU1, and go and re-correct them. The figure below
lends a visual perspective to the CPU/bus configuration described in this paragraph.
Figure 2 - Two CPUs connected to RAM through a bus.
All this information guarantees that x86 aligned loads and stores of int (32-bit quantities) are atomic.
With this information, how do we implement lock() and
unlock()?
unlock() could be done in the following way:
void unlock(lock_t * lock)
{
*lock = 0;
}
lock() will be a bit more difficult.
On a first attempt, it seems that something like this would work:
void lock(lock_t * lock)
{
while (*lock++ != 0)
continue;
}
But it actually would not work. *load++ involves the load, add, and store
instructions, so it is not really atomic. Even when reduced to an instruction that appears atomic, such as
incl(), it is still not atomic. It gets broken down in the microcode as the load,
add, and store instructions individually, making it not atomic relative to all the other microcode.
Are there ways of making a locking mechanism even without atomic loads and stores for writing and
reading from memory?
There actually are. There exist algorithms that work even when loads and stores are not atomic. In fact,
Leslie Lamport, Turing award winner,
came up with a way to do this. Unfortunately, the algorithm is so complicated and slow that it
took a Turing award winner to figure it out.
. . .
x86 and its Special Atomic Instructions
This problem is so difficult that software makers have had to work with hardware makers to solve this.
("So how do you solve this problem? You call the hardware guys!" - Eggert 2015)
This resulted in the creation of special atomic instructions on the x86 (Intel has developed quite a menagerie of
atomic instructions because they serviced so many requests). Here are two of them:
lock incl x is guaranteed to increment variable x atomically, provided
that it is aligned. It does this by telling the CPUs that there is a locked instruction going through. All the
other CPUs stay away from the word that is locked. Then, when the command is finished, all other CPUs are notified.
They can then access the locked memory again. All of this takes about 100-200 cycles, which is a lot slower than a
regular incl. The prototype for the C function is: void lock_incl(int *).
The function can be incorporated into an implementation for spinlocks:
void lock(lock_t *lock)
{
while (true)
{
int x = *lock;
lock_incl(&lock);
if (x == 0)
break;
}
}
}
Unfortunately, the code does not work because a different process could change
x in between the read and the lock incl instruction.
xchgl() atomically exchanges data between memory and registers.
At a high level, xchgl() does the following work, represented below in C code.
int xchgl(int *p, int new)
{
int old = *p;
*p = new;
return old;
}
This is all done in one instruction, just like lock_incl(). It is atomic.
Given this new instruction, lock() and unlock() could be implemented in the following way:
void lock(lock_t * lock)
{
while (xchgl(lock,1))
continue;
}
void unlock(lock_t *lock)
{
while (xchgl(lock,0))
continue;
}
However, there must be preconditions met for these implementations to work correctly.
The caller must not own the lock prior to calling the lock(),
or else the caller will deadlock.
It is also the caller's responsibility to own the lock prior to calling unlock().
Otherwise, the caller could potentially unlock a critical section currently being executed by
another process, possibly resulting in processes having access to that critical section
at the same time. Thus, race conditions would be rampant.
However, with these preconditions, it must be the case that whenever unlock()
is called, the calling process owns the lock. Therefore, the code for unlock()
can be reduced in the following way:
void unlock(lock_t *lock)
{
*lock = 0;
}
III. Synchronization
The goal of implementing locks is to build atomic actions by locking parts of the code. These
critical sections, sections where only one process should be manipulating the global state
at a time, need to be of approximately the right size. This way processes can synchronize
and avoid overwriting the work that they do. Going back to the example involving banks and accounts,
locks can be used in the implementation of the deposit() and
withdraw() functions.
Back to the Bank
Here is withdraw() without locking:
int balance;
...
bool withdraw(int w)
{
if (balance < w || w < 0)
return false;
else
balance -= w;
}
This non-thread-safe code can be made thread-safe by adding locks:
int balance;
lock_t ballock;
...
bool withdraw(int w)
{
lock(&ballock);
bool ok = (0 <= w && w <= balance);
if (ok)
balance -= w;
unlock(&ballock);
return ok;
}
There is a dilemma with this implementation. High performance is desired and shrinking down the
critical section as much as possible would improve performance (because a larger critical section means a larger
amount of resources get put on hold). However, the critical section in the above code
involves the computation of the balance. How can performance be improved while preserving atomicity?
This problem occurs often enough that Intel had to make another instruction at the request of software developers.
If the instruction were to be represented by C code, it would look like:
bool compare_and_swap(int *p, int old, int new)
{
if (*p == old) // Check to see if the old value is what the caller thinks it was
{
*p = new; // Set to new
return 1;
}
return 0; // Otherwise return false and don't do the swap
}
Now, assuming that this is an atomic operation, withdraw() can be
improved as follows:
int balance;
lock_t ballock;
bool withdraw(int w)
{
while ( !compare_and_swap(&balance, balance, balance - w) )
continue;
return 1;
}
With even more improvements, withdraw() is better as:
bool withdraw(int w)
{
while (true)
{
int b = balance;
if (w < 0 || b < w)
return false;
if ( compare_and_swap(&balance, b, b - w) )
break;
}
return 1;
}
This way the critical section gets broken down to one line without lock() and
unlock(). It has nicer performance (fewer bottle necks), but if there is
contention the computational part can chew up the CPU. Another downside is that this assumes that the entire state
that the programmer cares about fits into a four byte space, because only four bytes can be updated at a time using
compare_and_swap.
. . .
Synchronization, Locks, and Pipes
These locking primitives can be used to implement piping mechanisms. How would this look?
Example:
struct pipe
{
char buf[1024];
size_t r,w;
lock_t lock;
}
char readpipe(struct pipe *p)
{
while (true)
{
lock(&p->lock); // Grab the lock and make sure that there is something in the pipe
if (p->r != p->w)
break;
unlock(&p->lock);
}
char p = p->buf[p->r++%1024];
unlock(&p->lock);
return c;
}
Figure 3 - A pipe.
While this works, the performance leaves much to be desired. By locking and unlocking so much, the CPU will burn up.
It would be better to do without this problem. A better tool would be a different kind of locking primitive that will
work well even when the reader/writer is slow.
IV. Synchronization Mechanisms
There is a real need for a way for processes to tell the OS not to schedule them until there is data to be
written/read ("We need a way to tell the OS, 'Please don't run me until there is data in the pipe'!"
- Eggert 2015). One proposed method is using a blocking mutex (mutual exclusion), for which the
spinlock is the easiest to use, to create. A blocking mutex is like a spinlock except that the thread goes to
sleep until the resource it wants to access becomes available, rather than just spinning. A blocking mutex
is essentially a spinlock without the spinning, because the process gives up the CPU when the resource isn't available.
Blocking Mutexes
Here is a way of implementing blocking mutexes: by creating the functions acquire()
and release(). acquire() obtains a lock
and creates mutual exclusion in a certain area of the program for the calling process. The code can look like
the following:
typedef struct bmutex
{
lock_t lock;
bool locked;
struct proc *blocked; // Linked list of blocked and waiting processes
} bmutex_t;
void acquire(struct bmutex_t *b)
{
while (true)
{
lock(&b->lock);
if (!b->locked) // If it is locked we want to go to sleep and try again
break;
cp->next = b->blocked;
b->blocked = cp; // cp points to the current process table entry // If you are yielding, make sure that you do not have the spinlock
unlock(&b->lock);
yield();
However, there is a race condition. If one process tries to release the lock at the same time that a different
process tries to acquire the mutex, the "acquirer" and the "releaser" will both be writing into the mutex structure
at the same time, overwriting any state changes that they intended to apply.
To fix this, release() must be rewritten in the following way:
A semaphore is similar to a blocking mutex but with an int avail
variable. avail is the number of simultaneous locks allowed. Semaphores
make sure that a quota is placed on how many things can use a particular resource. Semaphores use these primitives:
p and v (acquire and release respectively).
p and v are short for "prolaag" and
"verboog" (Dutch for "try" and "increase", respectively, because these concepts were invented by computer
scientist Edsger Dijkstra).
Pipes can be implemented using the struct bmutex rather than with
unlock():
struct pipe
{
char buf[1024];
size_t r,w;
bmutex_t b;
}
char readpipe(struct pipe *p)
{
while (true)
{
acquire(&p->lock); // Grab the lock and make sure that there is something in the pipe
if (p->r != p->w)
break;
release(&p->lock);
}
char p = p->buf[p->r++%1024];
release(&p->lock);
return c;
}
There is a bug in the code! Being able to acquire the blocking mutex is not related to being able to read data
from the pipe. For efficiency, a process should not be awoken just because the blocking mutex is available.
It should be awoken when the pipe is not empty.
"The metaphorical 'alarm clock' is going to be ringing too often, and the process will once again be chewing
up the CPU. The performance problem is still not solved..." - Eggert 2015
Here is a fix:
bool are_we_there_yet(void)
{
return p->r != p->w);
}
char readpipe(struct pipe * p)
{
while (true)
{
wait_for(are_we_there_yet);
if (p->r != p->w)
break;
release(&p->lock);
}
char p = p->buf[p->r++%1024];
release(&p->lock);
return c;
}
However, there is a bug. This will not work because are_we_there_yet
uses p from readpipe which is not in
scope.
The following is a small fix so that p carries from
readpipe to are_we_there_yet:
bool are_we_there_yet(void *p)
{
return (p->r != p->w);
}
char readpipe(struct pipe *p)
{
while (true)
{
wait_for(are_we_there_yet, p);
if (p->r != p->w)
break;
release(&p->lock);
}
char p = p->buf[p->r++%1024];
release(&p->lock);
return c;
}
The code still does not meet the set goal, since it still chews up CPU time.
What is needed is a conditional variable to work in conjunction with the blocking mutex. The condition is known
to the programmer, but the OS won't care what it is. It is the responsibility of the user to know what
that condition is and to use that variable property properly with respect to that condition.
Here is the condition variable API:
wait(condvar_t *c, bmutex_t *b);
// This will be used instead of wait_for()
// PRECONDITION: The blocking mutex in question must have already been acquired
// ACTION: release the blocking mutex b, and then block until some other thread notifies the current thread
that that condition may be true. Then, let the current process reacquire the blocking mutex and then return.
notify(condvar_t *c);
// Notifies the OS that the condition has become true
// OS will awaken one of the processes that is waiting/blocking on the condition
broadcast(condvar_t *c);
// Acts like notify, but wakes up all waiting processes instead
// Ex: if 12 processes waiting, all will be awoken
Here is readpipe() once again, but this time it has been modified to use a
condition variable (condvar_t).
}
char p = p->buf[p->r++%1024];
release(&p->b);
notify(&p->nonfull);
return c;
}
Often times, synchronization is difficult to achieve because most of the processes are writing to the same memory.
There are usually two types of things that processes do on memory: read-only or read-and-write. Even reading from a
pipe, in the above example, is a writing operation, because it updates the pipe to reflect how many bytes have been read.
Many applications today, however, have readers with read-only accesses. This calls for creating another type of lock:
a read-write lock which allows many readers but at most one writer (i.e. if there is a writer, then there are
no readers).

// PRECONDITION: The blocking mutex in question must have already been acquired
// ACTION: release the blocking mutex b, and then block until some other thread notifies the current thread that that condition may be true. Then, let the current process reacquire the blocking mutex and then return.