Critical Sections and Synchronization Primitives
CS 111, Winter 2015, Lecture 9Scribes: Fan Hung, Daniel Kho, Roger Witkin, Roy Xia
Table of Contents
Implementing Critical Sections
So, assume that we work with a single processor and no interrupts. How do we implement locking and unlocking?
Trick question! With these assumptions it is unnecessary to use such a system. All processes run sequentially in this system.
Now how about with interrupts? The problem is still pretty simple to solve if we have a cheap way to force interrupts to go pending.
splx(int) is a cheap function that tells the OS a priority level to give to the program, in terms of how easy it is to send signals to it, by changing the value in its process-level register. If we want a critical section that shouldn’t be interrupted (unless the interrupt is urgent), we just change this value to a higher number before the start of the critical section, and change it back right after. In short:
To lock: splx(6). This sets the process-level register, and tells the OS not to give the program interrupts unless their priority level is 6 or higher. (i.e. a level 5 critical section)
To unlock: splx(4). This changes the priority back to normal and effectively ends the critical section.
This is a very fast solution since it's just changing the value in a register.
These solutions will work well for things like embedded machines. However, when we remove all assumptions (i.e. we may have a multiprocessor machine) things become a bit more complicated.
A First Attempt at Locking
Let’s try an implementation like
typedef int lock_t;
void lock(lock_t *l) {
while (*l)
continue;
*l = 1;
}
void unlock(lock_t *l) {
*l = 0;
}
But, this doesn’t work. Nothing stops any interrupts or process switching from happening immediately after the while loop in lock(). If this happens, two processes will have the lock, defeating the purpose of attempting to lock.
Also, an int is 32 bits, but our memory bus might be 16 bits. Due to this limitation, data may be loaded in two separate passes, and the *l operation is no longer atomic.
Atomic Instructions
We want to make sure that our loads and stores from different processes don’t get jumbled together, but there are a few cases when atomicity can’t be guaranteed by the good ‘ol x86.
- loads and stores longer than 4 bytes
In x86 aligned loads and stores of the word size are atomic. But our registers can only hold so many bits. Any larger than that, for example in arrays, structs, long long ints, etc., we’re on our own because each word must be loaded and stored separately.
- loads and stores smaller than 4 bytes
Suppose we defined the following struct:
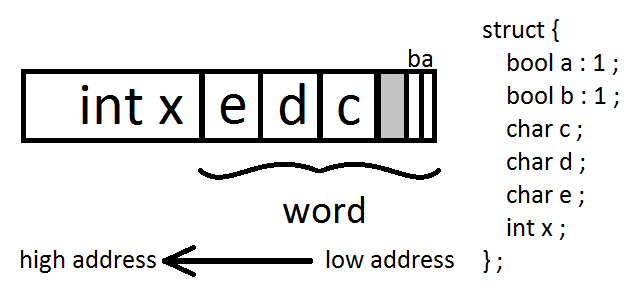
If we had two processes, A and B, and we try to write to the a and b bits at the same time, we might do this:
| ProcA: | load word | a = 0 | b = 0 |
| ProcB: | load word | a = 0 | b = 0 |
| ProcA: | set bit a | a = 1 | b = 0 |
| ProcB: | set bit b | a = 0 | b = 1 |
| ProcA: | store | a = 1 | b = 0 |
| ProcB: | store | a = 0 | b = 1 |
When ProcB stores its copy of the word (which had the original value of a = 0), we undo the work of ProcA.
- unaligned accesses may be jumbled
An example of unaligned access:
union {
int a[2];
char c[8];
} u;
u.a[0] = 12;
u.a[1] = 97;
char *p = &u.c[0];
p++;
int *q = (int*)p;
q now points to an int that is not aligned by word boundaries.
If only loads and stores of 4 byte words are atomic, when we try to write to unaligned blocks, we run into the same problems that we would if we were writing to blocks of data larger than our word size, i.e. we must load or store several words separately.
Another Attempt at Locking
This time, let’s try
void lock(lock_t *l) {
while (*l++ != 0)
continue;
}
The lock spins until it’s set to zero, and then at that instant, we increment and exit, so barring the possibility of integer overflow, it should work, right? Not exactly.
*l++ isn’t guaranteed to be atomic at the x86 processor level. The machine code will implement this as a load, increment, then store. Even a simple instruction like incl (%eax) is implemented this way at the microcode level.
There exists an algorithm to do loads and stores if we assume aligned loads and stores of int. Even if there's no support of atomicity, this algorithm works. This algorithm was designed by Leslie Lamport, a Turing award winner, and is a very complex algorithm.
However, there are special atomic assembly instructions on x86.
lock incl x : guaranteed to increment x atomically
This instruction takes a couple hundred cycles, but it works. The CPU will send a signal to the bus, which can be seen by other CPUs, to identify what has been locked, and other processes will only stop to wait for the lock if they try to access that space in memory.
Let us now assume that there is a wrapper function
void lock_incl(int *)
that executes the above instruction.
So! Let’s try this again:
void lock(lock_t *l) {
while (true) {
int x = *l;
lock_incl(&l);
if (x == 0)
break;
}
}
But it still doesn’t work. There’s a race condition right before lock_incl, where multiple processes grab the value of l before it is locked and all think x is 0.
Like all our normal problems, there’s an x86 instruction to solve this.
xchgl : atomically swaps memory with register
This can be modeled in C code:
int xchgl(int *p, int new) {
int old = *p;
*p = new;
return old;
}
Using this new function, we can try again.
void lock(lock_t *l) {
while (xchgl(l, 1))
continue;
}
void unlock(lock_t *l) {
*l = 0;
}
This implementation is now functional.
Efficiency and Bank Accounts
If we have a bank account, and want to write withdraw and deposit functions, we can start with something like this:
int balance;
bool withdraw(int w) {
if (balance < w || w < 0)
return false;
balance -= w;
return true;
}
This is not thread safe. To make it thread safe, we use a lock!
int balance;
lock_t ballock;
bool withdraw(int w) {
lock(&ballock);
bool ok = (0 <= w && w<= balance);
if (ok)
balance -= w;
unlock(&ballock);
return true;
}
However, the critical section here is rather big, taking up most of the entire function. Let’s try to make it shorter.
Intel gives us an atomic compare and swap instruction, which can be modeled as the function:
bool compare_and_swap(int *p, int old, int new)
{
if (*p == old) {
*p = new;
return true;
}
return false;
}
This can be used to improve the withdraw function:
int balance;
bool withdraw(int w) {
while (true) {
int b = balance;
if (w < 0 || b < w)
return false;
if (compare_and_swap(&balance, b, b-w))
break;
}
return true;
}
The critical section is reduced to just the compare_and_swap call, which means there will be less contention between different threads withdrawing at the same time than the previous methods. However, we need to repeat the computation if another thread has modified the balance during the loop. To summarize, the pros and cons of this method are:
- nicer performance by reducing contention
- contention can chew up CPU if the loop computation is expensive
- only works on 1 word objects
Blocking Mutexes
If we’re worried about performance, we don’t want to be chewing up the CPU between contending processes. Instead, we add a new type of access control: the blocking mutex.
This is like a spinlock, except you give up the CPU when the resource you are waiting for is unavailable.
typedef struct bmutex {
lock_t l; // this protects the fields below
int locked; // is the object locked?
struct proc *blocked; // a LIFO list of processes waiting for the locked item
} bmutex_t;
So how would we lock and unlock this? We do so with the functions acquire and release:
void acquire(bmutex_t *b) {
while (true) {
lock(&b->l);
if (!b->locked)
break;
current_proc->next = b->blocked;
b->blocked = current_proc;
current_proc->status = BLOCKED;
unlock(&b->l);
yield();
}
b->locked = 1;
unlock(&b->l);
}
void release(bmutex_t *b) {
lock(&b->l);
b->locked = 0;
struct proc *p = b->blocked;
b->blocked = p->next; // remove the top process from the list and run it
p->status = RUNNABLE;
unlock(&b->l);
}
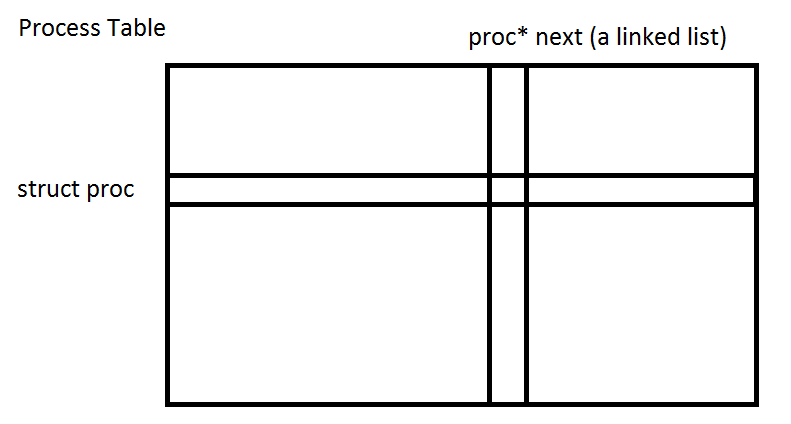
Note: each process has a field that points to the next process in line to run for a blocking mutex. If we visualize the process table as a row for each process, then there's a column that contains pointers to the next process.
Semaphores (a digression)
A semaphore is a type of lock that has an integer field, avail, that says how many simultaneous locks are available.
typedef struct semaphore {
lock_t l;
int avail; // # of simultaneous locks allowed
struct proc *blocked;
} semaphore_t;
The only difference between a semaphore and a blocking mutex is that when we acquire a semaphore, we first need to ensure we have an available lock. If not, then we need to wait for another thread to release a lock. Otherwise, we simply decrement avail and acquire a lock without needing to wait for a release. Likewise, to release a semaphore, we increment avail and release a lock.
We might use semaphores for several reasons, often to improve performance.
Condition Variables
Now, let’s use blocking mutexes to implement a pipe.
struct pipe {
char buf[1024];
size_t r, w;
bmutex_t b;
};
char readpipe(struct pipe *p) {
while (true) {
acquire(&p->b);
if (p->r != p->w)
break;
release(&p->b);
}
char c = p->buf[p->r++ % 1024];
release(&p->b);
return c;
}
This is a functional lock, but we really don’t want our process to be awake just because the mutex is available. We want to be awakened only when the pipe is no longer empty. We’re still chewing up CPU every time we want to acquire a lock, because we need to check for a particular condition, in this case when there’s something to read from the pipe.
We want some way to tell the OS specifically when to wake us up, without chewing up CPU (i.e. no overhead). To do this, we use condition variables.
A condition variable is a blocking mutex with an extra boolean value that keeps track of the condition needed for a thread to acquire a lock. The condition itself only has meaning as defined by the application; the OS does not care what the condition means. By using condition variables, we save CPU time by only waking up threads when they can acquire the lock.
Let’s say we have a boolean condition variable type, condvar_t.
A thread that wants to acquire a lock using condition variables calls the following function:
// Precondition: You have acquired b. // Action: Releases b, then blocks until some other thread notifies us that the // condition may be true now. It then reacquires b and returns. wait(condvar_t *c, bmutex_t *b);
Whenever anything occurs that might cause the condition to be true, the thread should call the following function:
// Tells OS that condition may have changed. notify(condvar_t *c);
The OS, after notification, will awaken one process blocked on that condition.
A function similar to notify can also be called when a condition might be true:
// Like notify, but wakes up everybody. broadcast(condvar_t *c);
The pipe example can be modified to use condition variables. We can define condition variables called nonempty and nonfull. The former allows us to wake up threads reading from the pipe only when there’s something to read, and the latter allows us to wake up threads writing to the pipe only when the pipe isn’t full.
struct pipe {
char buf[1024];
size_t r, w;
bmutex_t b;
condvar_t nonempty, nonfull;
};
char readpipe(struct pipe *p) {
acquire(&p->b);
while (true) {
// We move acquire out of the loop because wait will reacquire for us
if (p->r != p->w)
break;
wait(&p->nonempty, &p->b);
}
char c = p->buf[p->r++ % 1024];
release(&p->b);
notify(&p->nonfull);
return c;
}
Read-write Locks
It is often helpful to establish a difference between readers of data structures and writers of data structures when considering locking. If we’re only reading data, we want to make sure that nobody’s writing at the same time, since a thread would modify the data as we read it, causing race conditions. But it’s fine if there are other readers. (Equivalently, if we’re writing, then nobody else should be reading at the same time).
Therefore, it is frequently helpful to implement a read-write lock. This type of lock allows many readers to acquire the lock at a time, or alternatively just one writer (with no readers) may acquire it.
This is left as an exercise for the reader in Lab 2.