Aside from being correct (i.e. synchronized), multithreaded code should improve performace. One problem that can occur is that one thread owns a lock, but is just spinning. It could yield at the cost of a context switch, but even this could present a problem because we may switch to another spinning thread. To solve this problem, we will have to get the lock to give us more information. Blocking mutexes (also known as binary semaphores) provide locks as well as other information in order to prevent switching to a thread that will simply spin.
struct bmutex{
lock_t l; //controls access
bool locked; //says whether or not the mutex is locked
struct proc *waiter; //to be woken up when the lock is free
}
//precondition: I don't own a blocking mutex
void acquire(struct bmutex *b){ //called rather than grabbing a spin lock
lock(&b->l);
//begin critical section
if(!b->locked){
b->locked = 1;
unlock(&b->locked);
return;
}
b->waiter = currproc; //process table entry of current process
currproc->blocked = 1;
unlock(&b->l);
return;
}
In this implementation, we can only have one guy waiting for the lock. To address this limitation, we make the following changes:
//precondition: I don't own a blocking mutex
void acquire(struct bmutex *b){
lock(&b->l);
//begin critical section
if(!b->locked){
b->locked = 1;
unlock(&b->locked);
return;
}
currproc->next = b->waiter; //keep track of the next process in line
b->waiter = currproc;
currproc->blocked = 1;
unlock(&b->l);
yield(); //need to yield to another process
return;
}
We also need to implement a release function to go along with this acquire function
//precondition: I own a blocking mutex
void release(struct bmutex *b){
lock(&b->l);
b->locked = 0;
if(b->waiter)
b->waiter->blocked = 0;
unlock(&b->l);
}
As usual, it is easier to unlock something than to lock it. As was the case for the acquire function, we need to modify the release function if we want to be able to have multiple processes waiting for a lock. We make the following changes to do so.
//precondition: I own a blocking mutex
void release(struct bmutex *b){
lock(&b->l);
b->locked = 0;
if(b->waiter){
b->waiter->blocked = 0;
b->waiter = b->waiter->next;
}
unlock(&b->l);
}
This code doesn't adhere to the Goldilocks principle. Let's change it so that it does
//precondition: I own a blocking mutex
void release(struct bmutex *b){
lock(&b->l);
b->locked = 0;
struct proc *w = b->waiter;
if(w)
b->waiter = w->next;
unlock(&b->l);
if(w)
w->blocked = 0;
}
This code contains a race, but it's not one that will cause incorrectness. It may just cause us to have to wait a little longer because we believe that a process is still blocked when it isn't.
In synchronization, there are some resources that we want to share. In some cases, a blocking mutex is too restrictive. To expand its functionality, we can treat the lock as an int rather than a boolean. The int will work by keeping track of how many more people can use the resource. This generalization is called a semaphore. To create a semaphore, we need to specify an integer called navail, which will keep track of how much of the resource is currently available. acquire will success if navail is greater than zero and block otherwise. release will always increment navail. Semaphores were the first well-publicized form of synchronization, so it's important to be able to talk about them for interviews. Traditionally, a function called P does acquire and a function called V does release. The names of these functions come from Dutch words since the creater of semaphores, Dijikstra, was a Dutch man.
Let's now discuss a different speedup problem. In particular, let's look at the case where a pipe has multiple writers and one really slow reader. The write threads will keep being unable to write to the pipe because it will fill up before the reader has a chance to take care of it. If we use a blocking mutex to synchronize this situation, we're going to have a lot of wasted CPU time. A write thread will often get the processor, try to write, fail, and then yield, likely passing the processor on to another writer who will do the same thing. In this situation, the writers are constantly polling, which adversely impacts performace. In order to solve this problem, we need some way for the Operating System to know what the writers are looking for so that the schedulers know when it's going to be a waste of time to schedule a thread.
There exists something called a condition variable that provides this for us. A condition variable contains a blocking mutex and an expression describing what we're waiting for. We can assume that the expression is a bool for simplicity. The scheduler won't bother waking up a process until the bool is true because it knows that it will be useless until it is. In our pipe example, the condition variable's boolean expression would be p->w - p->r != 1024. From the point of view of the OS, this is just a single voolean. It doesn't want to deal with arbitrary user expressions. Therefore, it is the user's responsibility to take care of setting this expression.
Let's create our pipe in the following way
struct pipe{
char buf[1024];
unsigned r, w;
condvar_t nonfull;
bmutex_t b;
}
Now, we're going to have to define some new primitives to replace acquire and release.
b has been acquired. It then releases it, waits for a condition to be notified, and then reacquires it.
void writer(struct pipe *p, char c){
acquire (&p->b);
while (p->w - p->r == 1024)
wait(&p->nonfull, &p->b)
p->buff[p->w++%1024] = c;
notify(&p->nonempty);
release (&p->b);
}
Typically, we use spin locks for small critical sections. Blocking mutexes are for more heavyweight critical sections, and condition variables are even more so.
Speedup done with blocking mutexes and condition variables are "atop" spinlocks. Another type of speedup exists using a Hardware Lock Elision (HLE), which are "below" spinlocks. Say two threads are reading and writing to an object, but they aren't touching the same members of the object. We want the threads to be able to do this at the same time since there is no risk of race conditions. We could just have a different lock for each action that the threads can perform, but we'd end up having a lot of locks to deal with if we did that. Instead we take the HLE approach.
CPU1 CPU2 start trans start trans movq movq movq movq addq addq end trans end trans
Each CPU executes a start trans instruction, does its job, and then issues an end trans. While you're in the middle of a "transaction," the hardware stores whatever modifications you've made into a cache. When the transaction ends, your modifications are moved into shared memory as long as there are no issues. However, if there were issues, the endtrans will simply fail and the modifications will get thrown out. In this case, we can decide what's best to do--perhaps we will loop back and retry what we just did until it is successful.
X86 example:
lock:
movl $1, %eax
try:
xacquire lock xchgl, %eax m
cmp $0, %eax
jnz try
ret
unlock:
xrelease movl $0, m
ret
The idea behind this is to avoid too much traffic to memory. For one particular benchmark, HLE with many threads ran 6x faster, but HLE with a single thread ran 2x slower. This is probably because there is a significant hardware overhead. HLE should only be used on small critical sections. If there are too many instructions, it will be impossible for the hardware to cache everything.
Consider the following code.
bool copyc(struct pipe *p, struct pipe *q){
bool ok = 0;
acquire(&p->b);
acquire(&q->b);
if(p->w - p->r == 0 && q->w - q->r != 1024){}
q->buff[q->w++%1024] = p->buf[p->r++%1024];
ok = 1;
}
release(&p->b);
release(&q->b);
return ok;
}
If someone is writing from q to p as we are writing from p to q, it could end up creating deadlock.
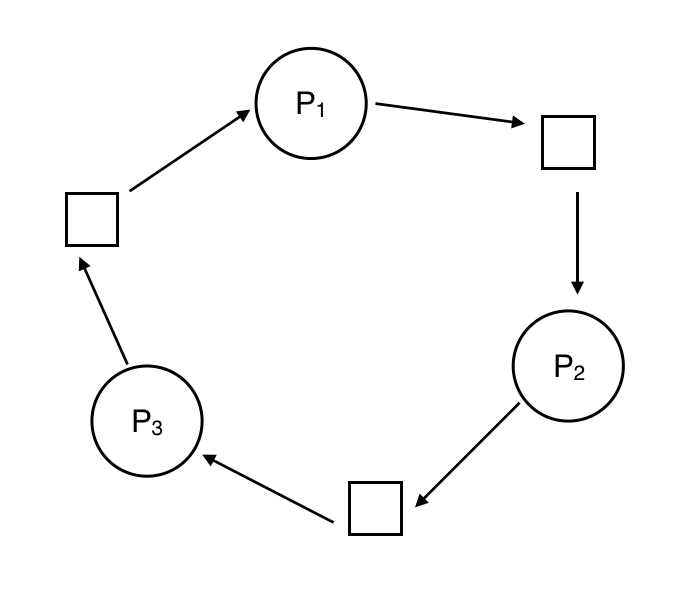
There are 4 conditions for dead lock
Solutions to deadlock
acquire fails. This can complicate the API but eliminate the possibility of deadlock.acquire, call try_acquire. try_acquire works like acquire but fails if someone else has the lock. This would break the "hold and wait" condition for deadlock. Everyone needs to acquire locks in the same order. This is easy to implement. Going in order of increasing address would make sense.Suppose we have three threads with different priorities
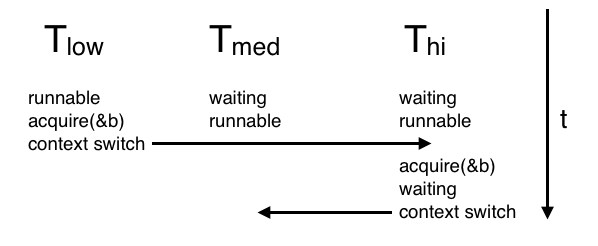
In this situation, the low priority thread never gave up the resource that the high priority thread needed. The high priority thread is unable to run because the medium priority thread has taken over the CPU, making it impossible for the low priority thread to release the resource that the high priority thread needs. The solution is to allow the thread that holds a resource to borrow the priority of the thread that needs to acquire it. Here, that means letting the low priority thread borrow the high priority threads priority long enough to finish what it was doing and release b so that the high priority thread can run.
Suppose an incoming packet causes an interrupt. The interrupt handler puts the bytes of the packet into a queue and tells the OS that there's a new packet that needs to be dealt with. If a bunch of packets are coming in, we get stuck spending a lot of time in the interrupt handler and not a lot of time processing the packets. Eventually, we're going to have to start dropping packets. This is a condition called livelock.
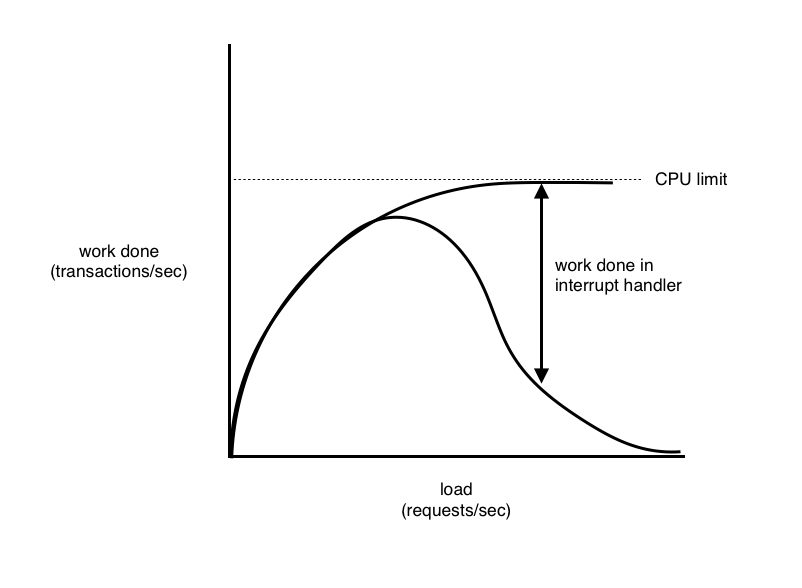
To solve the problem of livelock, we need to disable interrupts when we reach a certain load level. We'll lose packets for a little while, but at least we'll be able to get stuff done.
A lot of the solutions we've had to come up with are really complicated. We can avoid synchronization and the problems that come with it by using a different approach: event-driven programming. This is basically the opposite of multithreading. Instead of using parallelism, we divide our program into callbacks (as opposed to threads). Callbacks need to be small and guaranteed to finish quickly. This means they can't call functions that have the potential to hang for a long time (e.g. getchar(), waitpid()). Instead, we use different I/O primitives that are guaranteed not to hang, such as aioread(). The benefits of this approach are simplicity and reliability. The downside is that it is less scalable than parallelism.