Speeding up synchronized code with Blocking Mutexes
Using a simple mutex, we are able to nail correctness. However, the speed of our code is compromised.
If we have too many threads running, they start stepping on each others' toes.
With a spinlock, one thread owns the spinlock and the others spin (wasting CPU time).
To solve this problem, we introduce the blocking mutex:
struct bmutex
{
lock_t l; // Lock to control access
bool locked; // Bool to keep track of locked status
struct proc* waiter; // Holds process that is currently waiting on process
};
The blocking mutex builds upon the simple spinlock by using a spinlock to access the mutex, and then checking the bool locked field check if the mutex is locked or not. This can allow for processes that would have otherwise been spinning to instead yield() or schedule().
Sample Acquire function
Here is an example Acquire() primitive for this blocking mutex:
void acquire(struct bmutex* b)
{
lock(&b->l);
if (!b->locked)
{
b->locked = 1;
unlock (&b->l);
return;
}
curproc->next = b->watier;
b->waiter = curproc;
curproc->blocked = true;
unblock(&b->l);
yield(); //let another process run
return;
}
Here, if the the process can acquire the mutex, it sets the locked field to 1, unlocks the spinlock, and returns, so then we're off to the races. But if the mutex is locked, it instead adds the current processor to a linked list of processors to run after the mutex unlocks, and adds the current waiting one to the waiting list of the processor. Then, we can yield(), and context switch into a process that has work that can currently run.
Sample Release function
Now, what would you imagine the Release() function to look like?
//Release implementation #1
void release(struct bmutex* b)
{
lock(&b->l);
b->locked = false;
if (b->waiter)
{
b->waiter->blocked = false;
b->waiter = b->waiter->next;
}
unlock(&b->l);
}
This is a decent first draft, but here we encounter the Goldilock's principle of Critical Sections; we want our critical sections to eliminate any type of race conditions, but we want to push any code that doesn't risk causing a race condition out from the critical section between the lock() and unlock() functions. Can we do better?
//Release implementation #2
void release(struct bmutex* b)
{
lock(&b->l);
b->locked = false;
struct proc* w = b->waiter;
unlock b(&b->l);
if (w)
{
w->blocked = false;
b->waiter = w->next;
}
}
Nice try! However, by shrinking the critical section to simply storing a proc pointer as well as the unlocking of b, we introduce a race condition, as by unlocking before we are finished using b's member variables, we risk that we can stomp on another process that is setting the b->waiter field. So if this porridge is too cold, can we find a happy just-right?
//Release implementation #3
void release(struct bmutex* b)
{
lock(&b->l);
b->locked = false;
struct proc* w = b->waiter
b->watier = w->next;
unlock(&b=>l)
w->blocked = false;
}
It turns out here, we could only get the one boolean out of the critical section. However, if that changing boolean were instead a long function call, we can see how that would save a significant amount of time!
Here are the more common names for these two functions:
- P(sem): Acquire-equivalent primative (Prolaag)
- V(sem): Release equivalent primative (Verhoog)
These mutexes can also be easily adjusted to allow for n users at one time, by replacing bool locked with a number that initializes to n and decrements every time it is acquired, and incremented every time it is released.
Solving Pipe Problems with Condition Variables
Pipes are still problematic, even with the blocking mutexes, because we may get into a situation where we have writers who are writing to the same pipe and constantly polling, eating up our valuable CPU time. However, we can solve this problem by building upon our previous blocking by introducing a new type of mutex: The Condition Variable.
Condition Variables
A Condition Variable consists of two valuable pieces: A Blocking mutex, and a so-called waiting expression, which is specified by a boolean, but must be enforced by the user's code.
Here is a sample pipe structure from a little bit ago using this new condition variable.
struct pipe
{
char buf[1024];
unsinged r, w;
condvar_t nonfull, nonempty;
}
A condition variable for this pipe struct would be some expression that checks whether the pipe is full or not, such as this:
conditionvarc = p->w - p->r != 1024;
Using Condition Variables
With the condition variable pipe and expression defined, we can now implement a simple writec() function that takes a pipe and a character, and writes to the pipe only when the condition variable is met.
void writec(struct pipe* p, char c)
{
acquire(&p->b);
while(p->w-p-r != 1024) //Implementation of condition variable
wait(&p->nonfull, &p->b);
p->buff[p->w++ % 1024] = c;
release(&p->b);
notify(&p->noempty);
}
Here, we see the condition variable expression used in the while loop. However, afterwards we also see the wait() funciton, which undergoes several steps of locking and unlocking b.
- First, b is required to have been already acquired, as a precondition. Because wait() exists in the critical section, this code will not be run otherwise
- Next, the condition variable is checked, and if it is not available, the process releases b, and then waits until it recieves a notification, via the notify() function.
- After notified, the process once again locks b, and continues with the writing process.
- Finally, when operations are completed, we call notify() to signal other waiting processes that their condition is met.
Note here we call the notify() function on the noempty condition variable, which is notifies potential readers, not writers. This is because of the cyclical nature of reading and writing to pipes. The accompanying readc() function would have appear very similar to the writec() function, although it would exchange the usage of these two condition variables.
Mutex Wrap-up:
After taking a look at all these three different types of mutexes, we can condense their use cases into the following three categories:
- Spin locks: Used for applications with very short turnaround times
- Blocking mutexes: Used for applications with slightly longer wait times
- Condition variables: Used for applications with extremely long or maybe unbounded wait times
Hardward Lock Elisons (HLE)
A relative of the mutex is the Hardward Lock Eliason, which is most effective when running on an application with only two or more locks. With HLE, each CPU caches transactions in local memory, and then after transactions are completed, the results are compared and any actions that trampled upon eachother are canceled out.
Here is the sample implementation in assembly:
x86 lock:
lock:
movl $1, %eax
try:
xacquire lock xchgl %eax, m
cmp $0, %eax
jnz try
ret
unlock:
xrelease movl $0, m
ret
Deadlocking
Imagine the following pipe-copying code:
bool copyc(struct pipe* p, struct pipe* q)
{
bool ok = 0;
acquire(&p->b);
acquire(&q->b);
if (p->w - p->r != 0 && q->w - q->r != 1024)
{
q->buff[q->w++ %1024] = p->buff[p->r++ %1024];
ok = 1;
}
release(&p->b);
release(&q->b);
return ok;
}
Copying a pipe is an operation that reads from one pipe and writes to another pipe simultaneously, so naturally, we would want to lock both pipes before we attempt to do this. However, what if there was another running process that was copying from pipe q to pipe p? This is an issue.
Deadlocking, Defined:
Deadlocking has 4 conditions:
- Circular wait (Two processes waiting on one another)
- Mutal exclusion (Both items are single access)
- No lock preemption (No way to "bust the locks")
- Lock holding + Waiting (Processes wait while holding another lock)
This pipe copy code unforunately fits all four requirements. So how do we solve this issue?
Solutions to deadlocking:
-
Have Operating System look for cycles.
- Complicates the OS API
- Requires tests for acquire() calls
- Ex:
if ((!acquire(&p->b)) abort();
- Have a courser (more wider encompassing) locks
-
Institute lock ordering
-
Use try_acquire() function, which returns immediately whether we can obtain the lock or not. If lock fails, release all and return to start.
-
Everybody has to agree about the order of the locks
-
Ex. Using lock ordering:
start: //Start locking point
acquire(lock0);
try_acquire(lock1);
...
try_acquire(lock n-1);
Priority Inversion
Priority inversion is when a high priority task is preempted by a medium/low priority task. As a result the priority of the tasks at hand are inverted. This is considered a major issue in computer science. In fact, NASA's Jet Propulsion Laboratory lost their Mars Pathfinder Rover due to this bug.
To better understand this issue, lets take a closer look at the Mars Pathfinder's scenario.
Consider the following threads:
- T_High: Responsible for communication with Earth. This is critical.
- T_Med: Responsible for checking battery level.
- T_Low: Responsible for processing data and sending images back to Earth.
Lets take that T_Low is runnable and T_Med and T_High are waiting. T_Low locks a certain resource and afterwards T_High becomes runnable and locks the same resource. At this time, T_Med becomes runnable. T_High is now in a waiting state, since it is waiting on T_Low to unlock the resource it needs. T_Low will not be run since we have a higher priority thread that needs to be run (T_Med) and T_High will not be run since it is waiting on T_Low. Thus T_High will starve since T_Low will not be run until T_Med is finished with the tasks at hand, which is not guaranteed to happen. T_Med is running although we should be running T_Low so that our high priority thread, T_High can run. The priorities have been inverted and now the rover is unable to establish communication with Earth, since it is busy running T_Med code.
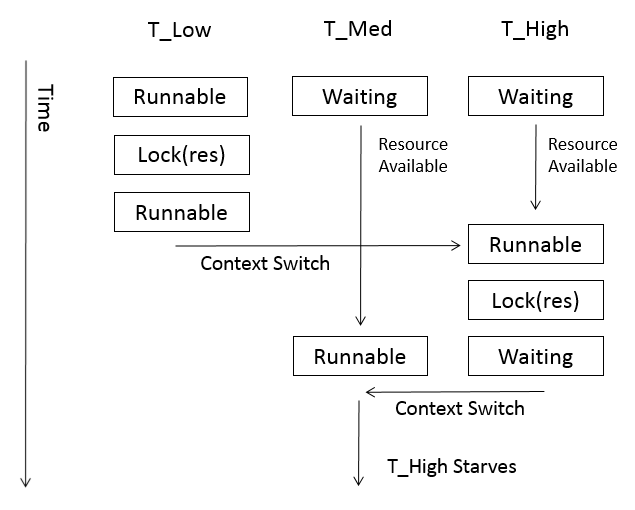
The issue of priority inversion can be resolved by giving lower threads priority when higher priority threads are waiting on them. In this case, if T_Low was temporarily given the priority of T_High (since T_High was waiting on T_Low), the rover would have been able to communicate with earth as it should.
Livelock
Livelock happens when execution is not blocked but very little process is made.
Lets consider a server which has a maximum throughput of 10K Requests/sec. During very high load, we would expect the server to cap out at 10K Requests/sec, however in reality we see this is not the case. During loads over 10K Requests/sec, the server starts to perform terribly. This is because the server is spending CPU time just queueing requests and it never actually gets a chance to process the requests.
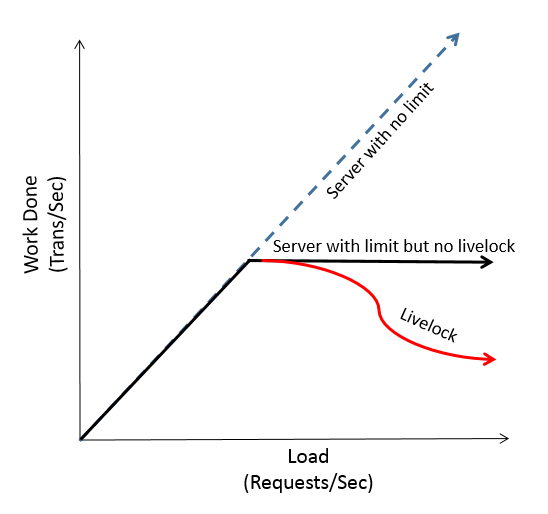
To solve this problem, we have to look closely at how the server is working.
When a packet is recieved, an interrupt occurs, lets say the interrupt handler does the following:
- Take in the bytes
- Put request in queue
- Tell server program to handle packet (new_packet();)
The livelock is due to the fact that we are spending too much time in the interrupt handler queueing tasks and less time actually handling the requests. Because ofs this, requests continue to pile on and the server is unable to get any work done. We can fix this by simply disabling the interrupt handler. This will result in packet/data loss but we will at least be able to process some of our requests, which is better than being stuck in a livelock.
Event-Driven Programming
There is a school of thought that believes using the concept of threads and locking simply results in buggy and slow code. This school of thought advocates event-driven programming.
Event-driven programming can be thought of as the inverse of multithreading. All processes are single threaded, there is no parallelism with shared memory and instead of dividing a program into threads, it is divided into "callbacks".
Each call finishes in a small amount of time and and after it is done, it calls the code in the callback function.
An example of this would be if instead of
while((c=getchar() != EOF))
putchar(c)
we wrote something like this
aio_read(..., callback);
here another part of the program will handle the reading of the user's input and once done, the callback specified by the program will be called.
In event-driven programming there is usually one main loop which consists of analyzing a queue of events and calling the appropriate handlers.
© 2016 Jonathan Chu and Vipul Kashyap