CS111 Lecture 10 Scribe Notes - Winter 2016
By: Shivam Thapar, Andy Yu, Ravi Jayanthi
Basic Semaphores
A semaphore is a variable or abstract data type that is used for controlling access, by multiple processes, to a common resource in a concurrent system such as a multiprogramming operating system
The basic functions of a semaphore are:
- P -- acquire (comes from dutch — Prollag)
- V -- release (comes from dutch — Verhoog)
Binary Semaphores
General Idea
We are concerned about file system performance
Why do we need synchronization?
We’ve started using locks to ensure mutual exclusion, which works fine if we don’t care about performance. However, when critical sections start getting longer we start seeing inefficiencies (ex. spinlocks, which is just busy waiting). To solve this, we can use binary semaphores to provide mutual exclusion to critical sections.
Consider this scenario:
We have a file to be locked. Say one thread holds a lock on this file and the other threads in this context are in spinlock. However, having all of these threads continuously waiting to acquire a lock is a waste of processing time. We can improve this by having spinning threads yield control to the CPU and switch to a different thread while waiting.
Imagine this now:
What if there’s a bunch of waiting/spinning processes?,Then the scheduler will continually switch to a thread that is also in spinlock, and thus just waste energy doing context switches. Ideally, we want our threads to switch to another thread that is able to do useful work.
To solve this problem:
We need our locks to hold more information than simply saying whether they’re locked or not. With more information, the OS can more intelligently decide which processes should be skipped (they’re all spinning anyway). So, instead of just using a basic lock, we want to expand this idea into something called a binary semaphore (or blocking mutex), which will include the extra information the OS will use. A sample implementation of this could be as follows:
struct bmutex{
lock_t l;
bool locked;
struct proc *waiter;
}
The lock_t l is a spinlock which controls access to the blocking mutex, to avoid race conditions and ensure atomicity. The bool locked, however, is what actually tells us if the bmutex is locked or not. Additionally, if a process tries to acquire a blocking mutex and it’s locked, this binary semaphore can enable this waiting process to not just yield to the CPU. Rather, we add this waiting process to the binary mutex’s struct proc *waiter list so that when the blocking mutex is unlocked, this waiting process is given control. If there are no processes waiting on a blocking mutex, *waiter will be set to NULL.
With this definition of a blocking mutex, we can now write a function to acquire the blocking mutex. The precondition for this function will be that the running process does not own the blocking mutex.
void acquire(struct bmutex *b){
lock(&b -> l); // grab the bmutex’s lock to see if it’s locked
if ( !locked ){ // if bmutex is not locked
b->locked = 1; // lock the bmutex;
unlock(&b->locked);
return;
}
currproc->next = b->waiter; // sneaky, because if someone is already waiting,
// you cut in front of them and, become the waiter
// (you could change it to be FCFS if needed)
b-> waiter = currproc; // tells bmutex, that the current prcoess is waiting on it (if the bmutex is locked)
currproc->blocked = true; // tells scheduler that the current process is busy, so don’t run it (it’s blocked!)
unlock(&b -> l);
yield();
}
Similarly, we can write a release function which releases the blocking mutex, with the precondition that the current process owns the blocking mutex.
void release (struct bmutex *b) { // releases the bmutex
lock(&b -> l); // lock the bmutex so you can modify it
b->locked = false; // the bmutex is not locked anymore
if ( b->waiter) { // if something is waiting on the block mutex
b->waiter->blocked = false; // let the waiter process run (unblock it)
b->waiter = b->waiter->next; // let the next guy in the queue be the process blocked by the bmutex
}
unlock (&b->l);
}
However, we should make use of the Goldilocks Principle and make our critical sections smaller. We can change release as follows:
void release (struct bmutex *b) {
lock(&b -> l);
b->locked = false;
struct proc *w = b->waiter;
if( w )
b->waiter = w->next;
unlock(&b->l);
if ( w ) { // this only works on the process, not bmutex, so it doesn’t have to
// be in critical section
w->blocked = false;
}
unlock (&b->l);
}
Similar changes can be made to acquire.
Counting Semaphores
New scenario: Now what if we have resources that we want to share? For example: say we have a database client which can have up to 10 connections on its server. In this case, we will observe that the blocking mutexes are going to be too restrictive.
Initially apparent solution: The natural generalization is to change the blocking mutex bool to an integer (to increase the MAX number of connections or number of items that can share it)
Further Notes: To implement this, we have to add a field to the semaphore called navail (number of available resources). When we create the semaphore, we specify the navail. If someone tries to acquire a lock, we check that navail > 0, and if so we should quickly acquire the lock. If navail is 0, we block the lock from being acquired. When a lock is released, navail should also be incremented since one more process can gain access to the resource now.
Condition Variables
Scenario:
Suppose we try to apply a semaphore or blocking mutex to pipes. Also we will assume that the pipe in question has multiple readers or writers and all of these need access to a resource. Even if these pipes go to sleep as they’re blocked, they’re still going to be chewing up CPU time.
First, why does this happen?
Each of the writers are going to be continuously trying to write to the pipe. The first process will ask for control of the pipe and since there are no other writers on the pipe, it will be granted. Unfortunately, the pipe is full, so the writer immediately releases the lock on the pipe. Then the CPU (which consults the bmutex) will schedule the next waiting writer to have control of the pipe. Again, the writer will start to write to the pipe just to see that the pipe is full. This will keep occurring for all of the processes. This iterative process is referred to as polling.
The problem occurs because the bmutex doesn’t know what the writers need the pipe for. The bmutex only ensures that n processes (or writers) are able to write to the pipe at the same time.
We will be wasting CPU resources as the writing processes are constantly polling. These constant context switches will waste processor time which is the same problem we had before!
We need a way for the OS to know why processes are trying to acquire a lock on a mutex, This way, the OS can tell processes to stop trying to look into pipe repeatedly to avoid chewing up CPU.
How do we fix this?
We can accomplish this by implementing a condition variable. A condition variable will have 2 components: blocking mutexes and some sort of boolean expression that describes what we’re waiting for. This boolean expression is represented as a single boolean value that the OS can see. The user must set this boolean value.
We can solve this problem specifically with this:
cond_var_t expr; // if p->w - p->r != 1024, pipe is not full
This piece of code can be integrated into the pipe implementation with:
struct pipe {
char buf [1024];
unsigned r,w;
cond_var_t nonfull; // we want to wait for the pipe to be not full when writing
cond_var_t nonempty; // make sure nonempty, when reading
bmutex_t b;
}
void writec ( struct pipe *p, char c){ // write char to pipe
acquire( &p -> b ); // could take a little bit of time, since other things could be asking for the lock
// but this time is insignificant compared to the time needed by WAIT
// now we know we own the blocking mutex
// it’s our responsibility to set the condition variable
// we must tell the OS if the cond var is true
while ( p->w - p->r == 1024){
wait( &p -> nonfull, &p->b ) // WAIT is given address of cond var variable and address of the blocking mutex
// PRECONDITION: b must be acquired
// releases b, waits until condition is notified, then reacquires b
// this wait call can take a while, since it’s possible nobody is reading from the pipe, so this wait could take
// quite a bit of time
}
p-> buff[ p->w++ % 1024 ] = c; // write char to pipe
release (&p -> b );
notify( &p->nonfull ); // tell the OS to wake up any process that is waiting for this condition to be true
}
Caveats:
- Use mutex’s for smaller things (like incrementing a bank account num)
- Use wait and condition_vars for indefinite waiting (i.e. waiting till a pipe is read from) to ensure CPU time is not being wasted by threads continuously polling to see if a condition is met.
- This is because wait is really powerful since it frees up CPU and makes sure CPU time is not being wasted for longer wait calls.
- However, it also the slowest, most heavy-weight call.
- How does OS ever know that the pipe becomes non empty?
- we need 1 more primitive to tell system that the thing has some data. This primitive will be called notify!
- Using condition_vars is tricky because when you have released lock (i..e in the wait call), you don’t have exclusive access to p anymore so be careful!
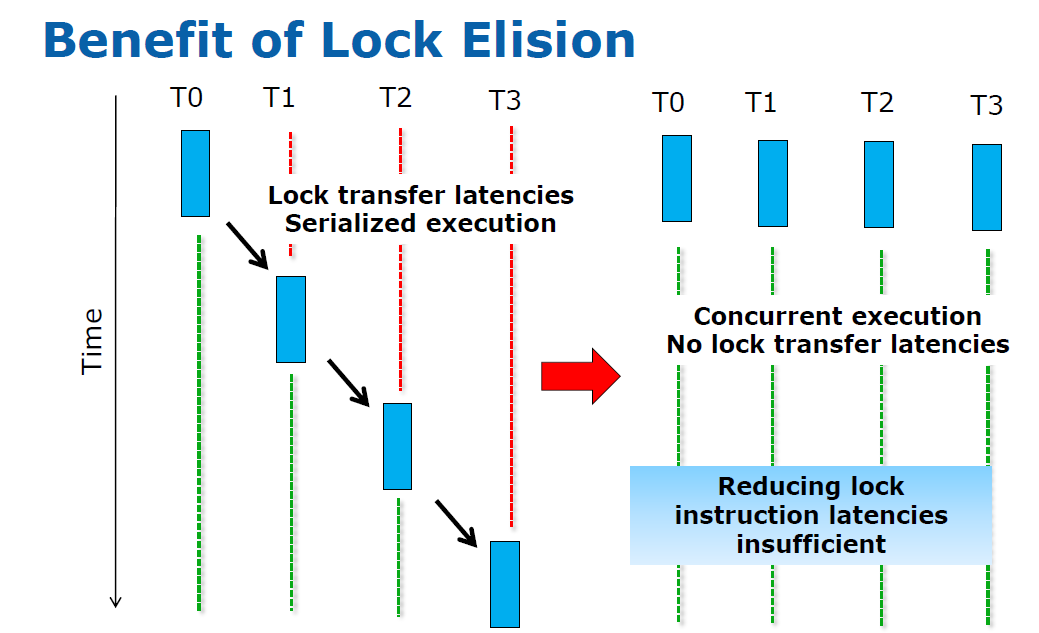
Hardware Lock Elision
Basically, HLE will attempt to remove locks on a critical section. The CPU will thread the code between lock and unlock instructions into a transaction. These instructions are all executed and then cached. Before these changes in the cache are committed to main memory, the CPU will check to make sure no conflict was found (i.e. the threads overwrote shared variables). If the lock elision is successful, all threads can work in parallel as if there were no critical sections in the first place. If a conflict is found, then the transaction is cancelled and the CPU falls back on the traditional software-locked implementation.
Ideally, if code was written perfectly, we would not have a need for Hardware Lock Elision. In reality though, many critical sections are larger than necessary and locking implementations are much coarser-grained than what is best for optimal performance. This is likely to do with the idea that it is much better to have slower code that is safe, than slightly faster code that could potentially lead to overwriting threads and race conditions. Hardware Lock Elision improves upon this by providing a way to allow for more parallelism (and better performance) while still keeping the fallback of the traditional, coarser-grained software locks to ensure that there are no race conditions.
The granularity of locking implementations refers to the general size and scope of a critical section. “Coarse” granularity typically denotes a larger critical section (would be more reliable in avoiding race conditions) whereas “smoother” granularity would involve smaller critical sections and better parallelism (this will be less safe but more efficient).
When you acquire a lock with an XACQUIRE-prefixed instruction, the lock isn't actually acquired. The write operation is ignored, but the address is added to the set of addresses that the transaction reads, so the transaction will fail if something else writes to that address (for example, some legacy code trying to acquire the lock with the old instruction). Execution continues until the XRELEASE-prefixed instruction, and the transaction is then committed. If it succeeds, the code acts exactly as it would have if the mutex had been acquired: None of the memory operations conflicted, and the lock has been elided.
If the transaction fails, the thread returns to the start. This time, it actually acquires the lock. The acquire instruction proceeds as if the XACQUIRE prefix didn't exist, and execution proceeds just as it would on any other processor.
x86 Sample Instructions:
lock:
movl $1, %eax
try:
xacquire lock xchgl %eax, m <- mutex
cmp $0, %eax
jnz try
ret
unlock:
xrelease movl $0, m
ret
C Code:
lock ( &l );
x = 3;
unlock( &l );
Deadlock
We also have to worry about the issue of Deadlock: which is when two or more competing actions are each waiting for the other to finish, and thus neither ever does. Here is some example code that handles the standard deadlocking issues:
void copyc (struct pipe*, struct pipe *q){
bool ok = 0;
acquire(&p-> b);
acquire(&q-> b);
if (p->w-p->r!=0 && q->w-q->r!=1024) // CRITICAL SECTION
q->buf[q->w++%1024]=p->buf[p->r++%1024], ok=1; // CRITICAL SECTION
release(p->b);
release(q->p);
return ok;
}
n = read(0, buf, sizeof buf);
write(1, buf, n)
In terms of recognizing Deadlock, we need to see all 4 conditions present:
- Circular Wait: circular wait is essentially the concept that we can have a series of process waiting on each other in a closed loop such that the last process will be waiting on the first, resulting in an infinite loop.
- Mutual Exclusion: if you remove all locks, you’ll never have deadlocks (foolish solution obviously)
-
No Lock Preemption
- Preemption: tthe act of temporarily interrupting a task being carried out by a system, without requiring its cooperation, with the possible intention of resuming the task at a later time. An example of this could be seen in a sysadmin killing a process if it goes rogue for some reason.
- Lock Preemption extends this concept. While a transaction is active, its locks may be preempted to avoid a potential deadlock.
-
Hold + Wait: a process can hold a lock on one object while waiting on another
- maybe one solution: if you’ve acquire a blocking mutex, you can’t acquire another one
Solutions for deadlock:
- OS can look for cycles: if it knows a cycle is about to be created, acquire fails. Only allocate resources like mutex locks such that circular wait is impossible. However, this approach adds complexity. Every time a lock is trying to be acquired, another condition has to be met.
- Use Coarser Locks for combined operations. However, as we discussed before, a coarser lock will result in more bottlenecks (less parallelism, worse performance).
- Lock Ordering: Rather than call acquire, we assume the existence of another primitive (tryacquire) and run it.
-
Tryacquire functions more or less like acquire, but if someone else has the lock, it immediately fails and returns false. It will return 1 if you have the lock and 0 if somebody else does. With this solution, either way, you’ll never wait. If we want to acquire N locks, we can use this code:
acquire (lock0); try_acquire (lock1); ... try_acquire(lock(n-1));With this implementation, if any call to try acquire fails, you release all locks and try everything again. We never hold a lock while waiting for another, since try_acquire doesn’t block! There is a caveat here as well: locks must be in increasing order. For our example: &l < &m.
-
Tryacquire functions more or less like acquire, but if someone else has the lock, it immediately fails and returns false. It will return 1 if you have the lock and 0 if somebody else does. With this solution, either way, you’ll never wait. If we want to acquire N locks, we can use this code:
Priority Inversion
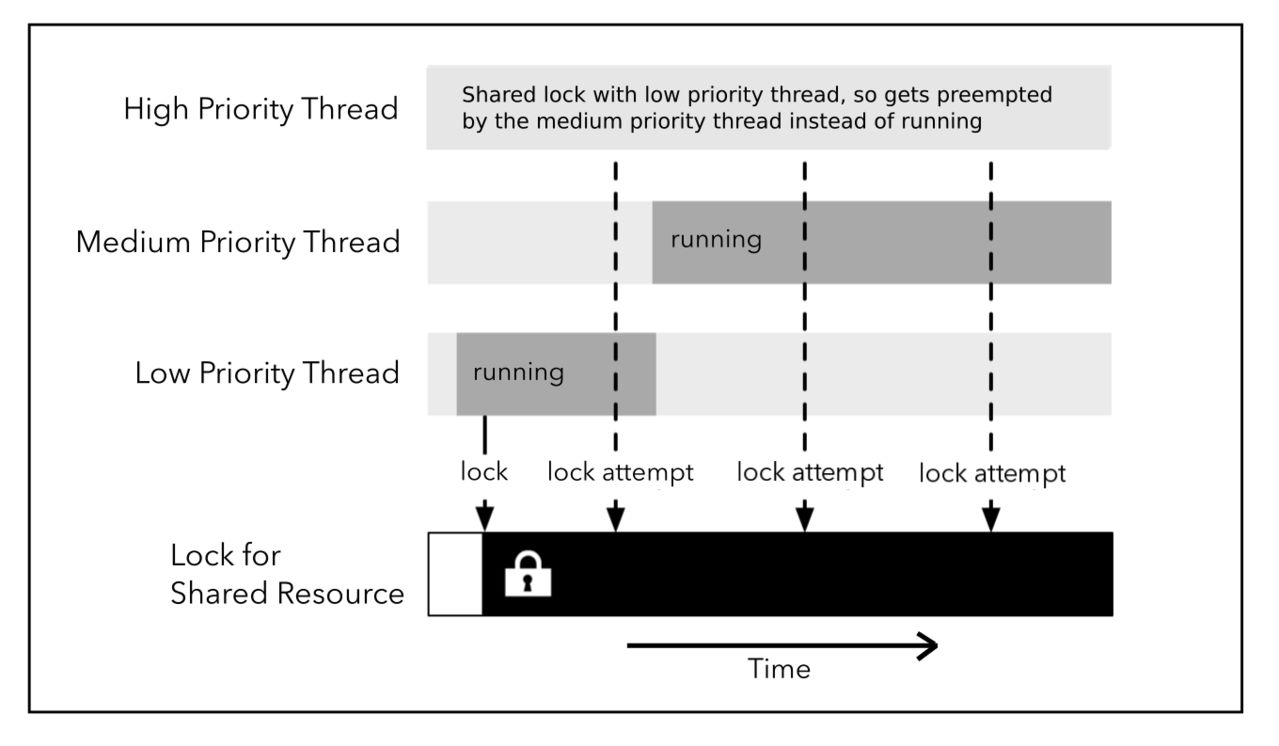
Priority inversion is a problem that occurs when a high priority task is preempted by a medium priority task, due to a shared resource (like a lock) shared by a lower priority task. This is clearly demonstrated in the figure showing an example of this case. This goes against the idea that tasks should only be preempted by higher priority tasks or temporarily by a lower priority task which must finish using a resource shared by both tasks.
How do we fix priority inversion?
- Priority inheritance
-
With priority inheritance, a lower priority task is temporarily given the priority of the highest waiting priority task that it shares a resource with for the duration of its use of that shared resource. This will prevent our medium priority tasks from preempting the low priority task and by extension, the waiting high priority task.
-
Recieve Livelock
Receive Livelock is when the system spends all its time processing interrupts and in doing so, excludes the other necessary tasks. Under extreme conditions, no packets are delivered to the user application or the output of the system. We observe this when an operating system uses interface interrupts to schedule network tests. These interface interrupts bring about behavior in a system characterized by low overhead and good latency at low loads but degrade at higher loads.
What we actually want is for the benchmark-performance graphs to follow a linear trend. Ideally, a system would just do whatever work given to it. However, what we actually see is CPU limit cutoff due to a maximum number of cycles. At this cutoff, we observe a gap marked by scheduling overhead. Priority Inversion occurs and the system will begin to overload.
Example: Suppose you’re a router. If an incoming packet causes the hardware to trap (maybe its an interrupt), the handler will takes bytes of the packet, put it in a queue, and create a new_packet().
What can happen if we’re not careful is: we may receive a lot of packets. If we do we’ll incur serious overhead in inserting bytes from these packets into a queue which will eat up the CPU and not let it work on processing the packet.
This “situation” is receive livelock. You’re always getting “useful work” done, but most of this is happening in the interrupt handler (which is high priority), but you end up doing that instead of doing the actual relevant work of processing the packet.
One possible solution is to put a limit on the process rate. Once we hit this limit: disable the interrupt handler, so the graph becomes cuts off at that CPU limit. This way it doesn’t slope downwards with a high incoming packet rate. Instead it just stops dealing with new incoming packets when the rate is high enough.
Event-Driven Programming
Can we do all this in a much simpler way?
An alternate paradigm of programming called event-driven programming deals with synchronization of threads, by getting rid of threads entirely! Event-driven programming (EDP) is essentially the inverse of multithreading. Everything in an event-driven programming paradigm is single threaded, such that you can’t do anything in parallel with shared memory.
There are several benefits of using EDP. For one, you divide your program into much smaller callback functions, each of which finishes relatively quickly. So, for example, instead of calling functions like getchar() which take a lot of time, you can use asynchronous IO functions like ao_read, which accepts a callback function which is called once the read completes. This means that the ao_read function simply schedules a read operation and assigns the callback to execute once the read operation completes. The ao_read function itself, however, can return before the read operation is actually complete.
The benefits of event-driven programming is that it allows you to have much simpler functions, mostly in the form of callbacks. However, a downside (or possible upside...) of this approach is that you have to break up your program into many smaller functions.
An argument against event-driven programming is that it doesn’t scale as it would perform much more poorly than a traditional multithreaded paradigm. However, proponents of event-driven programming claim that it scales just fine, since it uses many single-threaded processes to achieve the same effect as a multithreaded program. The big advantage of EDP in this case is again its simplicity in its short functions, as issues of synchronization, locking, etc. are much less of an issue.