CS 111 Lecture 10
Scribe Notes for 2/10/16
by Konrad Niemiec, Avik MohanSynchronization
We found last lecture that we have correctness using spin locks, but we don't have the performance we really want for our threads. We need some way to speed up this process.
Problem/Solution for Spinlocks
Problem: If multiple threads are waiting on the same resource, then the processor will spend a lot of time spinning, and not devote enough time to the threads that are actually doing the computation and using these resources.
Solution:
One thing we came up with in last lecture is using co-operative multitasking and have the threads call yeild() in order to . This technique is called polling, but it isn't good enough. The processor still schedules processes, context switches in, and then just context switches out. In reality, we want something that will render the thread inactive until it can actually be run. Thus we can also think of another solution, where we generalize the lock to have more information for the kernel. And that solution is...
Blocking Mutexes
We have a possible solution using blocking mutexes. By including more information with the lock we can tell if it is locked or not, and perhaps take passive action instead of looping. We also have a member to see who is waiting for this lock, in order to wake them up when the lock is released. We still include a spin-lock here, but only to control access to the boolean and waiting pointer, rather than waiting on the protected resource. The code for the struct bmutex follows below, as well as the code to aquire the lock.
1 struct bmutex {
2 lock_t l; // controls access
3 bool locked; // am I locked?
4 struct proc *waiter; // process/thread table entry of who's waiting for the lock
5 };
6 // PRECONDITION : assume the calling thread does not have the bmutex lock
7 void acquire(struct bmutex *b) {
8 lock(&b->l);
9 if(!b->locked) {
10 b->locked = 1;
11 unlock(&b->l);
12 return;
13 }
14 // pretend struct proc is a node of a linked list
15 curproc->next = b->waiter;
16 b->waiter = curproc;
17 curproc->locked = true;
18 unblock(&b->l);
19 yield();
20 return;
21 }
For the aquire() call, we assume that in the process table, each process has a member named next which points to the process waiting on it when the lock is released. We also assume the process entry has some flag for blocked, so the the kernel does not schedule it. But upon further inspection this appears to be a greedy wait, pre-empting any other process waiting. We could fix this by traversing to the end of the list and adding ourselves to the tail. Code for release is shown below.
1 // PRECONDITION: assume the calling thread has the bmutex lock
2 void release(struct bmutex *b) {
3 lock(&b->l);
4 b->locked = false;
5 if(b->waiter) {
6 b->waiter->blocked=false;
7 b->waiter = b->waiter->next;
8 }
9 unlock(&b->l);
10 }
What if we wanted to make our critical section smaller? We want to follow the Goldilocks principle and only include critical writes, and only encase code around that that needs to happen at the same time. After a closer look, if another thread looks at w->blocked at the same time, it works either way whether it reads blocked as true or false, so that can be done outside of the critical section.
1 void release(struct bmutex *b) {
2 lock(&b->l);
3 b->locked = false;
4 struct proc *w = b->waiter;
5 if ( w ) b->waiter = w->next;
6 unlock(&b->l);
7 if( w ) w->blocked = false;
8 }
Now suppose you have a resource you want to share amongst two or more threads. A blocking mutex is good for exclusive access to an object, but what about other resources that might be shared? For example, what if there was database client with up to 10 open connections, and each time we service a client we have to block. Blocking mutex is TOO restrictive in this case, we want more flexibility in these cases with resources that need multiple people with access. And that solution is...
Semaphores
The operations on Sempahores are shown below. Semaphores can either be a integer or a boolean, which we would call a binary semaphore. The advantages to an integer are what we mentioned above, that multiple readers for example can have access to a resource, but it is more complex. Some examples are shown below, all of which should be protected by a binary mutex if we are running multi-threaded.| Operation | Representation | Code/Psuedocode |
| Init | N/A | sem_init(&ptr,navail) |
| Aquire | P(sem) | if (navail > 0) navail--; block if (navail==0) |
| Release | V(sem) | navail++; |
Using Semaphores to Implement Pipes
Problem: If a pipe has multiple readers and multiple writers and they each need access to the pipe, there will be CPU time wasted context switching and checking only to go back to block. The operating system doesn't know why the threads want access to the pipe, just that they want access. So this still wastes CPU time with writers constantly polling. We need to tell the operating system exactly what the processes are waiting for before making them active again. That way we don't have to poll anymore
A solution to our problem needs to contain these things:
- Conditional Variable
- Blocking Mutex
- Ability to block until a case is true
- Relate our aquire case to the conditional variable
- Represent our conditional variable as a single variable for the OS
Solution:
Represent the conditional variable as an expression, which in our case needs to include:
p->w - p->r != 1024
The code is shown below, properly solving our problem.
1 struct pipe {
2 char buf[1024];
3 unsigned r, w;
4 condvar_t nonfull, nonempty;//These are our conditional variables
5 bmutex_t b;
6 };
7
8 void writec(struct pipe *p, char c) {
9 acquire(&p->b);
10 while(p->w - p->r == 1024)
11 wait(&p->nonfull, &p->b); // b must be acquired. releases b, waits until condition satisfied, reacquires b
12 // inside call to wait is a gap in the critical section, you no longer have exclusive access to the object
13 p->buff[p->w++ % 1024] = c
14 release(&p->b);
16 // not critical
17 notify(&p->nonempty);
18 }
Here, wait is the most heavy wait call in this function. The call to notify() says hey anyone waiting on this condition can now wake up. But wait can also lose the lock, so you need to be careful. In terms of speedup, blocking mutexes with conditional variables atop spinlocks achieve good levels of effeciency, but what if we don't want to block? We can try to get faster, and look to lower level speedup.
Hardware Lock Elision (HLE)
Often we have two threads that want to acquire the same lock, but read/write to different locations. One possible way to improve this would be to give each thread their own lock, which protect them from other threads, but not from each other, since they don't interfere with each other. Often it is difficult to detect if thread will interact or collide with eacother. When we don't know how to do something, often we turn to the hardware guys, thus we have a potential solution with the concept of a "transaction" within HLE in order to have atomic behavior at the hardware level.
CPU's issue a start transaction instruction, then perform any neccisary computation. After they are done executing things in the critical section, the CPU issues a end transaction instruction, which returns a boolean. If end transaction returns true, it means that there were no issues. If it returns false, it means that some other thread issued the same instructions in the meantime, and all those changes are now discarded. It saftley impelements critical sections, and the assembly code will often loop until the end transaction call returns true.
An x86 example follows:
1 lock:
2 movl $1, %eax
3 try:
4 xacquire lock xchgl %eax, m [start transaction]
5 cmp $0, %eax
6 jnz try [end transaction retry if false]
7 ret
8 unlock:
9 xrelease movl $0,m
10 ret
This works the same as lock(&l); x++; unlock(&l);
With a small amount of instructions, HLE performs:
| 6x faster on a multi-threaded machine. | No need for blocking |
| 2x slower when singly threaded | Due to false alarms. |
Finally now lets use what we learned to write between pipes!
1 bool copyc (struct pipe *p, struct pipe *q) {
2 bool ok = 0;
3 acquire(&p->b);
4 acquire(&q->b);
5 if (p->w - p->r != 0 && q->w - q->r != 1024) {
6 q->buf[q->w++ % 1024] = p->buff[p->r++ % 1024];
7 ok = 1;
8 }
9 release(&p->b);
10 release(&q->p);
11 return ok;
12 }
This code looks like the system call:
n = read(0,buf, sizeof(buf));
write(1, buf, n); And uses the semaphores we discussed earlier.
But deadlock could occur if we are locking two pipes!
Deadlock
Deadlock is the situation where threads hold locks in an order that makes them wait forever. I.E., Thread 1 holds lock A is waiting for lock B; Thread 2 holds lock B is waiting for lock A. There are 4 conditions for deadlock:
- Circular Wait
- Mutual Exclusion
- No Lock Preemption
- Hold Lock & Wait
And 3 possible solutions:
- Loop detection by the O.S., but this will make locking a syscall, which would complicate things
- Coarser locking surrounding the individual locking operations
- Lock Ordering
Lock Ordering is the most simple and most practical of the 3 solutions. By simply establishing order, i.e. locking the lowest pointer value first, and making sure all other threads adhere to that order, you prevent out-of-order locking, and thus deadlock. Other issues however do arise despite solving deadlock.
Priority Inversion
This issue plagued the Mars Pathfinder mission, where a priority inversion situation arose. Meteorological data gathering was a low priority thread, that sometimes locked a resource needed for the high priority information bus. A medium priority communications task could interrupt the low priority task however, making the high priority task wait even longer. In this case, it set off a 'watchdog timer' and caused a total system reset.
See:
http://research.microsoft.com/
In general, we can have a priority inversion issue when a low priority and high priority process lock on the same resource. If the low priority thread locks, then is interuppted by a medium priority thread, it can lead to long waits for the high priority thread and other more complicated issues.
Livelock
We can look at a similar problem, livelock, using packets. Assume we have a system where receiving a new packet or data point causes an interrupt.
If we are receiving a bunch of packets at a fast rate (the packet-generating host has a faster CPU than the receiving CPU, perhaps), we may get caught up in servicing these interrupts, to the point where no actual work is done. A good analogy is meeting someone in a narrow walkway, and you both try to move aside but you end up swaying back and forth without going anywhere.
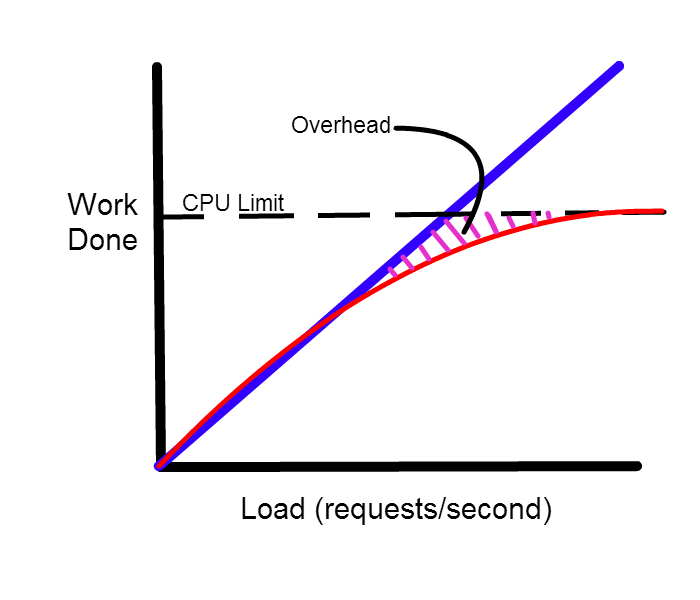
We can approach the ideal 1 to 1 ratio (blue), but overhead limits our actual work done (red). We still do a pretty good job, however. Now, we look at how receive livelock affects our system:
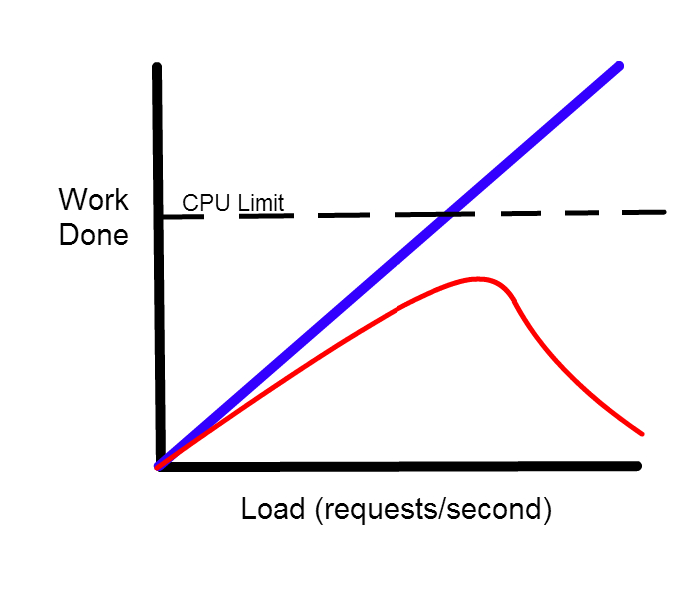
See:
https://cs.nyu.edu/rgrimm/
http://stackoverflow.com/
http://www0.cs.ucl.ac.uk/
This is a bit complicated...
All of these issues add up to create a sitatuion where we pay the cost of high complexity to get things to go a little faster. We have to imagine that there would be some other option availible. This option is to use event-driven programming.
The general principle behind event-driven programming is that primary activity is a reaction to the receipt of certain significant signals, i.e. events.
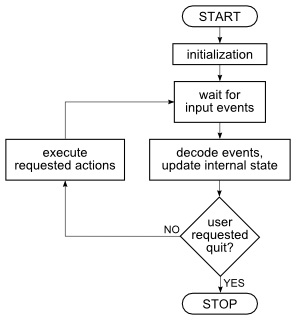
Source: http://library.morph.zone/
Event driven programs are the 'inverse of threads'. They are single-threaded, shared memory programs that we can divide up into callbacks. Callbacks are functions passed as an argument to another function, which are used to process the current function's results; They are triggered by the 'return' event.
Each of the individual callbacks finish fast, with no need to lock on any resource. Nothing ever yeilds, only returns. Additionally, we use slightly altered I/O instructions, coming from the the POSIX AIO (Asynchronous I/O) interface. This allows for deferred work, that can be verified later, by adding a layer of indirection. That means we don't use things like 'getchar', 'waitpid', or similar commands where we might wait on a pipe.Event-driven programming does have its share of issues, however. It generally requires more complicated code, with a less obvious flow of execution. Callbacks tend to obfuscate the natural sequence of execution. It is also ill suited to simpler programs, due to the increased complexity and bulk of the code.
Background Image Source: http://www.designbolts.com/