CS 111 Lecture 11: File System Design
Winter 2016 Week 7 - 02/17/2016
Scribe notes written by Aaron Chong
Let’s consider a sample file system. This system has 120 PB, composed of 200,000 drives, of each about 600 GB. Why do we pick small drives?
- The file system was originally designed years ago
- Smaller drive is faster
The file system used is called: GPFS – General Parallel File System.
It was developed by IBM, and is designed to operate as a single-file system built with a lot of drives.
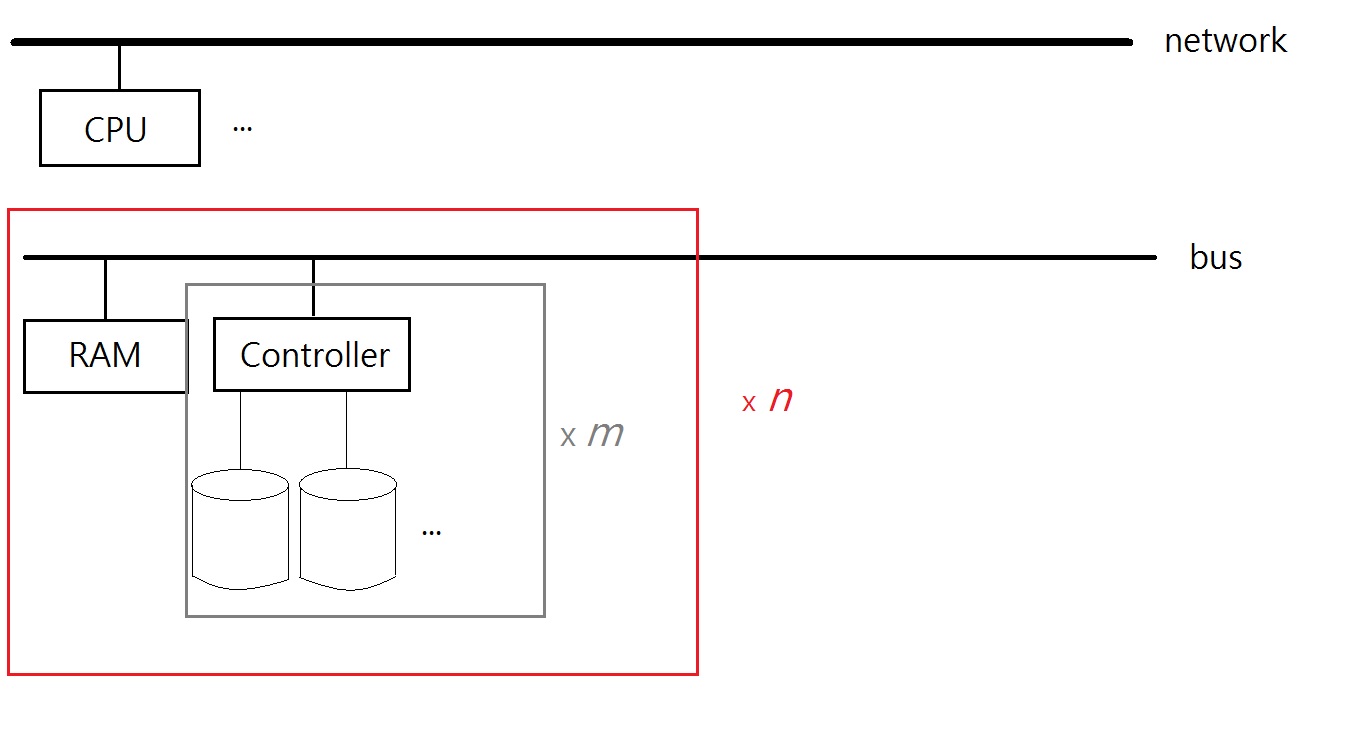
The m controllers each can control limited number of disks, to avoid bus overload.
But how can we put together that many CPUs over the network efficiently? Large file system turns into a networking problem which is out of our concern.
Some common tricks used by file systems:
1. Striping
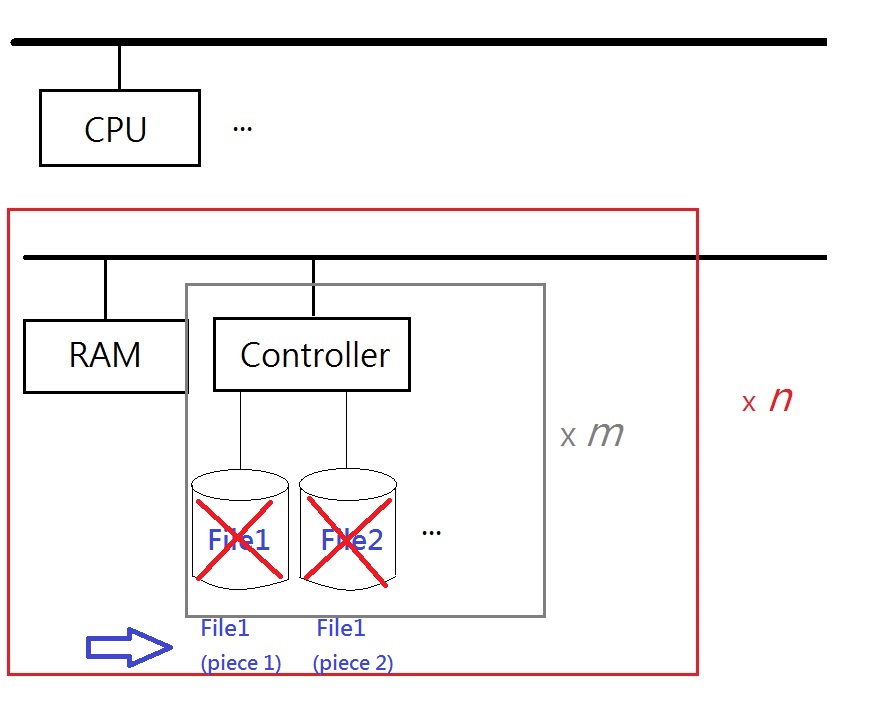
Instead of storing the complete files in disks, spilt them up and store file pieces on different disks. This is a standard trick in file systems that use parallelization for faster throughput.
e.g. If each disk drive can output several MB/s, splitting a file into pieces and tell all different drives to return the corresponding piece in parallel would result in a faster read.
2. Distributed Metadata
Metadata is a part of your file system that is about the data. It contains information about the file (e.g. directories, timestamps) other than the actual file data.
e.g. Hadoop distributed file system
Many of these systems have centralized metadata, if we want to find out a particular file (it may be scattered across the network), we have to communicate with its controller. One disadvantage of this kind of system is that it can lead to bottlenecks when many users want to access the same file at the same time.
However, GPFS allows multiple CPUs to be in charge of the same file at the same time!
3. Partition Awareness
Suppose we have a network, some CPUs and some clients.
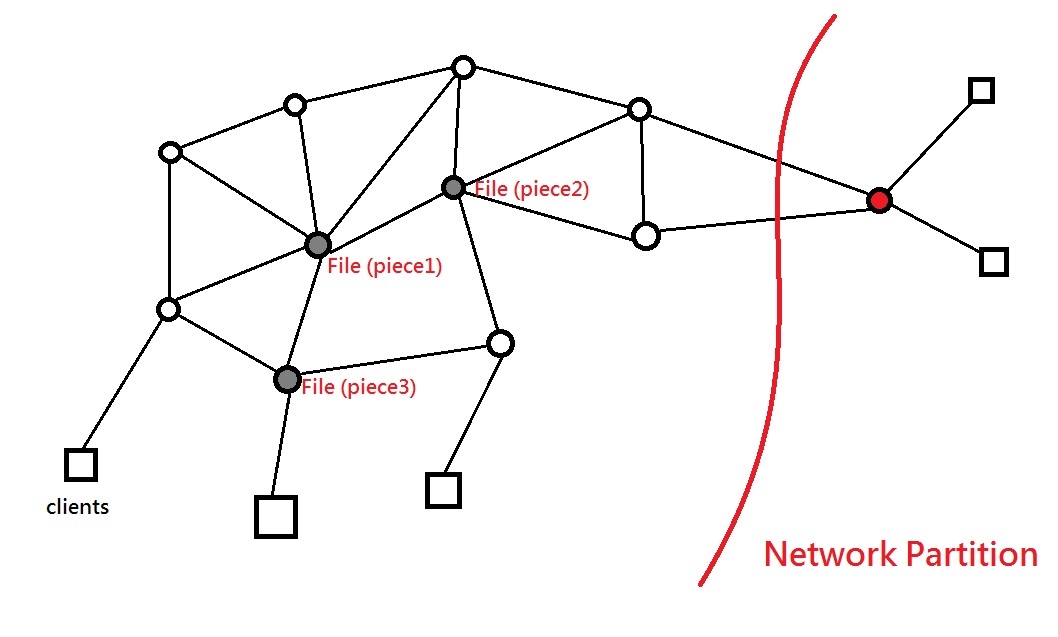
One most common form of network partition is that one client is cut off from the rest of the network. A conservative solution would be stopping the whole network. However, users would like to get their work done despite of the situation (e.g. file pieces are all available on the user’s side).
GPFS gives this kind of awareness. When the network partitions, the clients and the servers know about the partition, so that they can still operate and make progress under the condition that all the data in interest is on their side of partition.
4. Distributed Locking
If we want exclusive access to a file to change it, and make sure that nobody else is reading/writing it at the same time, a lock would be required.
GPFS allows user to grab a lock and write to a file, while other users can grab another lock of another section of a file.
5. Efficient Directory Indexing
Suppose we have a single directory with a million files in it, the traditional way is to have an array to represent all the file entries. Then we want to look up a file entry, should we do a sequential search?
GPFS uses a fancier data structure, to have efficient indexing even when there are distributed directories over the network.
6. File System Stays Live During Maintenance
In GPFS, a common maintenance action is that if files are distributed poorly for the current access pattern, we would like to move data closer to the clients. When we are cleaning up or re-organizing the file system, users would still be able to read and change their files.
Definition of a File System:
A file system is an abstract organization of data on secondary storage
How Abstract? Being able to read, write & rewrite, move, delete, allocate space for data.
For searching, it is controversial and only allowed by some file systems. Although it can be more efficient, it is difficult to come up a standard way for searching (e.g. regular expressions).
Properties of Secondary Storage: slow (mask this if possible), big, persistent (able to survive program crash, OS crash, power outage, hardware damage)
Professor Eggert’s File System (1974)
Specifications:
16 KB RAM
700 GB Disk
512-Byte Sector
Word Address-able
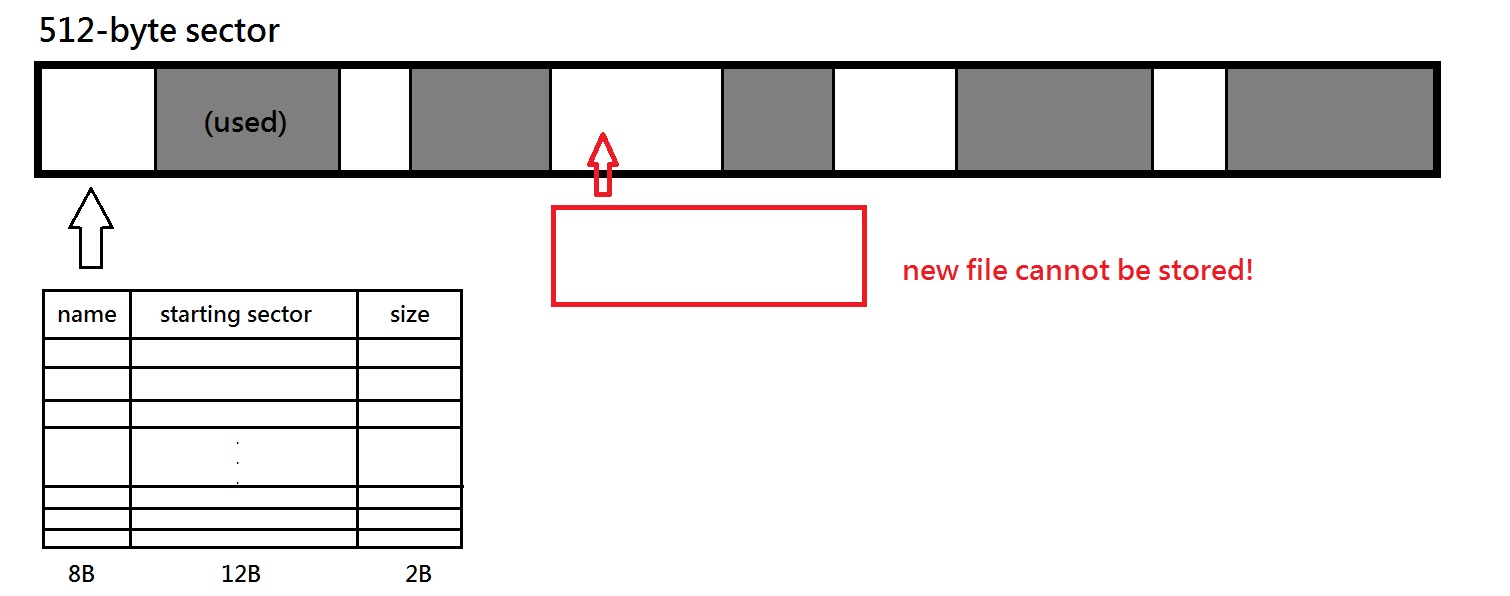
- The first part would keep track of where all the files are, using a table with 3 columns (name, starting sector, size in bytes).
- Name field is zero-filled by adding ‘Null’ to make it exactly 8 bytes.
- We have 12B for the table, 4B for timestamp, in total 16B (a power of 2).
- We have 2^5 directory entries per sector, which means that we can have at most 2^6 total files.
- If the Name field is all zeros (file names have to be at least one byte long), that means it is not in use.
Advantages:
- Simple
- Sequential access is fast
- Sequential access is predictable
Disadvantages:
- Number of files limited by code (this is not true for RT-11)
- Internal fragmentation up to 511 bytes
- No permission
- Preallocation required
- External fragmentation (fatal problem!) (we may have enough storage space to store a file, however, we may not be able to do so because files can only be stored continuously, leading to spaces wasted)
This file system is similar to: RT-11 (developed by DEC in 1970)
The reason why they implement the file system in this way for real-time OS is because of predictability and simplicity. If we want our application to have predictable performance, sequential access performance should be predictable.
FAT File System (1970s)
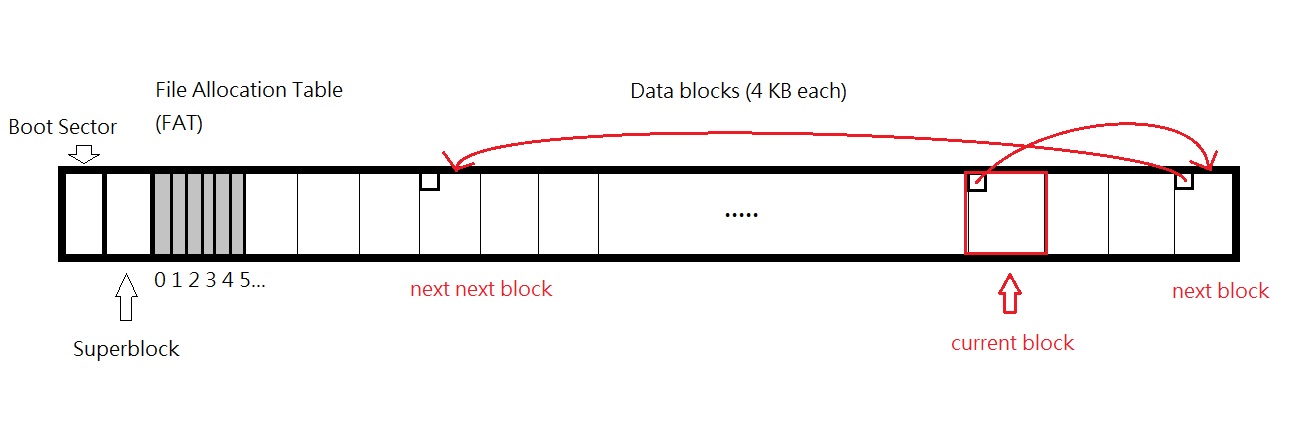
Boot Sector
The first sector (index 0) is the boot sector.
Superblock
The superblock contains information about the file system, e.g. version, size (number of blocks allocated), used count (number of blocks used), etc.
File Allocation Table (FAT)
Since blocks are not stored continuously, the next block can be anywhere in the disk. Therefore, we need to have a linked list of blocks to indicate the position of the next blocks. Instead of putting the pointer into the block (say FAT16, 2B is required for the pointer, leaving only 4046B for data), we put all the pointers into the File Allocation Table (FAT).
FAT is an array of block numbers, indicating the number of the next block in the file. If the entry is 0, it indicates EOF (end of file); If the entry is -1 (2^16 -1), it indicates that the block is free to use.
How much data can be stored in FAT16?
(2^16 -2) * 2^12 = 2^28 = 256 MB, which is large enough for all kinds of disk drives at that time
// -2 because ‘0’ is for EOF, ‘-1’ for free
Similarly, for FAT32,
It is approximately 2^44 = 16GB, which may not be large enough for the disk drives nowadays.
BIG IDEA: DIRETCORIES ARE FILES
The directory is an array of directory entries.
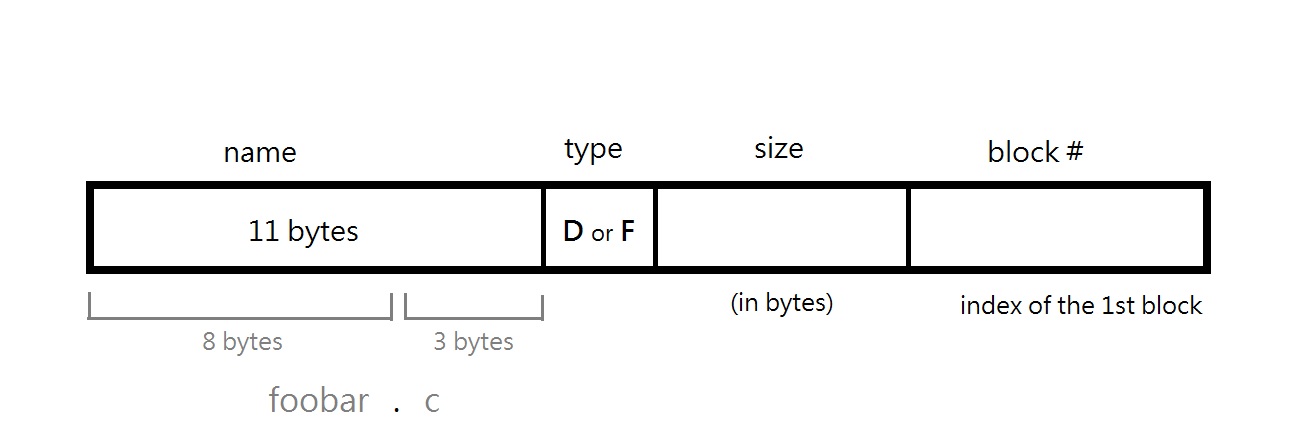
- Each file contains a name, type (File or Directory), size (in bytes), block number (index of the 1st block in file)
- For the file name, 8B is used for the name and 3B is used for the extension. The dot ‘.’ is not stored, i.e. we can have foobar.c but not c.foobar, and it is also impossible for us to have a file name of a.b.c.
Advantages:
- No external fragmentation
- No preallocation
- Number of files is not limited by file system
Disadvantages:
- Sequential access can be slow
- Defragment is slow and tricky
- lseek requires O(N) of time
Suppose we would like to rename a file in a FAT file system:
mv foo.c bar.c
Renaming a file in the same directory is easy to do so, we just have to find the block containing this directory entry, read this block into the RAM, then just change the foo.c to bar.c. If we crash in the middle of operation (e.g. power is being cut off), no harm done as long as the read/write of blocks is atomic.
mv a/foo.c b/foo.c
However, there would be a potential trouble when we want to change two blocks. In this case, b should be written first to avoid the loss of data. However, if the system crashes at the time after b is written, we will now have two directory entries both pointing to the same file. Later on, if we remove a/foo.c, the block pointed by a would be cleared and b/foo.c would be loss.
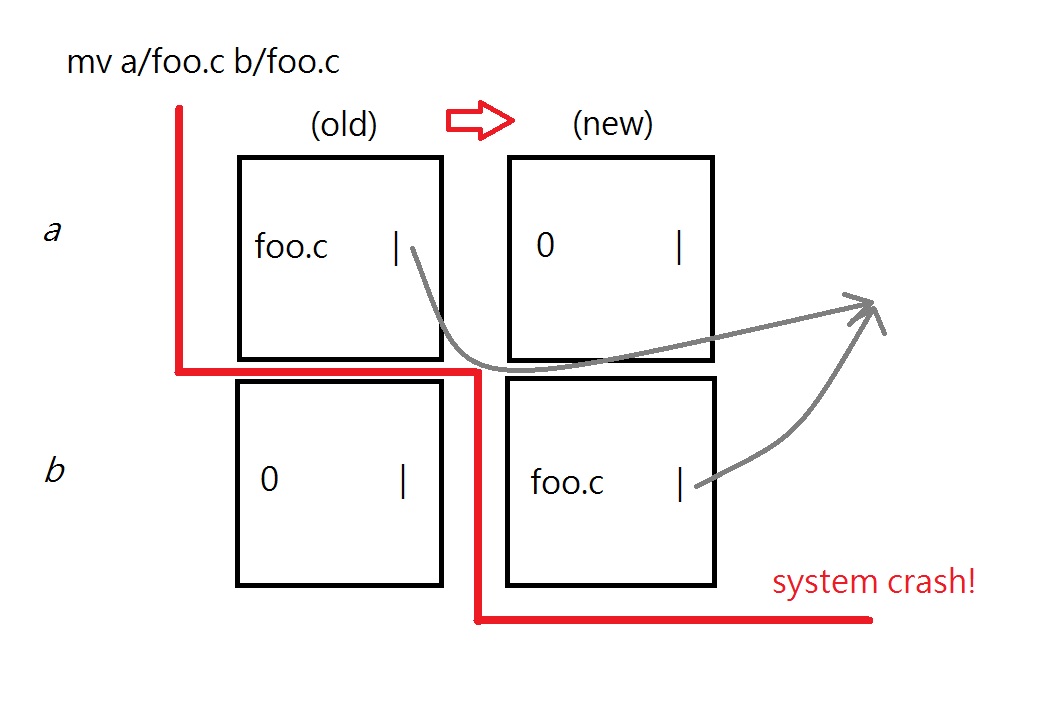
The original FAT design in Windows addressed this problem by telling the user that this command is not implemented!
