File System Continued
CS 111 Lecture 12 (2/22/16)
By: Andy Kuang, Patrick Deshpande, Rishub Kumar, and Stan Jiang
Hybrid Data Structure
File Systems exist in main memory and on disk
- Persistence (Disk)
- Performance (RAM)
Now let's look at how different file systems handle directories. The RT-11 just has a base directory while the FAT has a tree structure where directories are nested within eachother
Linux Ext3 File System
Directory Entry Structure
- 32-bit inode number
- 16-bit directory entry length (where the next inode starts)
- 8-bit name length
- 8-bit file type
- 10-byte file name
As we can see, there are varying length entries.

Why is Directory Entry Length so big (16-bit)?
When ext3 wants to delete a directory entry, it just increases the record of the previous entry to the end of the deleted entry.
unlink("foo.bar")
- lets you remove directory entries
- 16-bit so it can overwrite the next entry, thereby deleting that file entry
link("baz", xxx)
- goes through the list and finds and entry with sufficiently large number to fit the new file
The 0th inode entry is left empty so it doesn't need to be unlinked since there is no preceeding inode entry that can overwrite it.
Inode: in main memory and on disk, contains metadata for file:
- an array
- cached version of what's on disk
- fixed size
- contains number, no names
- 0 means that the file doesn't exist, starts at 1
Inode structure:
- owner (32-bit)
- timestamp (last modified time)
- access time (mtime, sysclock)
- inode change (ctime)
- permissions
- file type (directory/regular file/...), which is in both inode and cached directory entry
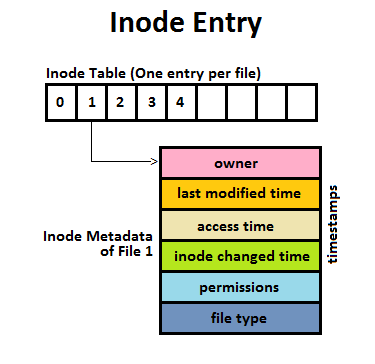
Inode refers to the info of the file and a Directory Entry refers to the info of the name of the file.
Why cache type and not other?
- Type cannot change: inmutable
- Other data can change
Inode does't tell you the file name
- File name built atop inode
- Levels of abstraction in file system
Removing Files Securely
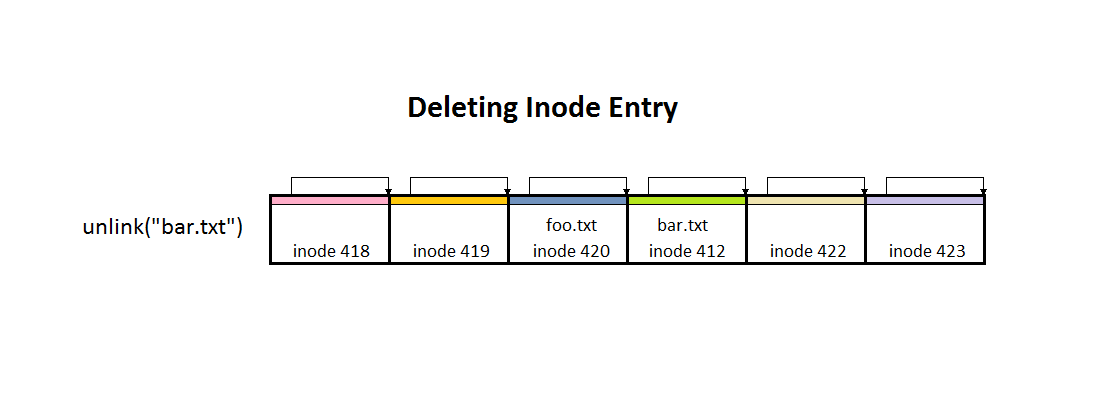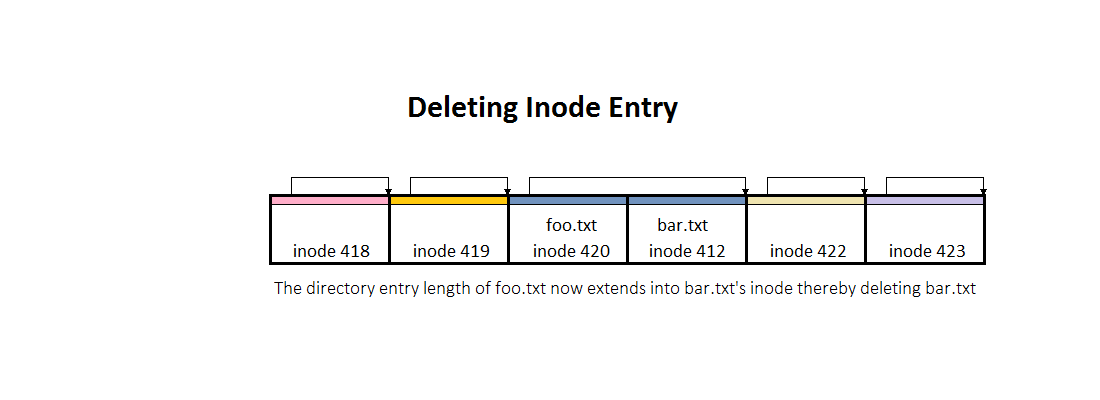
unlink("foo.txt") removes directory entry, or in other words it removes a link to a file (note rmis implemented with this sys call)
- The link count to foo.txt could still be nonzero, meaning we have not removed all references to foo.txt
To get the link count for a file, we would do the following:
$ touch secret
$ chmod 600 secret
$ ls -l secret
There are a couple problems with using unlink to remove a file. First, file permissions are checked at open time. Second, storage for a file with a link count of zero is not reclaimed if a process has a file open. This means a program could hog a file, preventing it from ever being removed. Thus, we look for a better way to securely remove a file, implemented by the shred program.
Removing a file using shred
$ shred file
This is the algorithm that shred uses to remove a file:
- open file
- stat sys call to get size of file
- overwrites file with random data (3 times)
- closes file
- unlinks
However, even shred is vulnerable. Lets take a look at how the root can defeat shred
How root can defeat shred, and mechanical failures
In root we can read from any directory at any time
/dev/rdisk/00
- block special device
- can read from shredded file's original sector
$ shred /dev/rdisk/00
- erase all of disk
- bad sectors, hardware substitures bad sector with replacement sectors (linked)
- bad sectors may still contain sensitive information that cannot be overwritten
Problems can also arise on the hardware side. The problem is that disk drives are not completely reliable. A mechanical error can result in the disk arm missing the target, of course meaning that some of the original data is still there. Furthermore, it is possible with specialized tools to detect the 'history' of a location on disk, meaning we can see the previous value that was stored on disk. These problems greatly complicate what might seem like the simple task of securely removing a file.
Note on file locks in linux
File locks in linux are voluntary. This is to prevent programs from holding locks, which would prevent other programs from accessing files.
How To Interpret File Names
The name of a file is related to a number that refers to the place from the root of the directories.
An example of this is
namei : a/b/d -> 12963 (12963 is used to reference a/b/d)
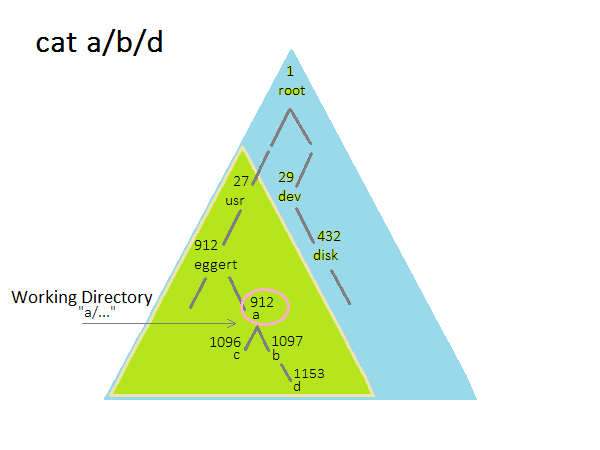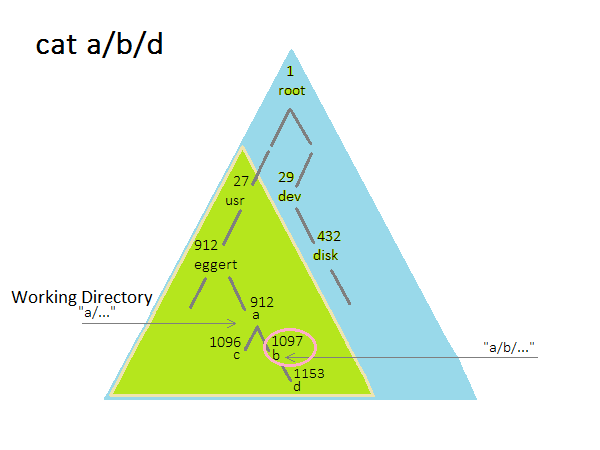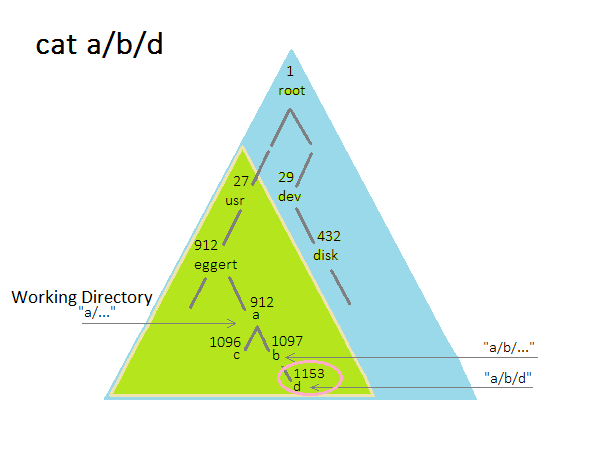
The command cat a/b/d will start looking in the working directory to find the file.
If you want to search starting from the root, use a "/" at the beginning.
- e.g. cat /etc/password
Each process has a working directory that is stored as an inode number in the process table entry.
- You can change the directory using chdir("x")
- Similarly, you can change the root directory using chroot("y")
chroot("subdir")
- This is called a chrooted jail. The idea is that the process is not isolated from the rest of the system, which should only be
used for processes that don't run as root. As far as the process knows, the only files on this file system are those that can be found
in "subdir". As a consequence, commands such as execl("/bin/emacs", ...) would not work because emacs would not be able to access root, only subdirectories.
Directory Rules
- abc/. ≡ abc
- /a/b/.. ≡ /a *Note that this is not always true
- /.. ≡ /
Get Out of chroot'ed Jail
ln /usr/bin/emacs subdir/bin/emacs
ln /dev/tty subdir/dev/tty
ln /dev/dsk/00 subdir/dev/dsk/00
open /dev/dsk/00 //for RW
ln {some other file to accessible location}
Symbolic Link Loop
What happens when you link a file to another file which links back to the first? You get into a symbolic link loop, as can be seen in the following gif.
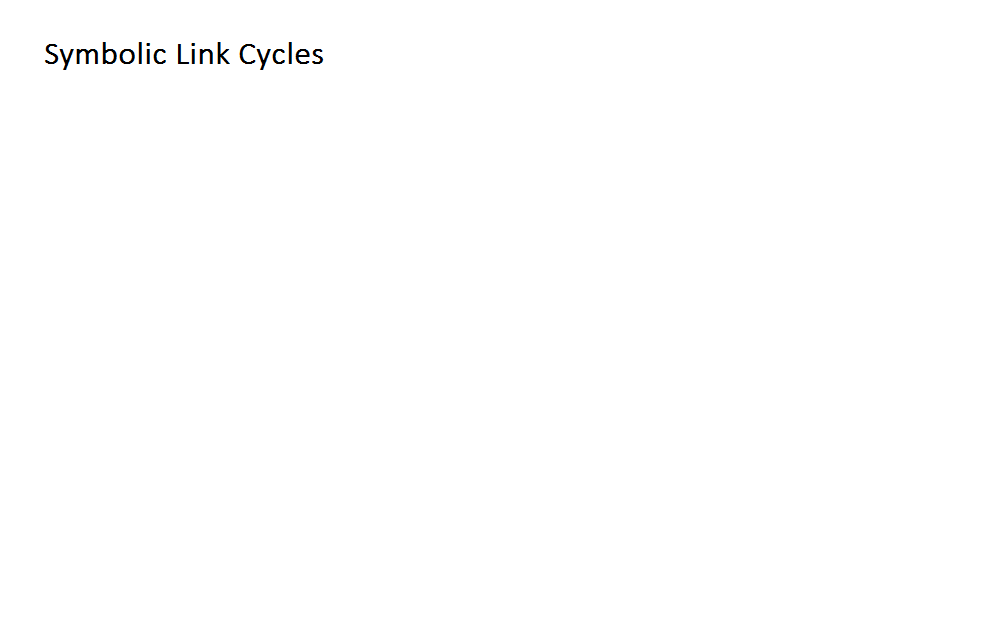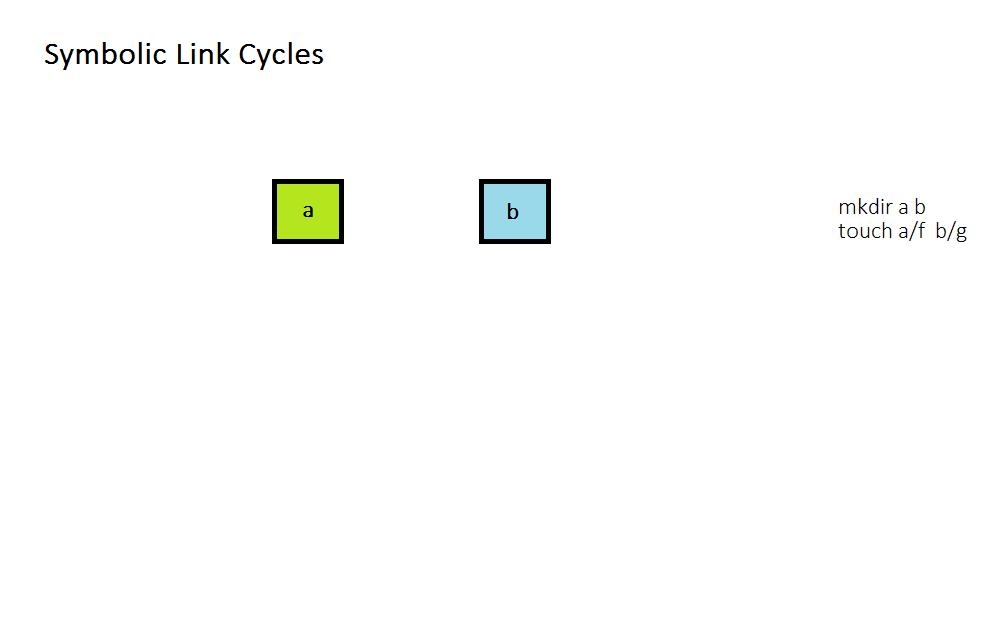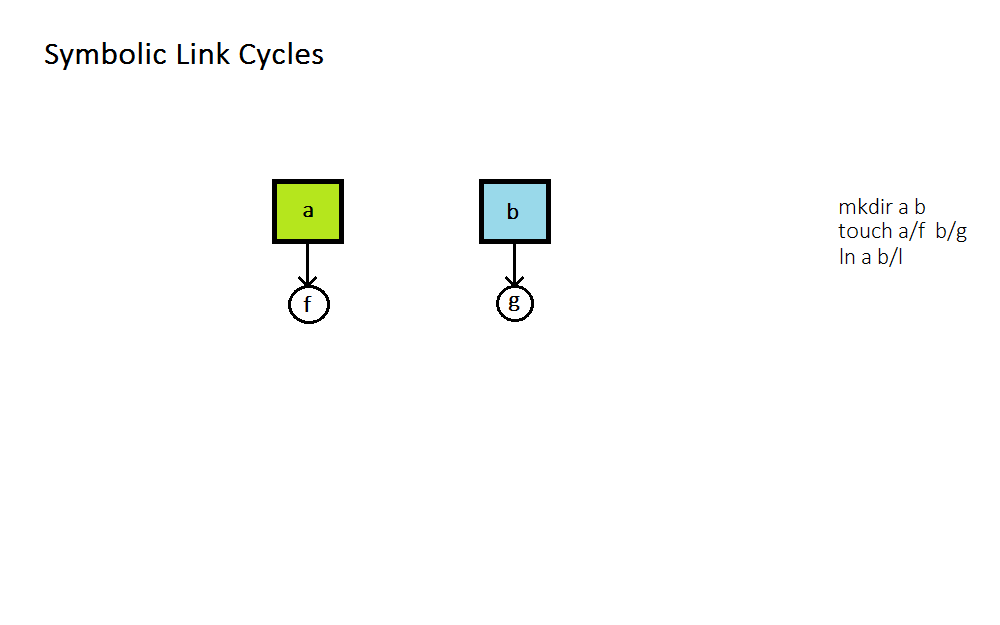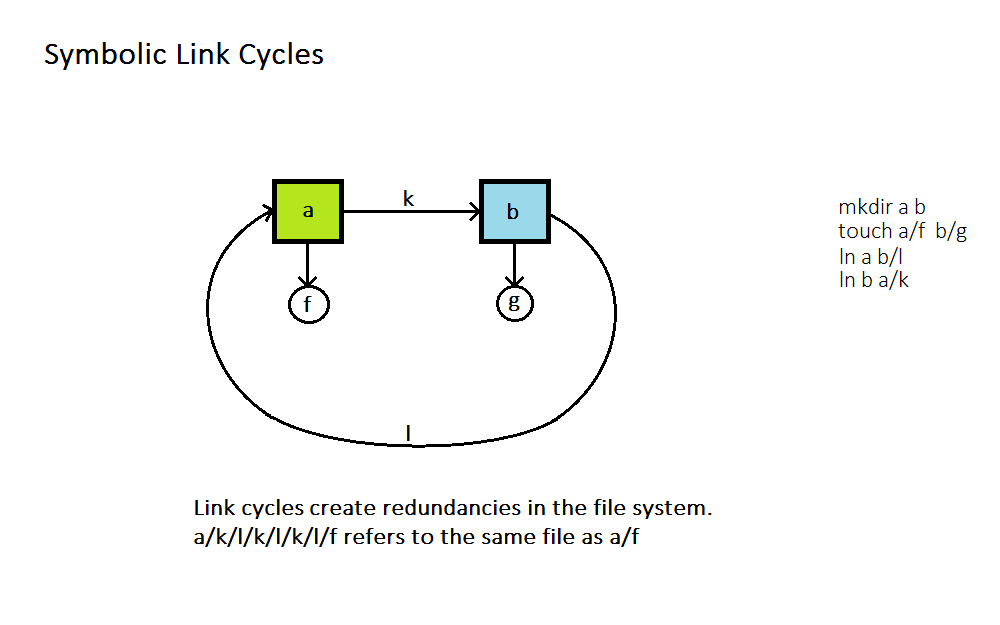
Some file systems allow symbolic link loops, but Linux does not because that is the simplest solution. Why?
find command loops infinitely (this can be fixed: whenever it visits a new directory, see if that directory is in its chain). However, we could argue that this is a problem with the find command itself. So what other problems are there?
Imagine we now tried the following code:
rm a/f
rmdir a/k
rmdir a
This would not work because rmdir a cannot properly recover storage due to the symbolic loop link as the link counts don't suffice.
What about this code?
unlink("f")
rmdir("k")
This code does not work because the loops prevent rmdir from working, since others point to it. The OS fixes this problem by keeping a link count, which is a count of number of directory entries point at an inode. This doesn't suffice if there are cycles. So, assuming we call link("a", "b"), what should the OS do?
The OS could check for a cycle dynamically
- the problem is that the cost of doing a link would be very expensive
The simpler way: cycles are prohibited if "a" is a directory
- not allowing hard links to directories prevents all of the cycles we have been over because they involve multiple links to directories
Space Allocation for Files
Direct blocks
Indirect blocks
Doubly-Indirect blocks
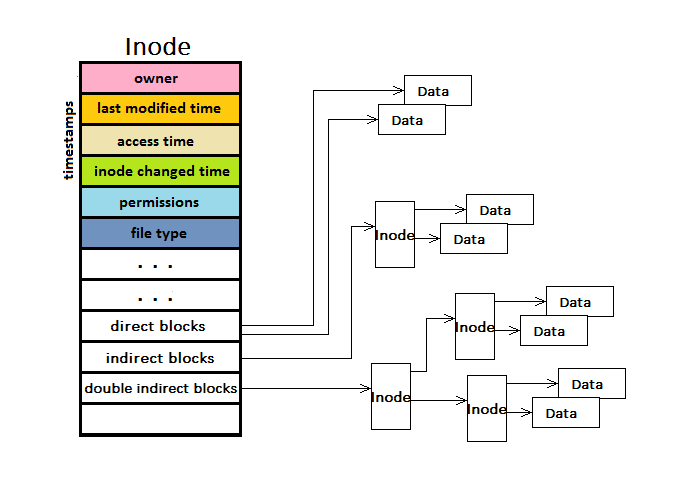
Indirect Blocks - 2048 * 8192 + 10 * 8192 = 16 mb
Double-Indirect Blocks - 2048 * 2048 * 8192 + 10 * 8192 + 2048 * 8192 = 2^35 bytes
Use lseek to find file data
- low fragmentation