Lecture 13: File System Robustness
UCLA CS 111 (Winter 2016)
by: Brian Li, Danny O'Laughlin, Gezer Domingo, and Jack Storch
Table of Contents
- Gzip Bug
- BSD File System Layout
- File Systems Performance Issues
- Improving Performance
- File System Invariants
- Gzip Bug Continued
Gzip Bug
We begin this lecture by discussing a certain bug report for gzip that Professor Eggert
received last Monday. Gzip is a popular GNU data compression program that takes a file foo
and replaces it with its compressed version, foo.gz. Here's the general idea of what gzip's code looks like:
ifd = open("foo", O_RDONLY); //input file descriptor
The bug report claims that this sequence of actions is unreliable because in certain cases there may be data loss.
Specifically, the bug report states that if the system crashes, from pulling the power plug or running out of battery, between the lines
ofd = open("foo.gz", O_WRONLY | O_CREAT | O_EXC | 0600); //output file descriptor
read(ifd, buf, bufsize);
write(ofd, buf, some_value_smaller_than_bufsize); //each time you read or write, check for errors
if (close (ifd) != 0) error();
if (close(ofd) != 0) error();
if (unlink("foo") != 0) error();
exit(0);
if (unlink("foo") != 0) error(); and exit(0);
there is a problem: data loss. This bug is very unlikely, but very common in many linux applications. We'll return to this bug later on in the
lecture. But first, in order to understand why this would cause a bug, we turn our attention to the layout of the Unix File System.
BSD File System Layout
One of the main goal's of the file system layout is quick storage allocation:
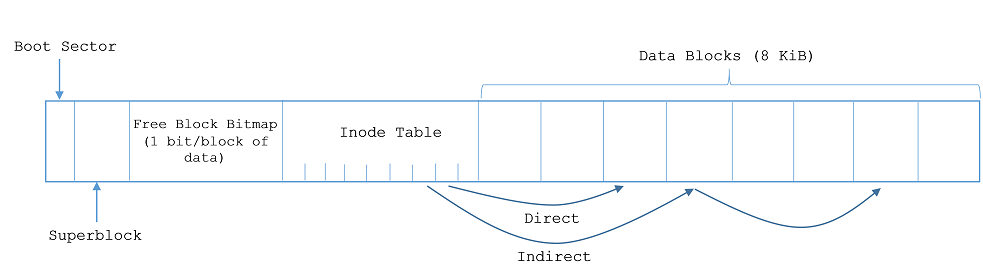
From this picture, we can see that one block is allocated for the free block bitmap. We can use the bitmap to find a free block, which is faster than walking through all the inodes. Since there's only one bit per block of data, only a small portion of the disk needs to be reserved in order to implement this behavior. The free block bitmap is also plausibly cacheable in RAM.
File Systems Performance Issues
There's significant overhead in reading a block from disk. Typically the overhead is caused by multiple factors. The time it takes to read a block from disk, denoted t, is given by:
t = seek time + rotational latency + transfer to disk time + transfer to RAM time
where:- seek time is the time taken for the hard drive to move the read head to appropriate cylinders.
- rotational latency is the time taken for the disk to rotate around to appropriate position.
t = 10ms (seek time) + 8ms (rotational latency) + 0.1ms (transfer to disk + transfer to RAM) = 18.1ms
We can do a lot in 18ms. In fact, since we can execute 1 million instructions per millisecond, in the time it takes to read a block from disk we could have executed 18 million instructions! Obviously, executing 18 million instructions is a more efficient use of time, so we would like to avoid talking to a secondary storage system altogether! How then do we measure the performance of a file system? I/O metrics.
I/O Metrics
There's three metrics used to determine the performance of a file system. Note that they are competing objectives, meaning an increase in one will almost undoubtedly result in a decrease in the second and/or third metric. The three metrics are:
- Utilization: the percentage of time spent reading or writing data. Utilization is measured in % or [0,1].
- Throughput: the rate of request completions. Throughput is usually measured in operations per second (ops/sec)
- Latency: the delay between request time and response time. Latency is usually measured in seconds (s).
Improving Performance
Now that we know some of the issues causing overhead as well as performance metrics, how do we improve performance?
- Batching: The general idea is if you have a number of individual writes to do, don't do them one at a time.
Instead, coalesce all small requests together into a big write and do that big write all at once. A classic example of
of batching is seen in the cat program, which looks something like this:
while ((c=getchar() != EOF))
putchar(c);
In stdio library, this code is silently turned into a series of something like:
read(0,buf,4096)andwrite(0,buf,4096); - Speculation: the more general approach of batching. Speculation works by guessing what your program is going to do in the near future and acting on this guess. In effect, with batching, the system will read a certain number of bytes of data, say 4000, because it is speculating that you're probably going to want to get the next character as well. In general terms, speculation is the act of guessing the future future behavior of applications and doing that work in the present. When you apply speculation to system reads, its called prefetching . This is because we are fetching more of the data than we really needed. When you apply speculation writing, its called dallying . When a write is requested, you save work by dallying, slowing down. When you call write, the data is cached in memory, but hasn't been written in disk yet.
Locality of Reference
There's two types of locality:
- temporal locality: location i accessed at time t is correlated with -> location i accessed at time t+𝛿
- spatial locality: location i accessed at time t is correlated with -> location i+ε accessed at time t
Use these concepts along with speculation to improve performance. Let's now take a look at the block layer.
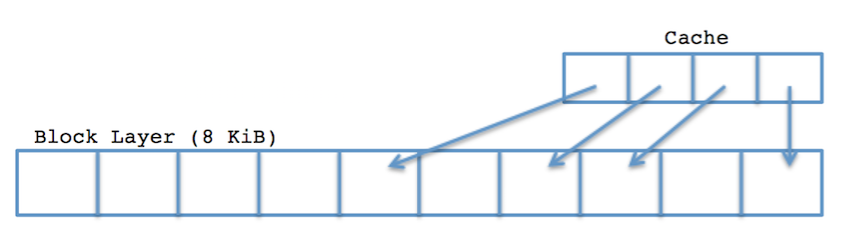
The block layer is a low level hardware feature that runs under the assumption that it is the only piece of the system that exists. That is, it has no knowledge of what runs at higher levels other then the requests it receives. The block layer also contains a cache that can keep commonly used blocks stored for fast access from higher level structures. This approach can get us good performance. But what if we want it to be even faster? Is there something we can do to help the block layer go even faster, other than giving it a cache? To answer this, let's assume we're building a file system on top of a disk drive:
Simple Model of Hard Disk Access
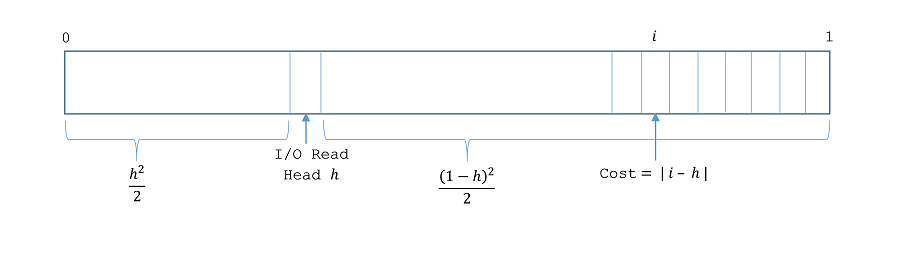
This the picture Professor Eggert drew in class. However, he told us that the integral for the average seek time that it yields may not be correct. He said that it was up to us to find the correct one. The correct integral is as follows:
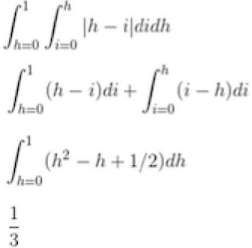
To maximize throughput, use SSTF (shortest seek time first), in which the work closest to the disk arm is done first. However, if there is significant
amount of impending work close to the disk arm, a potential problem arises: starvation. In other words, the disk arm could constantly hover around
a region that gets good service, while others could starve. Instead, a fairer algorithm is the elevator algorithm. This algorithm is a comprimise
in the sense that it is fairer than SSTF, but you don't satisfy requests in the order issued. Because of this, the elevator algorithm is popular. Another
algorithm based on the elevator algorithm is the circular elevator. This method involves always seeking forward on the disk and then going all the way back
to the start once the end is reached. This provides greater fairness as all requests will be taken within one full loop of the disk head but also causes
lower throughput as the read head must travel all the way to the beginning once it reaches the end. This is lessened though as the read head picks up a lot
of speed as it can accelerate all the way to the middle before slowing down.
Also, combining SSTF and FCFS (First Come First Serve) we can get a new algorithm by giving each request a score based off the formula:
(fw - | i – h | )
where w stands for total wait time, i stands for position of the request, h stands for the head position, and f is a scaling factor to turn wait time into distance for the purpose of the equation. The request with the highest score will be the next to be processed. This prevents starvation as if wait time gets high enough, even if the request is far from the head, it will at some point have the highest score and be chosen.
Issue with Renaming
What if we want to rename a file as follows rename(“foo”, “fuzzy”). This is an operation that uses several writes.
- First the system will locate the working directory’s inode number by examining the process table and reading into RAM
- The directory data is loaded into RAM and “foo” is found. “foo” is then changed to “fuzzy” in the directory’s data.
- At some point, we will write the cache to disk.
Using this method proves to be problematic. If there are multiple renames, and power loss is experienced in the middle of the operation, some files could get renamed while others are not. Furthermore, if a crash happens we could lose the fact that a rename was done in the first place. We could also experience a free space leak because the block bitmap could say that a block is in use when in reality it no longer is. Finally, we could encounter a situation where rename from one directory to another, but a crash causes the two directory entries to point to the same file. In this situation, the corresponding inode would only have a link count of 1. One way to fix this would be to temporarily increment the inode link count before the name change and then reset it after the operation is complete.
File System Invariants
When maintaing or using a file system, a record of important properties must always be kept on disk. File system invariants are statements that should always be true no matter what, even if the system crashes. There are many invariants, but with respect to file system, we focus on the following four BSD file system invariants:
- Every block is used for exactly one purpose. In other words, a block has the option of serving as the boot sector, superblock, bitmap block, inode table, or data block. It can never fulfill more than one of these roles.
- All referenced blocks are appropriately initialized according to that block's purpose.
- All referenced data blocks are marked as used in the bitmap.
- All unreferenced data blocks are marked as free in the bitmap.
Violation Penalties
- Violating invariant 1 results in disaster. More specifically, the kernel could crash, data could be overwritten, bitmap could be overwritten, etc.
- Violating invariant 2 results in disaster. More specifically, uninitialized blocks could cause the system to look at random data, follow null pointers, and in the worst case crash the operating system.
- Violoating invariant 3 results in disaster. More specifically, data in blocks not marked as used could be overwritten. Data loss is a condition for disaster.
- Violating invariant 4 results in a storage leak, but not a disaster. More specifically, unreferenced but marked data blocks may cause a decrease in efficiency and/or storage space.
fsck
This function can be used to recover lost files after a reboot. It works by looking through the raw device to find files that have link counts of 0 but are still marked as not free by the bit map. It then takes the bits found within these files and writes them to a file before putting all of the recovered files into a directory called /lost+found. Then makes these files only readable to root for security reasons.
Gzip Bug Continued
Let's now return to the bug in gzip. The reason for the potential loss of data is due to the fact that the disk will process requests out of order in most cases. This will sometimes cause the unlink to take place before the writes which is not bad in most cases, but if the system crashes before the writes take place and after the unlink then all of the data will be lost. There is however a fix being uploaded to the next version of gzip. To fix the bug in gzip, the statement:
If(fsync(ofd) != 0)
Error();
Should be added right in between the two file closings. The fsync function forces the hardware to actually run all of the writes before unlinking the file. This way the file cannot be lost if a system crash occurs before all the writes have processes. Although this slows the program considerably, the safety of knowing your data is safe is sometimes worth the performance hit. However, this could be made to be much faster if the system simply knew that all the writes must be done before the unlink. This way the function could run other processes instead of the writes but avoid the potentially fatal unlink. Currently, there is no way to tell the kernel to do this.
Back to Top