Name: Hovhannes Menejyan
We started the lecture by talking about the bug that has been found in Gzip. Professor said that Gzip is a badly written program.
ifd = open( "foo", O_RDONLY);
if(ifd < 0) error ();
ofd = open ( "foo.gz", O_WRONLY | O _CREAT | O_EXEC, 0600);
if(odf < 0) error();
read(ifd, buf, bufsize); //check for errors in this and next line, report if any found
write(ofd, buf, …);
//before finishing the job
if( close(ofd) !=0) error();
if(close (ifd) !=0) error();
if( unlink ( “foo”) !=0 ) error();
exit (0);
The bug report stated that sequence of actions in this code is unreliable, and in some cases Gzip may lose all data.
If the system crashes before the exit(0) call, it is possible to lose all our data.
So we checked everything and made sure to catch all errors, but there is still a risk to lose all our data? Why?
We will come back to this problem later.
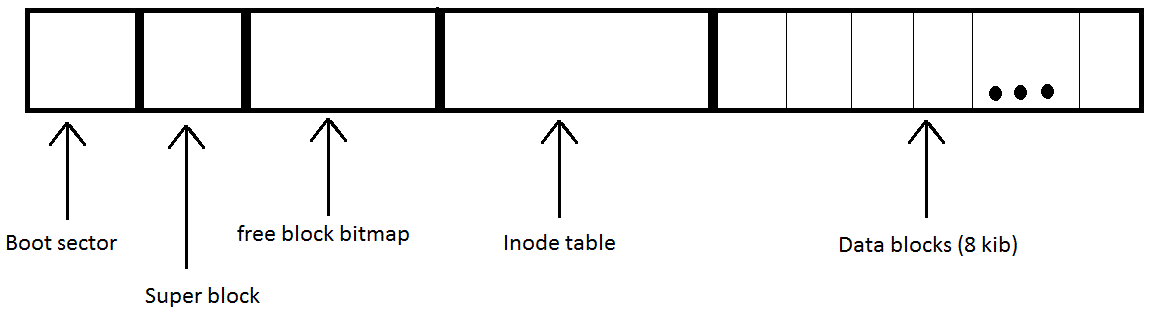
When the OS needs to allocate more space to file, it needs to mod inode to point to data directly or indirectly.
In theory, to do this, we can find an inode not in use, take everything reachable and we will know which ones are free.
In practice, this is too slow. Instead we use bitmap, 1 bit per block of data, so when we need to allocate a block, we
go look for it in bitmap, find a free one, allocate and then modify the bitmap to indicate that it is in use.
So the ratio is 8192 * 8=65536 : 1 for free block bitmap. Bitmap is also easy to fit in ram, and this is basically
the point, to gain performance.
If we want to get a block of data from hard drive, how long will it take? Overhead to read
a block from disk = seek time + rotational latency + transfer from disk + Transfer to RAM. Typical time = 10ms + 8ms + 0.1ms.
So it adds up to about 18ms , and note that on modern computer, 18 ms is enough time to carry out about 18 million instructions.
1) Utilization: What % of time are you reading/writing data ?
2) Throughput: Rate of request completion (in operations/sec).
3) Latency: Overall delay between request and response.
The first 2 are often in competition with the 3rd one.
1) Botching: If you have number of independent writes, collect them and do a big write all at once. Here is a classic
example of botching.
While((c = getchar()) != EOF)
Putchar(c);
If a code was implemented in a way that you fetch or write for each character, it will be a terribly slow code. Standard IO
libarary turns this into
Read(0,buf, 4096)
Wirte(1, … )
So this is a batching at the application level, in order to improve performance and this same idea can be use everywhere
in the system.
2) Speculation: What your application or file system is going to do is its going to guess what your program will do in
future and act on this guess. So batching was speculating that you will read new character and acted upon this speculation.
So basically the idea of speculation is to predict the future and do that work now. When we are speculating and reading,
it is called pre-fetching. For the writing, it is just called dallying.
Note: So this was the reason behind the Gzip bug? It did not store the file on hard disk, it just buffered it.
The reason the speculation works is because of the LOCALITY OF REFFERENCE.
Apps, when they call getchar have locality of reference.
Temporal locality: If you access location at t, you will likely access the same location at t + delta.
Spatial locality: if you access location i * t , you will likely access the location (I + epsilon) * t .
So basically read and writes are not random, and this is the reason why speculation works.
All it does is read the i th block/ writhe the i th block. Block layer also maintains a cache. So instead of writing,
the block layer can have the data ready in cach. So how can we make this block layer faster other than
giving it a bigger cache?
So assume, we are building a file system on top of the disk drive. So we have to worry about accessing various sections
on the disk, and the disk arms are the slowest part of the disk, so seek time dominates the effect of accessing the I
th block on the disk.
So what we are going to have a simple model of disk access, and in this model, we are going to try to make our block layer
faster. The simple model is going to be a big array of blocks.

So if we are trying to read, the I/O head have to move to the position of the i th block. So the cost of reading the
block I is the distance between I/O head and block I. So we are trying to find the average time of the read.
Well if we assume random requests, in worst case it is 1 and in best case it is 0 so the average will be 0.5. Suppose
read head is at the middle, now the average cost is 0.25.
So our average is 0.25 <= average < 0.5 so how do we figure out the average? Then Professor Eggert yelled THAT IS CALCULUS
we need to use integrals, and reminded us about all the horrors of math.
The following integral is the solution, and as we can see, the average time turns out to be 1/3.
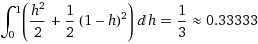
So this is the average time, when assuming random distribution of data, in real life data is clustered so
the average time is less.
Basic idea of queue pending request is that the block layer dollies. It gets request to read the I th block,
and since we have many processes to take care of, it adds the request to the queue pending requests.
So it is a collection of actions that the block layer is asked to do. Block layer is free to choose which
request to take care of next, so it is not necessarily going in order of request arrivals. Block layer does
this in order to move the I/O head as less as possible. So if we want to maximize throughput, or block
layer should use an algorithm called shortest seek-time first. Note that this does not minimize the read
head moved distance. So this is a greedy algorithm, it grabs the lowest hanging fruit first and then
attempt to come up with maximum result but it does not always give you the max.
Note that there is a starvation problem with the shortest seek time algorithm. One solution to this
problem is the algorithm called the elevator algorithm. Elevator algorithm is a compromising algorithm,
it is not first come first serve but not as bad as shortest one.
By the way it, turned out that the actual integral that we discussed above is this
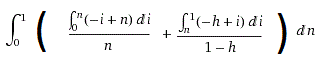
Why does it take the elevator longer to arrive when at the basement or penthouse? It is the same
reason why it took longer for the I/O head to read data from edges of the array. One fix for this problem
is called circular elevator. So for example, the building elevator would go from penthouse to basement
by going up. The idea behind this is that we always seek forward. There is a cost to the circular elevator,
because on a disk drive, if we reach the edge of the disk, we have to move the head to the start again,
but we are ok by paying this cost in order to get extra fairness from the circular elevator algorithm.
Another way is to go back to shortest seek time first and combine it with first come first serve. So we
have to give each request a score = diff between how long it`s waiting - distance from read head.
So with all this tools, now we can have a better performing block layer for our file system. So the rest of
our file system will communicate with the actual disk indirectly through our block layer without
worrying about details. But there is still a problem. Imagine we want to rename a file “file” to “fuzzy” by
calling rename(“foo”, “fuzzy”).
So we are going to take the inode # of the working directory, and our wdi will point to data blocks of the
working directory and this info will be cashed. So we changed the string “foo” to “fuzzy” , changed the
length from 3 to 5, and let’s say that this data block is located at 512, so we have to call write to 512.
The problem is that it won’t be written right away. Now suppose that this directory block is full so we
can’t add 2 letters, so directory grows and we get a new free block, let’s say we find that block 1970 is
free. We know that block 1970 is free from bitmap, and since we just got that new block, we have to
change the bitmap value as well plus since we just grown directory, now it takes two blocks instead of
one, so we have to modify inode block as well. So in order to do the rename, we have to modify 4
blocks. So in which order to do these writes? Order matters because if system crashes, we don’t want to
lose data, so we need proper order of writes.
1) 1) Free block 1973
2) 1) Bitmap
3) 1) Inode
4) 1) Remove
If system crashes at free block, we will just get a free block, so no harm.
If system crashes at bitmap, we will have data structure on disk that is inconsistent; it is just a small
memory leak.
If system crashes at inode, we will end up with 2 names for the same file. There will be a huge problem
here if the link count for the file still shows 1. We can fix this by temporarily adding 1 to inode link count
before changing the inode, and then changing it back to 1 after inode write is done.
1) Every block is used for exactly 1 purpose. ( example: boot block, super block, bitmap and so on)
2) All referenced blocks are appropriately initialized, so you don’t have unutilized garbage in inode.
Free blocks don’t have to be initialized.
3) All referenced data blocks are marked as used in the bitmap.
4) All unreferenced data blocks are marked free in the bitmap.
Penalties for violating these invariants.
Violate #1 (example use same file for 2 different purposes): Disaster- data loss.
Violate #2 (example Inode entry made up at random) : Disaster- data loss.
Violate #3 will overwrite data and loose data : Disaster- data loss.
Violate #4 is a memory leak, so no disaster. Plus we can fix these leaks by going through all inodes.
So one possible program to fix 4 will look as follows
fd_opendir(“/usr”)
equip value of( “find”)
stat(“foo”, &st)
st.std_ino
This will give us the inode integer, but we can’t do anything with it, so this is useless. So how can we fix
problem #4?
We need a program designed for your file system to find dangling blocks. FSCK can do this. It can also
find files that are not linked anywhere. FSCK puts these non-linked files in a directory called lost and
found.
So you have your file system code that is very carefully written to preserve the 4 invariants, the code
does its read/writes in a particular order that we talked about. The problem is that when we move this
code to the block layer, our carefully write ordering that we wrote stops working because block layer is
using its own algorithm like elevator or shortest seek time algorithm to gain performance.
So for example, this same issue is true for Seasnet servers, and their solution is that they better not
crash. SO they use external batteries to make sure that there is no power outage to the servers. But on
personal computers, not everyone have batteries to protect the user from this problem. The
workaround on this problem is as follows. In ext2 … ext4 file systems in linux, when you mount file
systems, we have many options to issue, and one of them is the option called ordered mount. This
option tells the file system not to use the pending request queue and ensures that all operations to disk
are done in the order specified by the user. So this lets our code survive crashes.
Now suppose we are running our Gzip on seasnet which does not support ordered mount, and system
crashes before exit(0) and the battery backup does not work.
Let’s say that block U is the write to ofd and block W is the unlink of the “foo”. So we wanted to make
sure that write to U is done before write to W, but Seasnet can change the orders and if W is written
before U and system crashes before writing to U, we lost the data.
So in order to fix this problem, we have to add if(fsync(ofd) !=0) error(); after our write(ofd), to tell the
block layer to carry out the write to block U before writing to block W, and this will make sure the order
of writes is correct and even if the system crashes, we won’t lose data.