Winter 2016, Lecture 14
File System Robustness
Written by Aditya Kotte and Ritam Banerjee
What's the Worst That Could Happen?
Gzip very good at compressing files, but it has a bug…
ifd = open("foo",O_RDONLY);
ofd = open("foo.gz",O_WRONLY|O_CREATE..);
write(ofd, buf, ⬭);
read(ifd, buf, bufsize);
if(close(fd)!=0) error();
if(close(ofd)!=0)error();
<---crash?
if(unlink(“foo”)!=0)error();
exit(0);
System crash at that point could cause you to lose all your data. How?
We are being so careful about closing all the files.
So what’s the bug?
Let’s go on to file system layout....
BSD File System Layout
(Figure 1 below)

Free block bitmap keeps track of where available blocks are.
This is how we grow files. Must be fast.
1 bit/block of data. That’s a 8*8192 = 65536:1 Very good compression ratio!
This is plausibly cacheable in RAM.
This is a classic "Performance" issue.
Performance Issues with File Systems
Overhead of reading from disk:
seek time-time for read head to move to sector (10ms)
+ rotational latency - physical constraint of disk drive (8ms)
+ transfer from disk
+ copy to RAM from cache (0.1ms)
≅ 18 ms
18 ms is a long time for a computer… enough time to run 8 million instructions!
File systems try hard to avoid using secondary storage for these reasons.
I/O Metrics
Utilization: what fraction of the time are you reading or writing data?
- Low utilization = not using I/0 devices well/not as much as perhaps should be
- can be percentage (%) or [0,1]
Throughput: rate of request completion.
Latency: overall delay between request and response.
These often offset each other. An improvement in one comes at a cost to others.
Files systems that have good latency often have poor throughput & vice versa.
How to improve File System performance
- BATCHING: Combine multiple read or write requests into big read or write requests.
- coalesce small requests into big ones
- How cat works (figure 2 below)

- SPECULATION: Guess future behavior of an application and do that work now.
- Works hand in hand with batching, speculates that you will want to read or write the next thousand bytes or so.
- Example when reading: PREFETCHING
- Example when reading: DALLYING
- Dallying: Save time by slowing down. The idea is that the command might change, the needs might change in the middle of executing a command, or other commands may arrive that can be optimized by waiting to write. I.E. On write command, program may later cancel the write. Dallies to do other useful work, and "lies" about success of write.
LOCALITY OF REFERENCE:
- Temporal locality: accessing the same data in a similar time frame
access location i at time t
correlate access location i at time t
- Spatial locality: accessing some data means you will probably want to access nearby data soon.
Locality is what makes speculation work because of the predictability it offers. If there was no locality, speculation would not improve performance since its difficult to predict. Speculating when you can’t predict what happens is very unlikely to provide any optimization.
Block Layer of File Systems
(Figure 3 below)

Read block i/write block j
maintains a cache: greatly improves performance
Lets speed this up:
Simple Model of hard disk access: Disk is represented as continuous blocks.
Avg cost of read:
assume disk head at one end: 1/2
assume disk head in the middle: 1/4
Integrate to get actual delay: (equation 1 below)
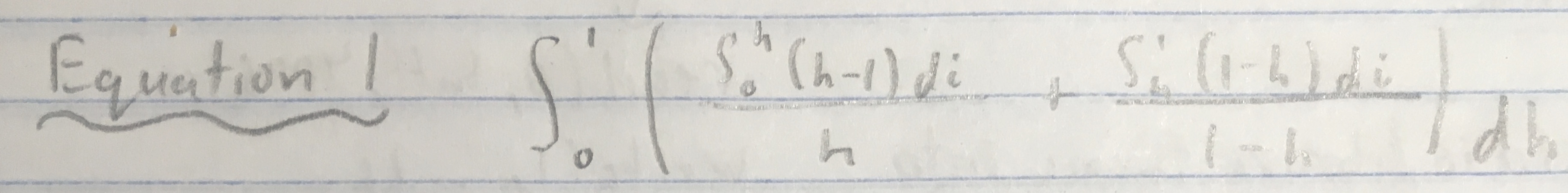
To approximately maximize throughput: use SSTF (Shortest Seek Time First). Do the request closest to where the read head is currently.
Suffers from the problem of starvation. Also suffered when needing to seek back and forth from the read head, not optimal since it is shorter in terms of distance to the read head, but overall distance is much greater.
SSTF + FCFS←wait time
↙wait time
random factor→fw - |i-h|
↖head
Elevator Algorithm: This has problems as well, even though its a compromise. At either end, top or bottom, you will wait longer than at the middle.
Circular Elevator: After you reach one end of the disk, you always go back to the other end. This also relies on the trick that spinning all the way across the disk is faster per unit due to velocity.
rename("Foo","Fuzzy") --> Follow inode to directory entry. In directory entry, change name and name length.
We will write block 512 or whatever block it points to later.
What if directory entry is full?
We will need to make free block (1973), add new directory entry (block 4), write to directory inode with new directory entry (block 312).
Renaming now makes us write to 4 blocks, instead of 1.
Whats the most secure order to write these blocks?
(Figure 4 below)
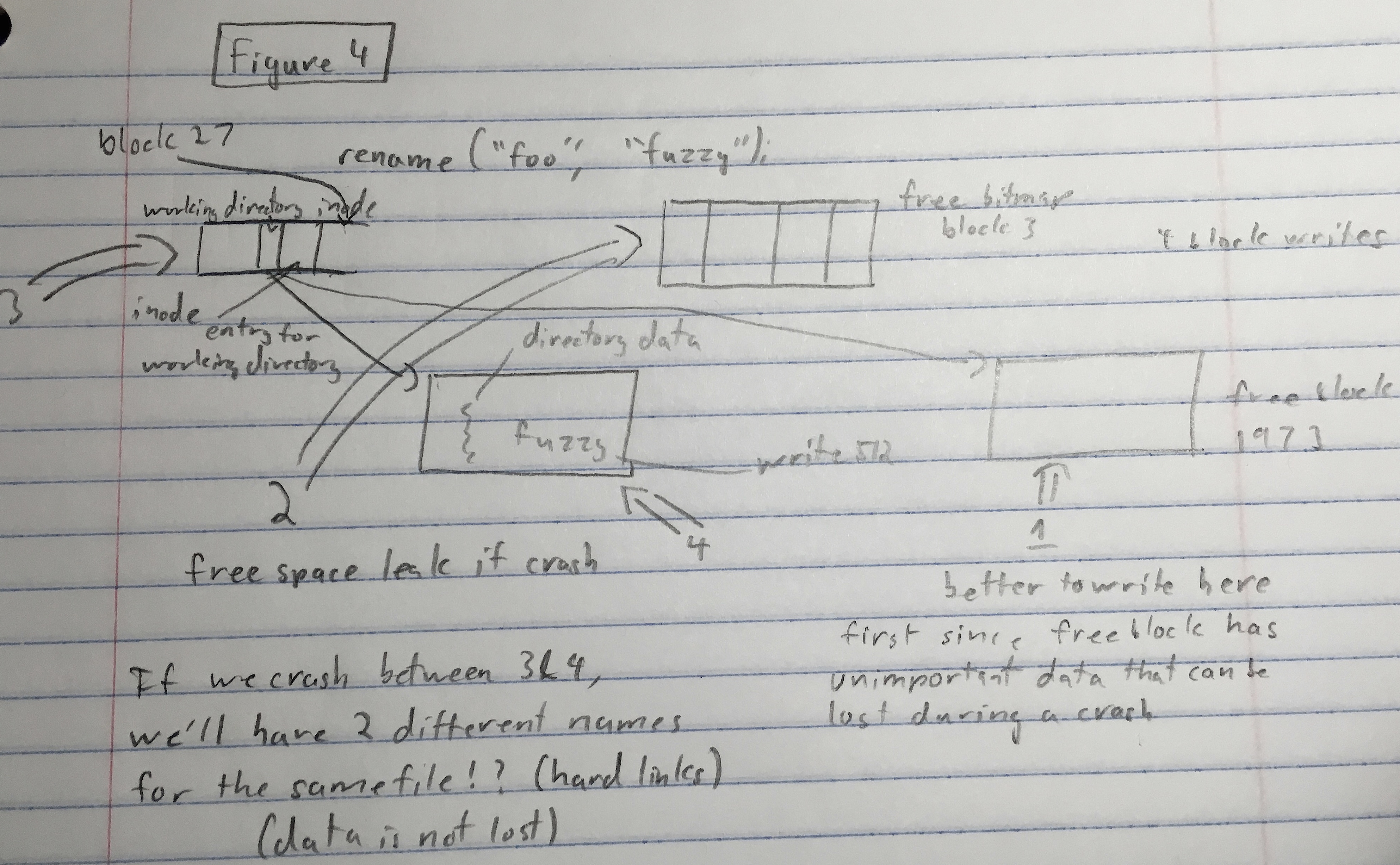
Order affects stability in case of crash.
File System Invariants
- Statements that will always be true even if you crash in the middle of an operation
| Penalty for violation |
Have to keep track of important parts of file system on disk |
| disaster |
1. Every block will be used for exactly one purpose |
| disaster |
2. All referenced blocks are appropriately initialized |
| disaster |
3. All referenced data blocks are marked as __used__ in the bitmap |
| storage leak |
4. All unreferenced data blocks are marked __free__ in bitmap |
What is the penalty for violating these invariants?
Disaster! WILL lead to loss of data and a crashing file system
fsck: looks for memory leaks, if it finds a file that’s not referenced/linked anywhere (free blocks not marked free), puts it in /lostandfound/ directory.
Despite careful ordering of block access, at the block layer, algorithms like the elevator method, mess up careful ordering.
--ordered option makes sure commands occur in our order. This lets code survive crashes. Now going back to the crash in Gzip…
Gzip source code doesn't use ordered option.
ifd = open("foo",O_RDONLY);
ofd = open("foo.gz",O_WRONLY|O_CREATE..);
write(ofd, buf, ⬭);
<--- if(ifd<0) error(); //check for errors
read(ifd, buf, bufsize);
<--- if(ofd<0) error(); //check for errors
<--- if(fsync(ofd)!=0) error(); //fsync makes sure that the ofd is written then and there regardless of dallying or speculations
if(close(fd)!=0) error();
if(close(ofd)!=0)error();
<---crash?
if(unlink(“foo”)!=0)error(); //access block u
exit(0);//↘block U (written)
crash->write(W) //u might happen first, and w might never happen. We have removed old file but not written compressed file. We could use a lot of data.