Lecture 14: File System Robustness and Virtual Memory
Problems with Gzip
GZIP Bug
This bug report describes a recently discovered problem regarding the ancient gzip program.
Under certain circumstances it is possible for the program to delete all of the user's data without warning. gzip
typically works as follows:
fd = open("foo"...); //Open file to compress
open("foo.gz"|O_CREAT...); //Open the .gz file which you wish to write data to
write(...); //Perform some number of writes to the file
close(fd); //Close file descriptor
unlink("foo"); //Delete the original file
However, if the system crashes immediately after the unlink, then the users data will disappear! What is actually happening is that the file system is not writing out data when write is called. Instead it essentially holds onto the writes and buffers them to be written late for the sake of performance.
Since the system crashes right after the unlink, there is no time to actually write foo.gz to disk. As a result, the original "foo" file will have been unlinked and the compressed file will not exist. Clearly this is a disaster.
The Fix
The fix for this bug came from the glorious Eggert himself and should be present on the next release of gzip 1.7
dfd = open(".", O_SEARCH);
fd = openat(dfd,"foo.gz", O_CREAT ...);
write(...);
fsync(fd);
fdatasync(dfd);
close fd;
unlinkat(dfd, "foo")
The extra functions fsync and fdatasync fix this problem by ensuring the data does get copied. The function fsync makes sure that the data from the write has been copied to disk before proceeding, while fdatasync ensures that the file has been created in the directory. Thus, if the system crashes right after unlink the data has already been forced to disk and we will have no loss.
However, this solution isn't without fault. As can be seen from the email exchange record on the bug report page, there is much controversy regarding the implementation of this feature.
- Speed - forcing the program to write to disk when it would rather not makes the entire program much much slower. Eggert tested this by compressing 1000 empty files, which ended up being 700x slower than normal.
- Practicality - if this feature becomes default in gzip, everyone will become upset since their program is now much slower than before. If this feature is implemented as an option --synchronous for the optional security, then the default will still be bugged.
- Implication - this bug, though very subtle, is present in nearly every single program that moves data from one place to another. Thus, if we fix gzip this way, we will have to fix everything else in the world as well.
File Systems
So all of this seems like a ridiculous way to deal with a seemingly fundamental problem of moving data. If our computer just had enough electrical "inertia" after a power loss (or some battery backup) then the system would be able to complete the write before dying completely. Unfortunately, this is not the case. Instead of having to manage this mess in the application, we want the file system to deal with our problems for us.
How can we design a file system to take care of this? We want absolute reliability as a primary goal, followed then by performance.
With the tools given to us by the ext_4 (man mount_ext4), there are 2 general possibilities:
- COMMIT RECORD:
- We assume that it is possible to write out one block/sector of data atomically, even if we lose power.
- When writing, we group writes into one large write with sectors S1 - Sn. When the write for all those sectors are completed, we write a commit record to sector Sn+1.
- Essentially, the first S1-Sn writes do not count until we confirm it with the commit record. If the system crashes in the middle of the writes and we are not able to make the commit record, then even though we have written some of the data to disk, we pretend like we have not done any of them.
- This allows us to create a larger atomic write from multiple smaller atomic writes
- JOURNALING:
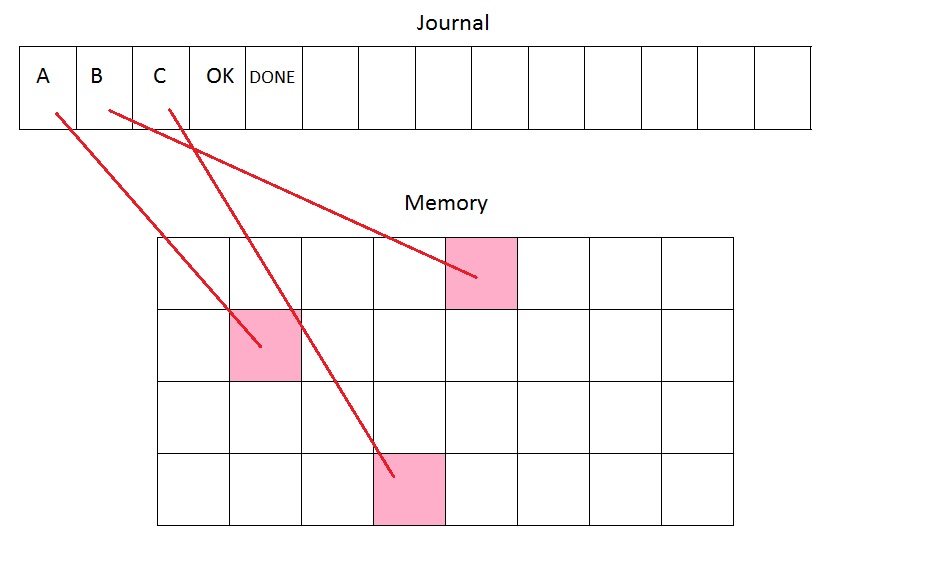
- Divide the disk space into two sections, one large, main piece for storing data, and another smaller piece for the log.
- The log is unerasable and functions similarly to a commit record.
- When writing to disk, the intended changes are first marked in the log, specifying where and what is to be added to the disk.
- After intended changes are recorded, an OK mark is placed in the log and the system begins actually writing to disk.
- Once write is completed, the log is marked with DONE. If at any point in this process the system crashes, then upon reboot, it will only have to look at the log to see which step it was on and continue from there
- The log is implemented such that if it hits the end, then the writing will simply circle around to the beginning. If the log ever fills up completely, we wait for some reads to be done so more space becomes available.
Both of these methods have undesirables, in that if they fail at the tail end of the write, they will have to start again from the beginning upon reboot, essentially performing two writes of the same thing.
Another (somewhat extreme) variation of journaling is to have disk composed almost entirely of log space with practically nothing allocated for actual storage. Basically, all the data is stored in the log. In this case, the file system just keeps on writing things to the log and generally never moves it to disk. As a result, this design will be efficient in writing, since everything is sequential, but inefficient in terms of reading. Therefore, only systems that generally perform many small writes will use this design.
Going back to the original journaling design, we now want a system that is faster upon reboot. Right now, after rebooting from a crash, we must scan the log backwards to find the least recent operation that failed, and then scan forwards to redo the operation. This is called a write-ahead log
Here is the general algorithm for a write ahead log:
Write Ahead Log
- Steps:
- BEGIN
- Log planned writes
- Commit
- Install new values
- END
The alternative to this which we look at is the write behind log. In this case, instead of logging our intended write values, we log the previous value that was already stored in disk and then write the new information into disk directly.
Write Behind Log
- Steps:
- BEGIN
- Log old cell values
- Install new values
- Commit
- END
The advantage of having a write behind system is that upon reboot, it is not necessary to perform two scans. Instead, we simply are able to scan left until we find where the log ends.
This write behind method, however, is not always implemented as it is somewhat redundant to always be copying old data. Generally, file systems tend to use write ahead logs while database systems tend to use write behind logs.
As a sidenote, it is also possible to separate the log and main memory into different disks. This will speed things up since log writes will all be sequential and minimize seek times.
Other Ways to Fail
We can further divide failures into two general ideas:
- Cascading Abort:
- Here what happens is that each process that fails will also case the process that called it to fail as well.
- If we have two processes, the caller P1 and the callee P2, then if P2 fails, P1 will rollback to the point where it called P1 and also fail
- Compensating Action:
- Unlike in cascading abort, compensating action implies that the caller of the process which fails will get to determine how it would like to manage the error.
- If we have two processes, the caller P1 and the callee P2, then if P2 fails, P1 must perform some action to account for the error.
Cascading abort is typically easier to implement while compensating action is more flexible.
Saving Important Data
Suppose we have some data with varying importance. That is, there is data on our disk which must be maintained at all costs, and data on disk which we're somewhat ok with losing. What would be the best way to set thus up?
One method is to partition the disk into separate areas, one for important data and one for less important data. In addition, each partition of the disk can implement a different file system, depending on its security requirements.
What makes this sort of diverse file system disk possible is the existence of a data structure in Linux called the mount table. What this table essentially does is it maps file system inode number pairs to the correct file system. The table exists as an array of these filesystem :: inode# pairs that allow the system to get the correct file system based on the inode number.
Virtual Memory
Moving on from the previous topic of file system stability, we now shift our focus to virtual memory.
Suppose we have some programs that don't work well due to some memory issue (i.e. bad pointers or bad subscripts). This is a serious security issue as well since it is a popular way to break into systems. What are the best ways to fix this?
- Hire perfect programmers
- Use Java/JavaScript/Python
- Ask our hardware buddies for help
Option 1 is expensive, option 2 is slow, which leaves us with option 3.
Simple Idea
For the sake of simplicity, let us only care about processes which try to mess with memory outside of its designated bounds, ignoring any processes which decide to muck about horribly in their own memory space. To detect any action which attempts to do anything outside of the "safe" space, we ask the hardware buddies for two new registers which correspond to the base and bound of the process.
These two registers specify the starting and ending addresses of the process, so if any action attempts to access memory outside of these registers, and error occurs.
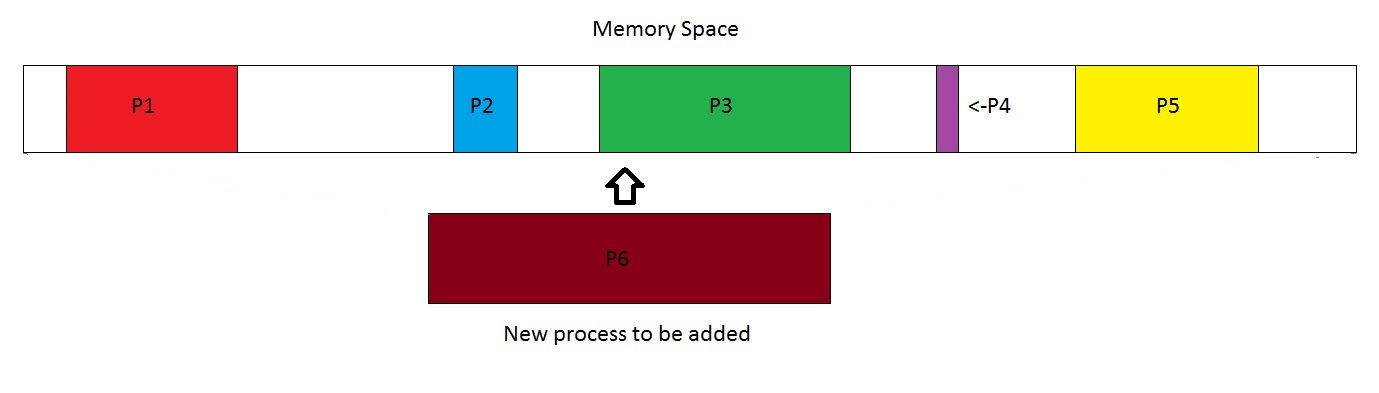
What are some possible problems with this approach? One might be inclined to say the ridiculous number of checks that must be done for this to work (since we must check every assembly instruction which involves a memory location). However, that can be done in parallel. The main issue with this setup is fragmentation.
With fragmentation, processes that should have enough RAM to run are not able to since the free memory is spread across all multiple sections (and the base/bound register method requires contiguous memory.
In addition, this method also makes it difficult to share memory between processes and makes it difficult to increase process space if needed. Aside from use in batch environments, this design is typically a bad one in other environments.
Segmented Memory
Segmented memory is similar to our previous idea in that it still looks for address accesses that are outside of acceptable bounds. However, instead of characterizing this acceptable bound as a single large chunk of memory, we segment it into multiple areas.
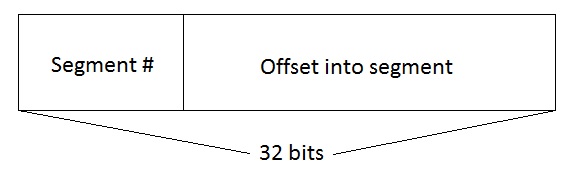
For each process, there is an entry in the segmentation table which corresponds to the base and bound. Each one of these is pointed to by a 32 bit quantity: the first n bits of which represent the segment table number and the remaining 32-n bits specifying the offset in the segment
Disadvantages of this segmented memory:
- Total size and number of segments limited
- There will still be external fragmentations and large segments still are problematic and cumbersome to deal with.
- Memory still has to be somewhat contiguous, just in more segments
Pages and Virtual Memory
Suppose now that instead of having a bound on our segments, we assume that all segments are the same size. This gives us what are essentially pages. In addition, each memory address is divided up into two sections, the first roughly 22 bits represent the page table address, and the last 10 bits represent the offset in the page. This implies that all pages are 2^10 bytes in size (note that these numbers can change depending on the system and implementation). These entries are stored in a page table. Each time a lookup is performed, the page table (which is stored in RAM) will be accessed and the page table entry will provide enough information to locate the address in physical memory.

As explained in CS 33, this virtual address is fed to the appropriate hardware (MMU) which spits back out the actual physical address mapping. It is also possible for there to be multiple levels of page tables, allowing for a reasonable number of such page tables to cover the entire memory space.
Benefits of paging:
- Allows user to run programs that require more RAM than is actually available (this is more of a marketing pitch, as we generally do not want to run most programs like this since it is slow)
- Processes can "safely" share memory
- Suppose we have some system call sendmsg(destproc, message) where the message is a pointer to some buffer. Assuming that the buffer is aligned in memory, to copy the data to the other process, all we have to do is copy the pointer from the page table.
The way the system is able to implement the first of the above listed advantages is by utilizing both RAM and part of disk as memory. Essentially, the computer pretends to have more RAM than it actually does, and if the process every actually tries to use that imaginary memory, then the system will move some data from RAM onto disk, and copy the wanted data from disk onto the newly freed RAM space. This memory that the system pretends to have is called the swap space. Thus, the total virtual memory = physical memory + swap space.
The general procedure in using swap space occurs where the system tries to access a page that is not currently in RAM. This is known as a page fault. If the page table detects that the page is not present in RAM, it will take the time to swap some page in memory with the wanted page on disk.
This is extremely slow and makes everyone upset. As a result, much optimization is done to make this as infrequent as possible.
Another question: how much swap space should we have? If we have a lot, then we can run larger processes, but they will be very slow. If we only have a little swap space, then things will be faster but then you'll have less memory to work with. This is an open question and answers can vary somewhat.