Lecture 15: Virtual memory and processes, distributed systems
Transcribed by Benjamin Statz and Junnan Wang
Page Faults
Virtual memory structure

Page faults occur when a process cannot access a page, whether that is due to lack of access privileges or the page simply not being loaded into RAM. Upon a page fault occurring, control is transferred to the kernel. which has 3 options:
- Terminate process
- Send SIGSEGV
- Pull page into memory and retry the instruction (slowest, requires I/O)
What can an app programmer do in case 2? For example, upon a SIGSEGV, Emacs assumes a stack overflow has occurred and discards the stack. This is not a reliable way to detect stack overflow. Emacs uses guard pages which are set as unusable using Nmap, and trigger the SIGSEGV if they are attempted to be accessed - but an array larger than the size of the guard page can cause all indices of the guard page to be skipped over. The solution is simply for Emacs not to create large local arrays.
Page fault mechanics
What is stored in kernel memory?
- Page tables
- Swap map
- Given a process and a virtual address in the process, the swap map gives you the location of the corresponding disk address:
- da = swapmap(p, vpn)
- Each process table entry contains data for the disk location of the process in swap space
- The disk address is calculated as (4096 * vpn) + an offset equal to the aforementioned disk location
On a page fault (assuming a valid virtual address):
- There is insufficient physical memory - page is on disk
- Must read page in from swap map
- Problem: must read into a location in physical memory
- As the system keeps running, memory fills up - must pick a location that already contains data
- Solution: before reading page, choose victim page (p', vpn')
- Write from physical page to swapmap(p', vpn')
- Update old page table entry to be NULL (no longer in RAM, meaning it should page fault if accessed)
- Update page table entry for new page
- How long does all of this take? On the order of milliseconds, which is fairly long
-
- Other threads can be scheduled in the meantime
- Can break into pieces and schedule in parallel
Virtual Memory Policy
How is the victim page selected? There are several possible page replacement policies:
- First in, first out (FIFO), aka victim++
- Fair policy - no page gets to monopolize memory
- Problem: evicts commonly used pages just as often as uncommonly used pages
- Random replacement
- victim = random(physsize), to produce a value between 0 and the number of physical pages
- Same problem: evicts commonly and uncommonly used pages equally often
- Oracle policy
- Look ahead in future program execution and see which pages are needed in the future
- Victim = page least needed in the near future
- The past is not considered in this policy
- Cannot be used by practical operating systems, as they cannot predict future behavior
- madvise
- System call which gives information to the kernel about future memory usage
- Syntax: int madvise(void *addr, size_t length, int advice)
- addr: start of virtual address
- length: number of bytes in memory to consider
- advice: one of several possible constants which describe the order in which memory will be accessed.
- Examples include MADV_SEQUENTIAL, MADV_RANDOM, and MADV_NONE; a full list can be found here
- Has existed for a long time, but many apps don't use it
- Often doesn't help - following its advice can potentially make program execution worse
- Program can lie and claim to be more important / more highly used than it actually is, giving its pages unfair preference
- Least recently used (LRU)
- Choose the page that has not been used for the longest time to be the victim
- Most commonly used policy
Examples:
The same reference string is chosen to test all page replacement policies. For this section, we will assume there are 5 virtual pages (labeled 0-4) and 3 physical pages (labeled A-C), and we will use the following reference string:
0 1 2 3 0 1 4 0 1 2 3 4
In actuality, the reference string is determined by running various programs and keeping a log of pages used. The objective is to minimize overhead by reducing the number of page faults, which are represented by deltas in each table.
FIFO
Cost = 9 page faults 
Oracle method
Cost = 7 page faults 
Least recently used
Cost = 10 page faults (this decrease in performance is somewhat of an irregularity) 
FIFO, with 4 physical pages
Cost = 10 page faults. In this scenario, adding memory actually made performance worse. This is known as Bélády's anomaly. 
Implementing LRU policy:
The optimal setup would be to have a dedicated column in the page table to store a timestamp at last access for each page. However, this is not supported by x86, so a separate clock table array must be used. To enable kernel access to this table, set each page in the page table to be inaccessible. When an access attempt is made, a page fault will result. When this happens, set the page to its proper read-write status, so the access can be made, and at the same time set the entry in the clock table.
Virtual Memory Optimizations
Demand paging
- Rather than reading an entire program into physical memory, read only page 0, and copy additional disk pages into physical memory only if a page fault occurs due to an attempt to access them
- Pros: only loads the required pages - avoids unncessary work when only small sections of a program are needed
- Example: gcc --version will only load the necessary pages to determine the version number, a very low amount compared to the full program
- Cons: cannot batch reads, causing extra overhead (more page faults, extra disk arm movement to access data on disk in smaller amounts)
Dirty bit (and related concepts)
When a page fault occurs, the old page is written back to disk, and the replacement page is read into memory. The writing step can be redundant if the contents of RAM have not been modified and already match the disk contents. How can this be made more efficient?
- Read before writing
- Before writing to disk, directly compare the contents of the disk and RAM to determine whether the write needs to occur
- Inefficient - involves even more I/O than before (extra read)
- Use a checksum
- Collisions can occur - modified RAM data may have the same checksum and will not be written to disk, losing data
- Solution: use a cryptographic checksum
- Regardless of accuracy, checksums are expensive - checksum table is proportional to size of virtual memory
- Dirty bit
- Most common optimization for this scenario
- Store an extra bit in each page table entry: 0 if the page has not been modified since it has been read from swap space, 1 if it has been modified
- Requires hardware cooperation, but it is not a performance problem, since the dirty bit changes very infrequently
- Can be implemented without a designated dirty bit in the page table, even though it requires kernel access. To do so, use a similar method to the LRU implementation:
- Mark each page in the page table as read-only
- When a page access is attempted, a page fault is triggered, allowing the kernel to set the dirty bit in a separate table
fork() optimizations and vfork()
In more primitive implementations of fork(), the entire process is cloned, including the page table and the data - no memory is shared. This is very expensive/inefficient - when a large program implements a smaller one, the majority of the data is discarded when the child calls close() and exec().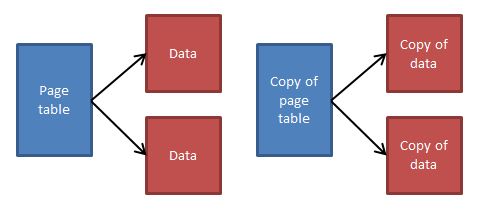
The solution is to copy only the page table and have the child's copy point to the same data pages as the parent's. Then, both page tables are set to read-only, which will cause a page fault if any write attempts are made. On a page fault, the page is first set to read-write as it should. Then, a copy of only the modified page is made, and the child page table is updated. This is how modern implementations of fork() function.
vfork is identical to fork, except for 2 differences:
- Parent and child share memory - vfork clones neither the page table nor the physical memory data
- Parent is frozen until child either execs or exits - this avoids race conditions where the parent and child are accessing the same memory
It is no longer POSIX supported, since fork() has become more efficient since it only copies on write, and modern CPUs are fast enough to clone the page table with a negligible effect on performance.
Intro: Distributed Systems
Distributed systems involve running an OS whose components are not all on the same computer. One way of managing this is to use remote procedure calls (RPCs).
Remote procedure calls
RPCs differ from ordinary function calls and system calls in several ways:
- No shared memory
- Only way for the callee to access data is to copy it
- Example: strcmp(a, b) will not work if one is located on the caller machine and the other on the callee
- Pros: hard modularity is enforced
- Cons: difficult to access data
- No call by reference
- For instance, the system call ssize_t read(int fd, void *buf, size_t count) will not work as an RPC since buf is a memory location
- Caller and callee can have different CPUs or disagree on instruction sets / data formats (e.g. little vs. big endian, different CPU architecture)
RPCs can be simulated as if they were ordinary function calls using the principle of marshalling, in which complex structures are transmitted bit by bit over the network. In order for the original program to remain unmodified, an additional layer of functionality is inserted between the program and the network, which is responsible for marshalling. For instance, a system call of read() sent from the program would be modified to remove the original reference to a memory address, then converted to a series of bits encoding the call and its arguments. Likewise, an additional layer is needed to decipher the RPC and convert it back to an ordinary system call before it is passed to the server.
Problems with RPCs:
- Messages can be lost or corrupted
- Network or server might be down, or slow
Beginning next lecture: how to fix these problems