Scribe notes by Sebastian Waz, UID: 704184266
A virtual memory system typically uses a page table consisting of pages 4KiB in size. 32-bit addressing is used to index this entire space: a 20-bit segment is used to indicate page number, and a 12-bit segment is used to indicate page offset. One issue with this formulation is that the page table becomes very large. How large does it become? Our page table consists 220 descriptors (1 for each page), each of which is 32-bit (or 4 KiB in size). This gives us a page table of size 220 x 4 KiB, which is equivalent to 4MiB. This much overhead is unacceptable! How do we compensate? By using a dynamically extensible 2-level page table.
How does a 2-level page table function? We divide the 20-bit page number field of the virtual address in two, splitting its information between a master page number (level 1) and a secondary page number (level 2). The master page number, a 10-bit value, indexes 1024 (210) master page table entries which map the master page number to one of 1024 secondary page tables. The secondary page number, another 10-bit value, indexes 1024 secondary page table entries which map the secondary page number to a page frame number in a physical address. As before, the offset in the virtual address is used as the offset in the physical address, combining with the page frame number to give the complete physical address. Confused? Here's a diagram of how it all works:
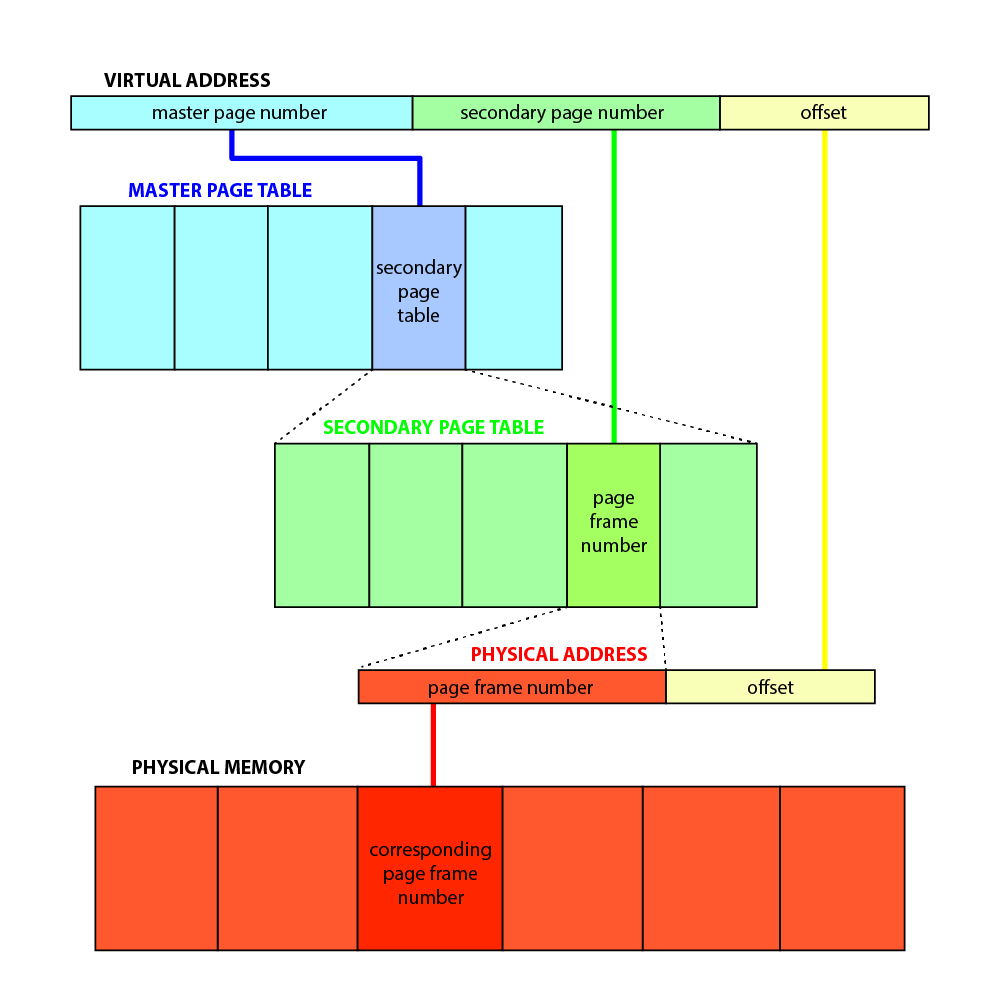
This page table organization reduces memory usage by eliminating the need to store the page table as an entire contiguous array. We do not need to allocate space for blocks that contain no descriptors, and can bring blocks in as necessary.
It is possible that an entry in the secondary page table indicates an invalid memory location. If someone were to attempt to access the invalid memory (e.g. by executing the instruction movq $0 (%rsp)), the process traps and falls into the OS. Typically, this results in a page fault.
When the process traps, the kernel is passed a number of parameters. One of these parameters is the faulting address. After checking the faulting address, the kernel can decide to respond in one of several possible ways. It can:
Of these options, attempting to pull the page in and retry the function is the slowest.
How do we catch runaway programs that may attempt to access invalid memory locations? We use guard pages. Guard pages intentionally introduce "holes" in the disk which are monitored for access. If a process attempts to access these holes, you will be able to throw an error and trap the process before conducting one of the responses listed above.
Now that we've spent some time talking about hardware, let's talk about software!
What's in kernel memory besides the page tables? Swap space! But what is swap space?
When we call swapmap (p, pn), the function returns a disk address (da). It takes the page number passed into it, multiplies it by 4096, and adds it to the location in swap space. The disk location in swap space is then stored in the process table entry. On a page fault of a valid address, we read the page from swapmap (p,pn) (which is on disk) into a victim page. This means that before reading from swapmap(p, pn) we must actually choose a victim page (see ahead).
Supposing we have already chosen a victim page, we need to write from the physical page to swapmap (p', pn'), as to save the old page before we read from the new one. We will also need to update the old page table entry to NULL, as well as update the page table entry for the new page. This process takes a while (on the order of milliseconds), so while we're waiting, we can schedule other threads to run (since we can presume other threads don’t really care about this page). After this process, we'll eventually be able to run our movq function which caused this page fault to begin with.
So, how do we choose the victim page? There's a very high chance that you will make the user unhappy. This is because any program which may be running on the victim page will be very slow. We want to minimize the user's unhappiness as much as possible. This is a matter of policy.
Victim++ policy: The victim is the index of the physical page. Each time you need to evict someone, take the next page in physical memory and evict that page. No page gets to monopolize the memory.
Lottery: A random value is chosen between 0 and the maximum index of physical space. The victim is indexed by this random value.
A problem with both of these policies is that, if there is a very active area of memory, you may evict a commonly used page. This will certainly anger the user. For the sake of performance, you want to keep commonly used pages in main memory. This implies that, if you want the best possible victim selection policy, what happens in the past doesn't matter. What really matters is what happens in the future. We need to look ahead!
Oracle policy: Named after the Oracle of Delphi, the oracle policy is purely hypothetical. It suggests an ideal policy in which the OS can always know exactly which pages will be used most frequently in the near future. Unfortunately, operating systems typically cannot lookahead in most cases. If they could, they would be able to solve the halting problem! Even so, oracle policy gives us a good benchmark for the performance our policy should strive for.
Madvise: The function call for madvise is madvise (start, size, MADV_SEQUENTIAL). The MADV_SEQUENTIAL argument tells the kernel that it is going to access addresses in virtual memory in sequential order. MADV_RANDOM tells kernel that it will access addresses in virtual memory in a random order. MADV_NONE tells the kernel that it's not going to use any of the pages at all: this means that it is safe for the kernel to go ahead and replace any one of the pages. Madvise may be useful in thought, but it isn't often used in practice. Given the excessive overhead introudced, it often makes your performance worse! Moreover, any process using madvise can lie to the kernel (i.e. indicate that it will be using pages that it actually will not) to try and get better performance.
Lease recently used (LRU): One common implementation is to try to use oracle policy by extrapolating from recent history. This means that our victim page should be the one that is least recently used. Essentially, our policy is to evict the page that we haven't looked at for the longest period of time.
Let's look at an example using a sample reference string. This string presumes that we have 5 virtual pages (0 through 4) and 3 physical pages (A through C):
0 1 2 3 0 1 4
Suppose we use the first-in-first-out policy (FIFO): (D indicates that a page was selected as a victim and replaced)

FIFO cost us 7 page faults! But how would the other policies stack up?
Oracle policy: 5 page faults.
LRU: 7 page faults (we had particularly bad luck with this example).
In practice: Typically, your manager will not want you to fiddle with the code to this extent. Instead, they will tell you to just throw hardware at it! For example, we could add a new physical page (beware: if you use a bad replacement algorithm, your performance can actually get worse as you add pages! This is called Belady's anomaly).
Even though we got a bad example here, LRU is usually a good bet. So how do we build it? Our page table needs to include a clock value for the last page access. This clock value is updated at each access; however, a true LRU policy is likely to use hardware support that you don’t have. How can we approximate this? You can replace the clock with a single bit that indicates whether or not a page has been accessed since the last time it was checked (and this bit was thus cleared). Alternatively, you could replace it with a multi-bit flag that indicates the order of access of pages since the last check.
How do we implement demand paging?
The intention of demand paging is to avoid paging into memory until you actually need it.
Strength of demand paging: we avoid unnecessary work in small uses.
Weakness of demand paging: we cannot batch our reads, and will therefore have extra overhead each time.
If you look at the mechanism for a page fault, notice how it writes out the old page. This can be redundant if the contents of the page in RAM match what is already in disk. We can optimize this away! What are our options?
How the dirty bit works:
If it's 0, then this page has not changed since we read it in from swap space. If it's zero, the page is clean. We don’t need to write out old pages if they are clean! Implementing the dirty bit is not all that difficult, because it doesn't flip from 0 to 1 very frequently. If there is no dirty bit in the hardware, you can implement it by indicating clean pages as read-only. When you try to write, it will throw a segmentation fault and markthe page as read-write, marking the dirty bit.
Cloning a process is expensive! You start off with some page tables (which could be multi-level page tables) and tell the hardware that neither the parent nor the child can manipulate the data on their processes. This means that the process will page fault when it tries to write (because they have all been marked read-only). The data will thus be copied over only when the process tries to write to the data. In a way, this is demand forking (analogous to demand paging). This is a very common optimization. But there is a performance problem: you still have to copy over the page tables. The cost of these page tables can be very high.
vfork() is equivalent to fork, except: