Mar 2nd, 2016
Note Taker: Yiran Wang and Zhengxu Xia
Recall the virtual address structure we mentioned last time:
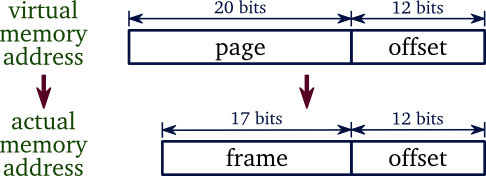
A potential problem for this form is that we may need a very large memory space to save page table. Consider if a page table has size of 4MB, while we are running multiprocess and each process will has its own page table, a huge amount of memory will be consumed.To solve this problem, we come up with a new form of virtual address in a hierarchical way:
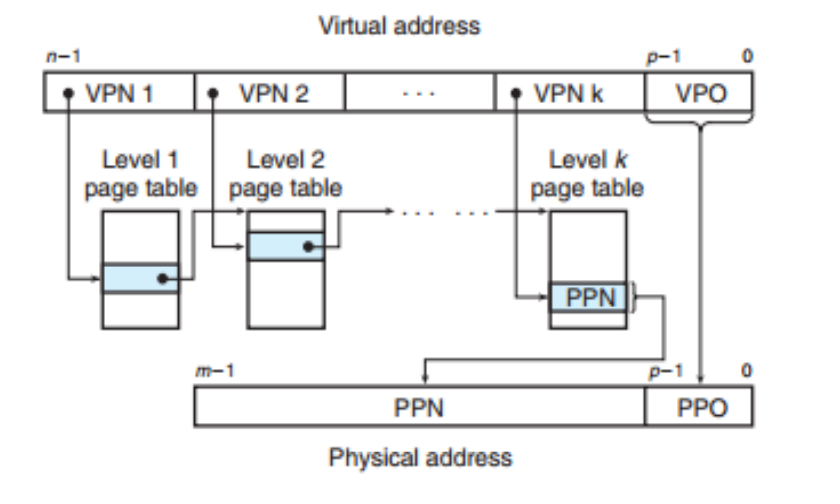
This hierarchical page table will minimize the memory we need by not allocating all pages(except we use up all page entries).
Consider the simple instruction below:
movq $0, (%rsp)
Here is what happens while running this:
In this situation, we encounter a page fault. The kernel will be informed by faulting address. Here are few choices that kernel can choose to deal with a page fault:
Let's see what's in the kernel memory:
So when a page fault of a valid address happens, the OS will do the followings:
Since it is possible that we run out of all page entries in the page table and we need to insert new pages into the table by evicting out some other old pages. Thus, we need some smart page replacement policy to help us choose the victim pages with having rather good performance. Here are five commonly used policy:
This method is in a FIFO style, the victim will be the next index of the physical page. This is a fair policy, avoiding some pages monoplying.
This method will simply evict a random page.
This method cannot be implemented since OS cannot predict future actions.
We may give "hint" to kernel which page could be evicted, in which way the performance can be bad.
SYNTAX: int madvise(void* addr, size_t length, int advice)
Advice value could be:
MADV_SEQUENTIAL
MADV_RANDOM
MADV_NULL
For more information about madvise: madvise
This method will evict the page that has not been used for the longest time.
Here is a brief example of how those policy works:
Assume we have five virtual pages: 0, 1, 2, 3, 4; and three physical pages: A, B, C
The reference string will be: 0, 1, 2, 3, 0, 1, 4, 0, 1, 2, 3, 4
First we will use Victim++(FIFO) Method:

Total will be 9 Page Faults.
Second we will try Oracle Method:

Total will be 7 Page Faults.
Third we will use LRU Method:

Total will be 9 Page Faults.
What if we increase our physical pages to four instead of three?
Let's redo the Victim++(FIFO) Method with four physical pages:

Total will be 10 Page Faults.
The situation EVEN WORSE! This is called Belady's Anomaly.
When it needs page 0, reads page 0 into the RAM and run it. Do not page in memory until it actually needs.
E.g. Program gcc --version only requires 3 pages.
Advantage: Avoid unnecessary work in small uses.
Disadvantage: Cannot batch read so performance may not be good.
Each page may have a modify bit associated with it in the hardware. The dirty bit for a page is set by the hardware whenever any word or byte in the page is written into, indicating that the page has been modified. When we select a page for replacement, we examine its modify bit. If the bit is set, we know that the page has been modified since it was read in from the disk. In this case, we must write that page to the disk. If the dirty bit is not set, however, the page has not been modified since it was read into memory. Therefore, if the copy of the page on the disk has not been overwitten (by some other page, for example), then we can avoid writing the memory page to the disk: it is already there.
Q: How to implement dirty bit without support of hardware?.
A: Maintain a dirty bit array in memory to track all the page. Mark all the page readonly initially. When a process writes a page, exception is triggerd and handled by kernel. Then kernel marks page as writable and set the corespondilng dirty bit in birty bit array.
When we do fork, we do not copy data but page table because copying data directly is expensive. Thus initially both parent and child share the same set of data. Then set all the shared page to be read only. Wenever one of the processes changes a shared page, interrupt is triggered and handled by the kernel. The kernel helps copy that page to a new physical address. Then the kernel changes the mapping of the page table in that process to the new physical page. However, using this method we still need to copy the page table which could be the bottle-neck when the page table is very large.
vfork() is a sort of thread-like fork(). vfork = fork except it has no need to copy the page tables of the parent process.
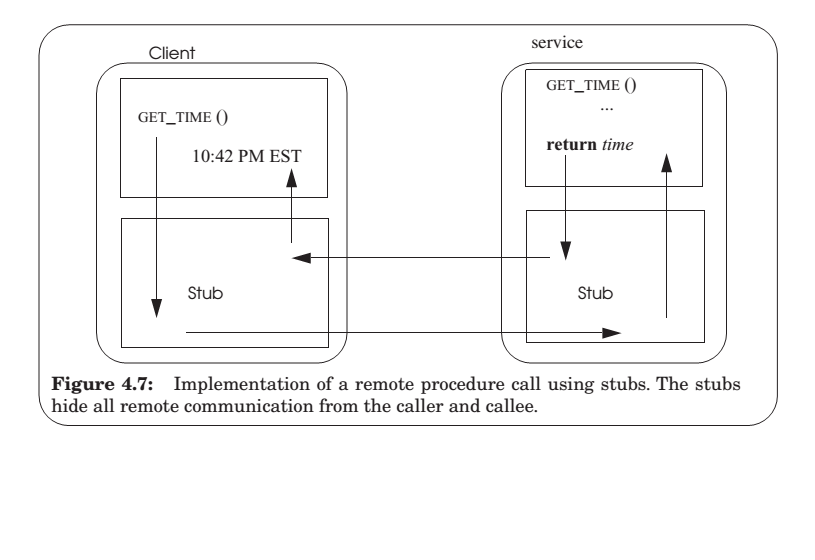
For a RPC, caller and callee live on different machine.
strcmp(a,b)
Pros: Enforce the hard mordularity.
Cons: There will be a performance bottleneck to access data.
read(fd,buf,sizeofbuf) does not work
Ex:
Caller is big endian machine, callee is small endian machine.
Caller and callee may have different instruction sets.
Caller and callee may have different data formats.
Masharlling:
In computer science, marshalling or marshaling is the process of transforming the memory representation of an object to a data format suitable for storage or transmission, and it is typically used when data must be moved between different parts of a computer program or from one program to another. Marshalling is similar to serialization and is used to communicate to remote objects with an object, in this case a serialized object. It simplifies complex communication, using custom/complex objects to communicate instead of primitives.
Unmarshalling:
The opposite, or reverse, of marshalling is called unmarshalling (or demarshalling, similar to deserialization).