Virtual Memory and Processes
CS 111 Lecture 16
Wednesday, March 2, 2016
Scribe: Emil Shallon
Virtual Page TablesSuppose you are using virtual memory and are setting up a system to manage your pages. Addresses on our machine are 32 bits, how should we set up the addressing for data?
- Single Level Page Table
We'll cut our address into two pieces: 20 bits as a virtual page number and the remaining 12 bits for the page offset. Each entry in the page table maps to a page in memory, and the offset shows where on that page our data is.
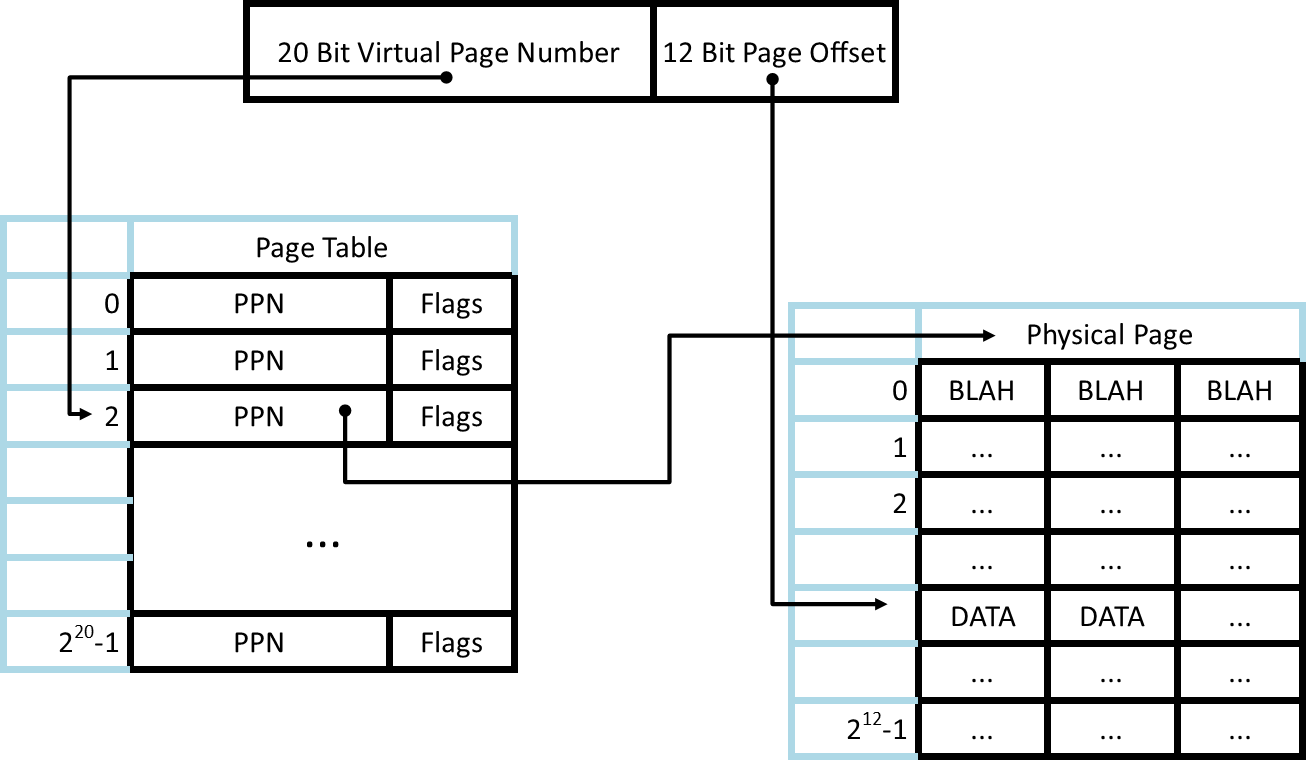
So far, so good. Our pages are 212 bytes each, or 4 KiB. This is a good size for each page. This design also gives us 220 pages in our page table.
Each process has its own page table. Each page table entry has 32 bits, so each process has to set aside 220 * 4 bytes = 4 MiB just for their process table. This is too much; we have to do better. - Multi Level Page Table
We can improve on the first design by decreasing the size of each page table. We'll attempt a multilevel approach: the first 10 bits will correspond to a top level page table, which maps to a lower level table. The next 10 bits will be the entry in this second table. Again, the last 12 bits will be the offset on the page of where the data is located.
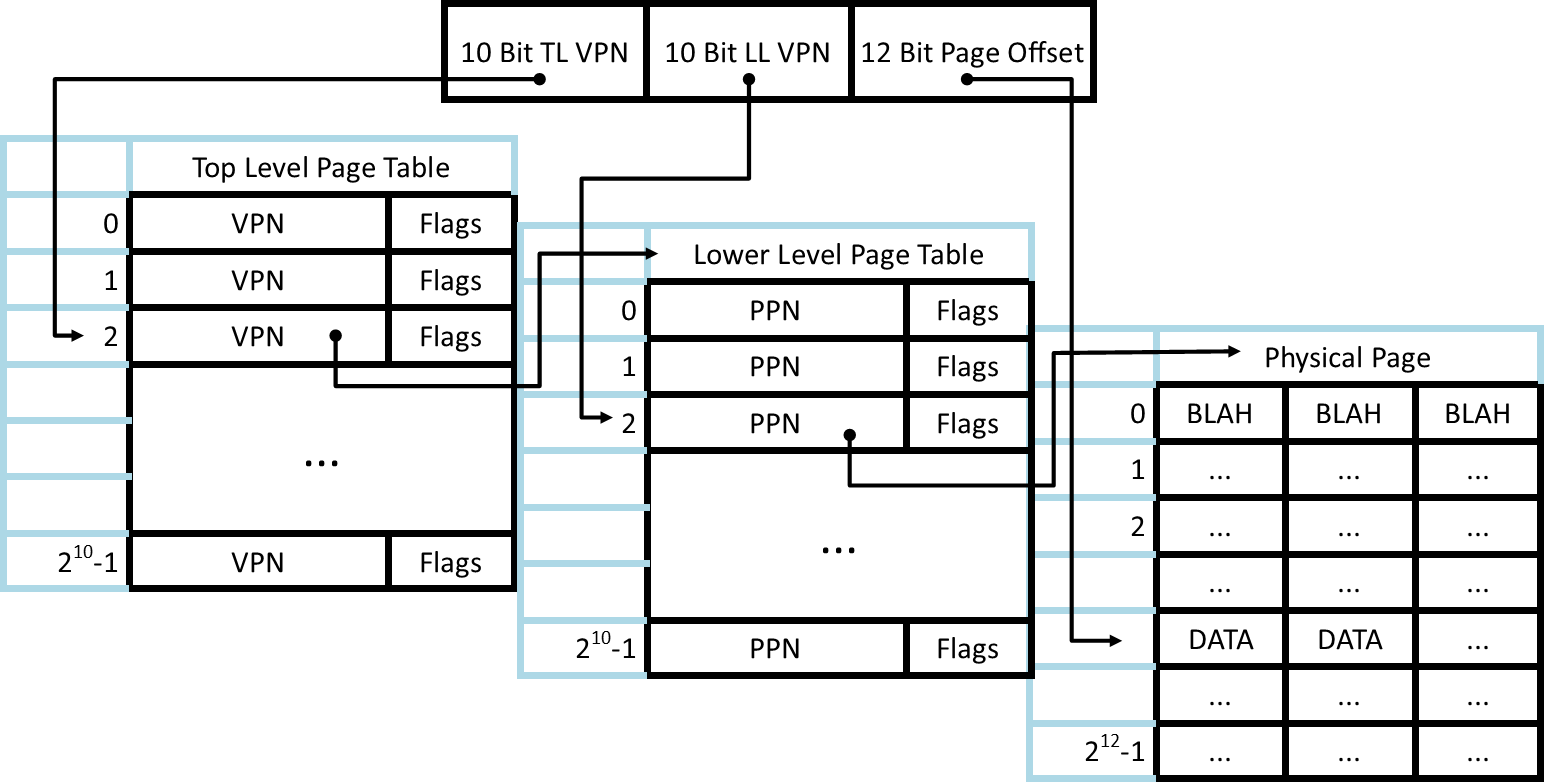
There is now less space that has to be saved for each process.
When the desired page is not in memory, it is a page fault. Triggering a page fault happens with a command like movq $0, (%rsp).
This command will trap and fall back into the OS. The kernel is informed of the faulting address and can take on of 3 approaches:
- Terminate the process
- Send SIGSEGV
- Arrange for the virtual memory to pull the page in and retry the instruction. This is the slowest option of all 3 for the kernel, but is done most often.
Upon taking the third approach, the proper data page is pulled into RAM from swap space on the disk. The previous instruction is attempted again and the process continues.
Guard PagesGuard pages are pages in memory that cannot be accessed. They have no content and exist solely to protect the stack. They are holes in virtual memory that you cannot access.
Guard pages are also seen at the ends of big arrays to protect the data around them.

While they are useful, guard pages come at a cost. Each page used is memory that cannot be stored to and is basically thrown away.
Handling Page FaultsWhere does all of this happen? Pages tables are held in kernel memory. The kernel has a function swapmap(process p, virtual page number vpn) that gives the direct address of the physical page on disk.
If we get a page fault of a valid address, it means that we ran out of memory and this page happens to be on disk in swap space, not on physical memory. We can read in the page using swapmap, but in order to keep it in memory, we'll need to kick out another page and send it back to disk. To bring this new page in to memory, we must:
- Choose a victim page
- Write the victim page back to swap space
- Update the victim's page table entry to be null
- Read in the new page from swap space on disk into the victim page's location in memory
This writing takes a lot of time, on the order of milliseconds. To not waste so much time, we let other threads run in parallel with the copying.
Page Replacement PoliciesNow that we've figured out that we need to remove a page, we need to determine a policy to pick the victim page. Here are some options:
- victim++ policy (FIFO)
- Increase the victim page by one every time that we need a new page.
- We move along the disk and remove pages.
- Every page takes its turn; this policy is extremely fair.
- Random number policy
- Victim is chosen randomly by calling random(number_of_physical_pages).
These first two policies are okay, but don't really offer great performance. They could easily remove pages essential to other processes and create a snowballing slow down as other processes need to read their data back in. Let's consider these next policies instead.
- Oracle policy
- Using an oracle, find the page that will be least needed in the future.
- Unfortunately, operating systems cannot tell the future and cannot predict what pages exactly will be needed coming up, so this policy is unrealizable.
- If the OS could tell the future, this problem, along with other problems, like the halting problem become easy (and most of us are out of jobs).
- madvise policy
- madvise(virtiual address start, int size, int advice) is a function that processes can use to help the kernel.
- The process gives the kernel hints about their usage so that the kernel can properly pick a victim page.
- The arguments are the virtual address in question, the size of that address, and the advice flag to be given.
- Some advice flag options include:
- MADV_SEQUENTIAL means that the program will run through data sequentially
- MADV_RANDOM means that the program will run through data randomly. This isn't very useful to the kernel.
- MADV_NONE
- Least Recently Used policy
- Guess which page will be least needed in the future by choosing which was least recently used.
5 virtual pages: 0, 1, 2, 3, and 4
3 physical pages: A, B, and C
Pages are referenced in the order: 0 1 2 3 0 1 4 0 1 2 3 4
Δ denotes a page fault
- FIFO
Total: 9 Page faultsAccess 0 1 2 3 0 1 4 0 1 2 3 4 Page A Δ0 0 0 Δ3 3 3 Δ4 4 4 4 4 4 Page B Δ1 1 1 Δ0 0 0 0 0 Δ2 2 2 Page C Δ2 2 2 Δ1 1 1 1 1 Δ3 3 - Oracle
Total: 7 Page faultsAccess 0 1 2 3 0 1 4 0 1 2 3 4 Page A Δ0 0 0 0 0 0 0 0 0 Δ2 2 2 Page B Δ1 1 1 1 1 1 1 1 1 Δ3 3 Page C Δ2 Δ3 3 3 Δ4 4 4 4 4 4 - Least Recently Used
Total: 10 Page faultsAccess 0 1 2 3 0 1 4 0 1 2 3 4 Page A Δ0 0 0 Δ3 3 3 Δ4 4 4 Δ2 2 2 Page B Δ1 1 1 Δ0 0 0 0 0 0 Δ3 3 Page C Δ2 2 2 Δ1 1 1 1 1 1 Δ4 - FIFO with 4 physical pages
Total: 10 Page faultsAccess 0 1 2 3 0 1 4 0 1 2 3 4 Page A Δ0 0 0 0 0 0 Δ4 4 4 4 Δ3 3 Page B Δ1 1 1 1 1 1 Δ0 0 0 0 Δ4 Page C Δ2 2 2 2 2 2 Δ1 1 1 1 Page D Δ3 3 3 3 3 3 Δ2 2 2
There are some interesting results from this example. As expected, the Oracle policy had the fewest page faults and thus the best solution. Second best was FIFO and then LRU. It was expected that LRU would perform better because it uses past information to better predict the future, but it does not in this example. In larger examples and real machines, LRU almost always outperforms FIFO.
Interesting to note is the fourth example. Although we allocate more memory for the system to use, there are actually more page faults. This is called Belady's Anomaly. It can happen for most policies, but most often for FIFO. Question for the reader: "Why can this anomaly happen with software and virtual memory caching, but not for hardware caching?"
Least Recently Used is one of the most common policies used. It is easy to understand and works well. So how do we implement it? The first thought is to add the most recent access time to the page table entry, and simply pick the smallest value. While this is a good idea, searching through all PTEs will cause considerable slowing for memory accesses.
Instead, the following approach is taken:
- Mark the access bits in each PTE as invalid.
- When a page wants to be accessed, it will fault. The kernel knows that this page is already actually in memory, so it won't reread the page in, but just adjust the access bits to the proper values.
- Whenever we need to pick a victim, we select a page that has invalid access bits. This means that it hasn't been accessed since the last time we reset the bits.
An alternative approach is to keep an additional array (independent of the hardware) with an entry for each page. For each page, if it has been accessed since the last reset, mark it with a 1. If it hasn't been accessed, mark it with 0. When we need to pick a victim, select one of the pages with a 0. We know that it hasn't been accessed in a while, at least since the last reset.
Virtual Memory OptimizationsThe following techniques can be used to optimize our approach to Virtual Memory.
- Demand Paging
This is a common technique. The initial thought when running a program is to read the entire program into RAM and run it, page faulting when necessary due to RAM constraints. The optimization is to only read in page 0 of the program into RAM and then page fault for the rest of the program.
This is useful in small uses of the program, when the entire program isn't needed in RAM. It also reads page 0 directly from the executable, not from swap space because it is read only. A drawback of this approach is that we cannot batch reads. We will read one page, then the disk arm may move to do something else, then will have to come back later to continue reading. This is costly, but overall Demand Paging is beneficial. - Dirty Bit
If we've only done reads on a page, then if we choose it as a victim, we won't need to write it back to the disk. This will save tremendous time. Program code is all read only, so an optimization of this type would be very useful, but how to implement it?
A first thought is to read the contents of a page on disk and compare them with the page in memory. This is counterproductive, however, as it costs an additional I/O, which in almost all cases causes more work than necessary. Alternatively, when we read in a page, we can compute a checksum on it and hold it in a table just for these values. We can then compare back later by computing the checksum of the current pages in memory. While this approach could work, it again has drawbacks: the table to hold these checksums will be huge and checksums aren't unique! 1 in 64,000 checksums will collide and give a false response, causing data to be lost.
The ultimate solution is to introduce a dirty bit. The dirty bit will be stored in each page's PTE. If the page has been written to, we raise the dirty bit to 1. When we write back to dick, we check the bit. If it's 0, then we don't need to write, saving lots of time. Even if the hardware doesn't support a dirty bit, it is easy to implement using a table. - vfork
Forking also causes some serious memory overhaul. Forking causes cloning and cloning means that we have to copy the page table and every piece of data. This is a huge waste, as mostly the child will only make a couple of calls to close(), dup(), and eventually an exec().
A solution is to only copy the page table when forking, not all of the data, too. The new page table will contain pointers to the original data. In each page table (parent & child), mark each file as read only. Each process can read to the file without affecting other processes. When either the parent or child wants to write, there will be a page fault. The kernel will realize that the file is actually writeable and will create a copy of the file for the parent and a copy for the child, marking both as read-write. The process can now write in the new process.
This approach is basically demand forking, only copying when there is demand for it. We can further improve, however, when you realize that copying the page table is also wasteful. The new solution is introducing vfork(), which is like fork() except that the parent and child share memory. The parent is frozen and cannot execute until the child process execs or exits. This approach gives the performance perks of processes, but also the memory advantages of threading.
The next big concept in this course is distributed systems. So far, we have only considered examples where our entire system was on the same machine. Now we expand to consider examples where components are distributed on servers across the world.
We introduce also Remote Procedure Calls (RPCs). These are just like the typical system calls we've seen before, but extrapolated to this new scenario. The network connects the caller and the callee. These new calls are different from ordinary calls in a few main areas:
- No shared memory. Because data on the caller machine isn't necessarily on the callee machine also, we cannot assume any shared memory. This gives us hard modularity, which is nice, but it severely increases the time to access data.
- No call-by-reference. The caller can't look at the callee's memory, and vice versa. Therefore, calls like read(fd, buf, sizeofbuf) won't work because the callee doesn't know where buf is.
- Format disagreement. The caller and callee may disagree about the format of instructions or data. There is no guarantee that caller and callee are the same time of machine/CPU/etc, and because all different types of machines use different formats, RPCs must translate between formats. The process through which two machines decide on a format for an RPC is called "marshalling."
Applications simulate RPCs as if they were ordinary system calls. There is an additional RPC layer underneath the system call layer. All RPCs therefore require additional overhead for shipping things over the network.

There are a lot of ways that these RPCs can fail: messages can be lost, messages can be corrupted, the network could be down, the network could be slow, the server you're trying to get in contact with might be down, or that server might be down. The worst part is that if an RPC fails, there's no way to determine why (so far).