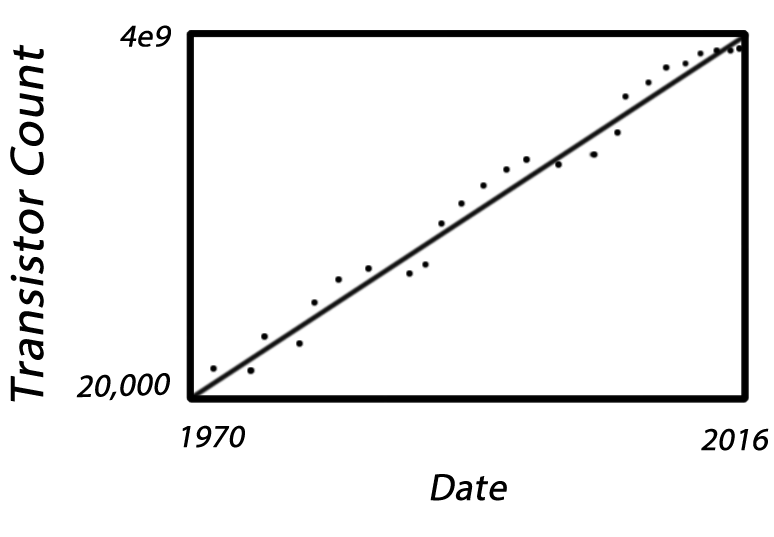
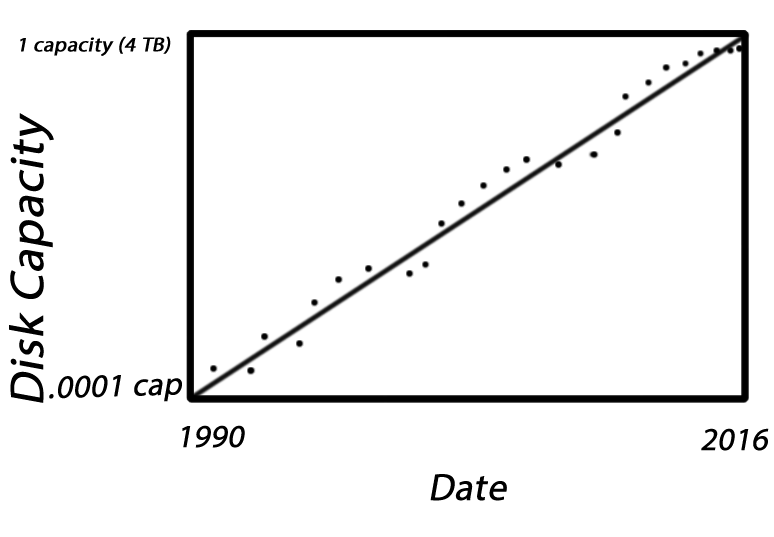
"This is a relief ... You cannot put money into a bank, and expect to get 5% interest forever ... 1.05
1 billion is a big big number, and something's got to give."
Paul Eggert, January 7 2016
void read_ide_sector(int s, char* a)//sector s, mem address to read into
{
inb(0x1f7); //goes to the disk controller at this location, model this call as subroutine
//in c, we could do this with something like static inline inb(int a) { asm }
//really turns into a single C instruction that the C compiler will generate, looks efficient
//even though this is one instruction, the instruction is slow
//because the CPU has to send signals over the wire to some device that is a long ways away
//has to then twiddle its thumbs and waiting for the disk controller to wait up
//relatively slow by machine instruction standards, not going to be executing billions of these per second
//Says to please retrieve the byte on the bus, the corresponding device address is that bus address
//Everything on the bus has an address that can load from and store into the bus addresses using the inb instructions,
//and the outb instruction is the reverse
//The disk controller is another computer, whose little computer is a program that you dont know what it is
//has some registers that it exposes to the bus, and has memory associated with it; talking directly to the disk drive
//read the manual, looked to see what this device is: 0x1f7 is the status register (one byte register)
//information about the current state of the disk controller, in particular if you look in that status register
//8 bits in the byte: looks this is ready, otherwise it's dead or busy
//make sure that the disk drive is ready
while((inb(0xf17) & 0xc0) != 0x40) //only care about top two bytes, make sure this is true, 0xf17
continue; //do this for style for him lol
//now the disk drive is ready
//1f7 is the status, cmd register, read from it is status, write to it is doing a particular command
//1f2 is the sector count, this is how we read a sector
//(can read multiple sectors at once, by putting a 3 on the end)
outb(0x1f2, 1); //read one sector
//Another register
//1f0 read data (and written)
//1f2 sector count
//1f3 Sector number to read from or right to
//1f4 Sector number to read from or right to
//1f5 Sector number to read from or right to
//1f6 Sector number to read from or right to
//1f7 status, cmd
//little Endian machine: low order byte is 3, high order byte is 6
//we know the sector number to read from is copy the integer into that value there, we do that with outb instructions
outb(0x1f2, s&0xff); //only bottom two bytes
outb(0x1f4, s >> 8); //24 bit number, outbyte instruction extracts the bottom 8 bits of that
outb(0x1f5, s >> 16);
outb(0x1f6, s >> 24);
//these are one byte registers on the bus
//Told everything it needs to know for the reads, what to read from and how many to read
outb(0x1f7, 0x20);
//made the disk controller busy to do the read command, now we need to wait for it to actually read the data
//0x20 stands for the READSECTOR command
while((inb(0xf17) & 0xc0) != 0x40) continue;
//Takes this loop put it into another loop and a function //can be called wait_for_ready
//Ready because moved disk around, arm at right spot, data rotated around,
//pulled data out and put it into the disk controller cache
//but we want the data! We can't look at the data directly as its not in our RAM
//We get it using:
insl(0x1f0, a, 128);
//insert long, copy it into our buffer (a)
//how many words we want to copy (128), (512/sizeof(int)
}