Lecture 3 - Monday, Jan. 11th
Scribe notes by: Aditya Raju, Christie Mathews, Srikanth AVR, Andrew Lin
Introduction
We are continuing the word count program from before. Last time we loaded the program, now we want to write the word count to the screen.
To do this, we use memory mapped I/O as opposed to programmable I/O. You can move data into a certain region in memory, and the data there is displayed to the screen. The diagram below shows the basic idea:
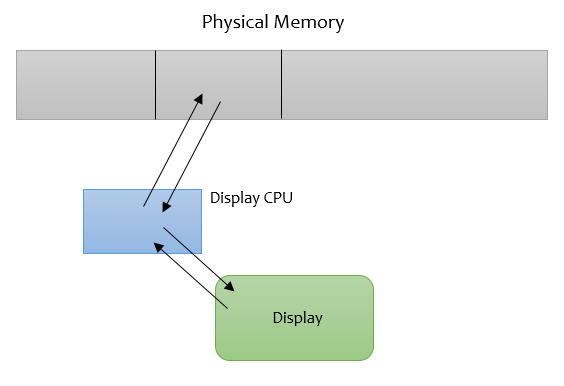
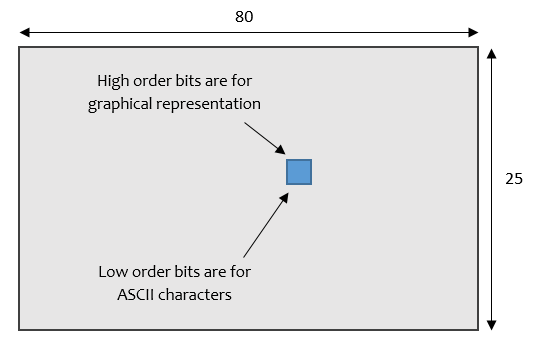
The screen is basically a 80 x 25 grid of chars, which uses 16 bits to represent each location on the screen. The lower order 8 bits is ASCII, and the high order 8 bits are used to control graphical appearance.
Suppose we have the # of words sitting in a register somewhere and we want to put that on the screen. The following function does that:
void output_to_screen(long n){
//Address of screen is 0x68000, and this allows us to access middle of screen
short* p = (short*) 0x68000 + 80*25/2 - 80/2;
//Takes the number of words and puts it into the lower order 8 bits in the correct order
do{
*--p = (0x700 | (n%10 + ‘0’));
n/=10;
}while(n!=0);
}
Now we write the code to actually physically count the words:
void main(void){
long nwords = 0;
int s = 1000;
bool inword = 0;
char buf [512];
for ( ; ;){
//Read from the sector and then store the results in a buffer named buf
read_ide_sector(s++, buf);
//Look through each character of the buffer
for (int j = 0; j < sizeof(buf); j++){
//If you reach the end of the file (‘\0’) then print to screen and halt
if (!buf[j])
done(nwords);
// Find out if the char is a letter or not.
bool isletter = (‘a’ <= buf[j] && buf[j] <= ‘z’);
//If it is a letter and you are not in a word, increment words count
// If you isletter = 1 and inword = 0, increment word count
nwords += isletter & ~inword;
inword = isletter;
}
}
}
void done(long nwords){
//print the words to the screen and stop the program.
output_to_screen(nwords);
halt();
}
Issues with our code and how to make it better
DMA
One issue is that in our current program, we are copying data twice, once from the disk controller to the CPU, and then from the CPU to the RAM. This is a common issue in programming I/O. To fix this, we can use DMA (Direct Memory Access) to copy the data directly from the disk controller to RAM. We first must tell the disk controller where to copy the data, copy the data over, and signal the CPU that this happened. The image below shows an example of DMA:
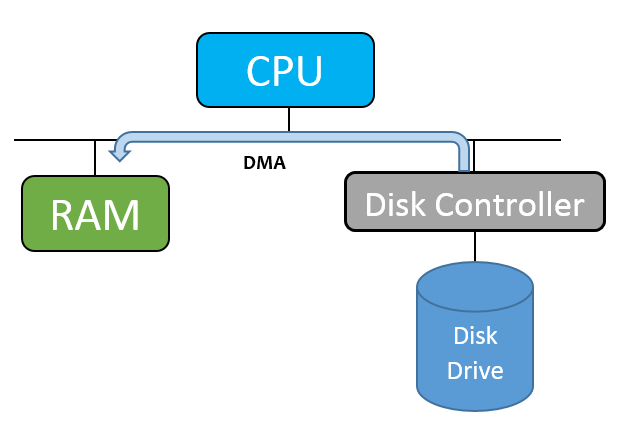
In our case, DMA is not that applicable, because we need to copy the data from RAM to the CPU to count the words anyways.
Double Buffering
Another way we can speed up our code is to use double buffering to read ahead (also called interleaving). For example, in a simple program, the use of double buffering can speed up the program really well (image from CS111 Fall 2014 notes of Long Nguyen):
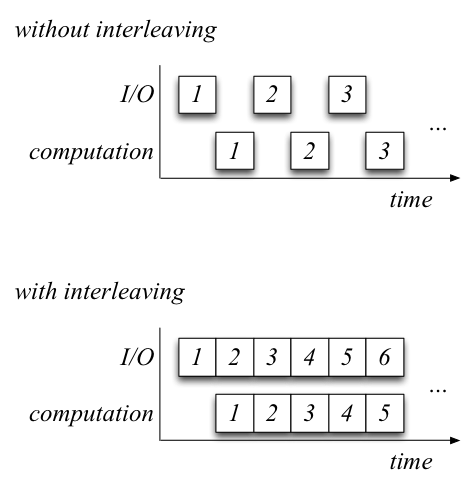
But this example assumes the computation time is close to the read time. In our case, the computation time is very short compared to the read time, so the computation must still wait for the read ahead to happen, so it is not very effective in our case.
Multitasking
In order for us to speed up our program the most we could use multitasking. In this case, we would read ahead with multiple different buffers, and stagger computations of those buffers to run in the time that the next read ahead for those multiple buffers happens. The diagram for what this might look like:
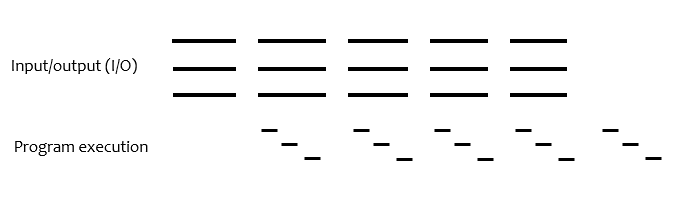
For this, we need multiple processors and it is very complex to program, but it will speed up a our program a lot. This moves us to our next stage: how to write up programs/functions that could be used by other programs to speed up their processes as well.
Modularity and Abstraction
How do we write these programs? The techniques are called Modularity and Abstraction.
Modularity is splitting up the program into pieces, or modules. The cost of maintaining a module with n lines is O(n^2), because the cost of finding a bug is n * the number of lines that it depends on. The diagram below represents a system divided into multiple modules. The edges between the modules represent the interface for communication between the modules.
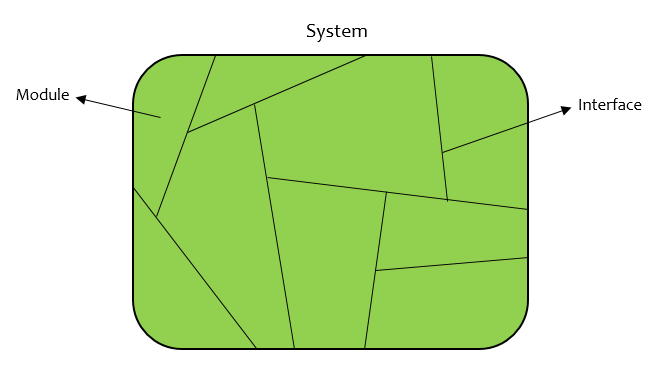
Abstraction correctly splitting up the modules so that they have functionality for a variety of uses.
How do you measure the quality of modularity and abstraction of a program?
Let’s analyze char *readline(FILE *f); and why it is a BAD design for OS.
Performance: It is unbounded work, as the line can be really, really long, which leaves to much overhead when the work to be done is relatively small
Robustness: The app will crash with lines that are super long
Neutrality: Different apps will want to use different characters an end of line characters, but this forces a convention on app makers.
The only measurement of modularity and abstraction that this program passes is simplicity.
A better version of readline
Based on the above-mentioned design problems with the function: char* readline(File *F),
a better function is:
ssize_t read(off_t byte_offset, void* buf, size_t bufsize);
*This implementation was further improved when this function was released as part of the Unix operating system.
The big idea of Unix was that everything outside the program could be abstracted as a file. For instance, the disk and flash were defined as Random Access Devices while the network, mouse, keyboard, and display were defined as Streaming Devices.
To update this read function to work with this abstraction of everything outside of programs being files, the off_t byte_offset argument in read() was changed to int fd. Thus, while only Random Access Devices could be read from using byte_offset, both Random Access Devices and Streaming Deices could be read fro using these fd (file-descriptors). While this implantation did add an element of complexity with its new layer of abstraction, it also increased the simplicity with which users could employ the function. Thus, the read function we have today is:
ssize_t read(int fildes, void*buf , size_t nbytes)
*To go to a specific location in memory, it was once necessary to make an lseek(int fd, off_t where, int flag) to move the file-poistion and then a read(). However, unix developers created a pread() function that simplifies this process with one call. For example, a database application wouldn’t have to do two system calls to go to a random location; in modern unix, it could just use pread().