Lecture 3: Modularity and Virtualization
CS 111
Jan 11, 2016
Scribe notes by Grace Tsang and Joanne Park
void read_ide_sector(int s,int a) {
outb(0x1f2, 1);
outb(0x1f3, s);
outb(0x1f4, s << 8);
outb(0x1f5, s << 16);
outb(0x1f6, s << 24);
outb(0x1f7, 0x20) //0x20 is command: read sector
while ((inb(0x1f7 & 0xc0) != 0x40))
insl(0x1f0, a, 128);
I. Writing a Wordcount Program
Now, we have to write a subroutine to output a number to the screen, as per the program specification. It is possible to use programmed I/O, just as we used inb and outb for the disk controller, but we are going to use memory-mapped I/O instead.
Memory-mapped I/O allows us to use, for example, movb, in order to move data from a register to memory: except that it's not RAM/memory in the ordinary sense, but rather a place that does I/O.
Somewhere in physical memory is a frame buffer, a set of memory locations that are displayed directly on the computer screen rather than being ordinary memory.
Essentially, another CPU will read out of this frame buffer and display what it sees there to the screen, 60 times a second.
IBM PC Screen Method
- Model the screen as a grid of 80x25 characters, each one represented by 16 bits
- Low order 8 bits is ASCII
- High order 8 bits contain information regarding the graphical appearance
- Suppose that we read the manual and find out that this frame buffer begins at 0xB8000 and takes 80*25*2 bytes/char = 4000 bytes starting from that location
We now begin to write our output function. We might naively attempt to write it like this:
*p = x;
However, as we need to display the number as ASCII characters, this obviously does not work. Further, the ASCII character is stored in the low order 8 bits. Let us assume that we want the characters displayed to be in gray on black, which is represented by higher order bits of 7. Then our program becomes:
This versions still has issues: it does not handle a wordcount of 0 (it will output a blank screen in this case), and it prints the digits in reverse order. We fix these issues and also attempt to print the result closer to the center of the screen:
Finally, we need to know when we are finished counting words in the file, so we establish the convention that end of file is indicated with a null byte. Now, we can write the full program:
bool nwords = 0;
int s = 1000;
char buf[512];
for(;;){
for (int j = 0; j < sizeof(buf); j++){
nwords += isletter & ~inword;
inword = isletter;
halt();
Notes:
1) This is not a main function in the normal sense since it runs without an OS. Also, it does not return (has return type void) because there's no caller to return to
2) int s is an arbitrary location to start reading. It's important that this sector is not one we are otherwise using: for example, it would be invalid to attempt to start from sector 0, where the MBR is located.
3) Calling halt is necessary because otherwise, control would return to main after printing, read in another null byte, output, and repeat forever.
The general logic of this is to have a boolean to indicate whether or not we are in a word, and to increment the counter when we enter a word (that is to say, when isletter is true but inword is false).
II. Problems with Wordcount Program
1) First, when we get data off of disk, we do it rather inefficiently. Since we are using programmed I/O, we must copy data twice: once from the disk controller into the CPU, and once more from the CPU into RAM, doubling bus traffic.
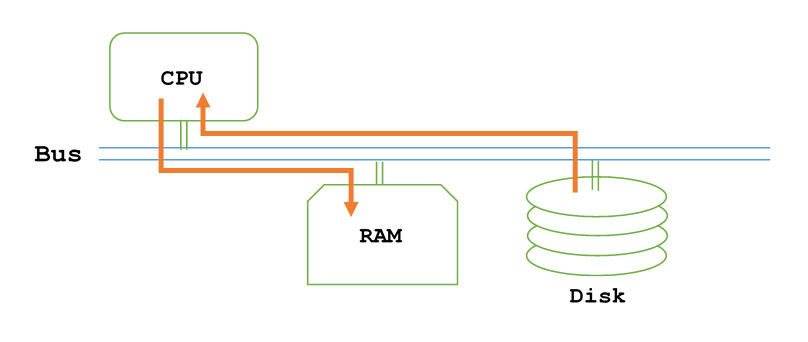
To address this issue, we can use DMA, direct memory access, to have the I/O device send a copy of the data directly to RAM. Then, we will only have to make one copy of the data to move around:
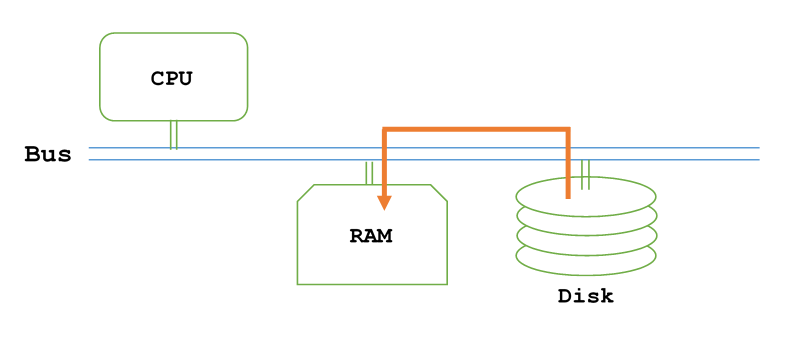
However, even in this case the CPU must still somehow be notified when the DMA is done. Since it would be too inefficient for the CPU to tie up the bus constantly querying the DMA, the DMA must somehow notify the CPU, which in turn adds complexity.
In addition to this, recall that in order to get the data from RAM to use in our program, we have to copy the data from RAM to CPU anyways. Due to the small buffer size of our program, it could be that DMA does not provide much performance benefit anyways, as generally larger buffers work better with DMA.
2) Double Buffering
Suppose that instead of wordcount, we write a crypto app which requires a lot of CPU: it must read data off the disk and decrypt it.
The program has the following pattern:
2) Starts doing Elliptic Curve Cryptography on the data read in, taking 10 ms/buffer to complete

As time goes on, the program would alternate between I/O and ECC, and the CPU load is only 50% as it spends half the time waiting for disk to ready
To address this issue, we use double buffering: we read the next buffer's data while the CPU is processing current buffer's data. This program has the following pattern:1) Fill buffer 0
2) Compute buffer 0 while reading buffer 1
3) When done, get the next buffer from disk controller
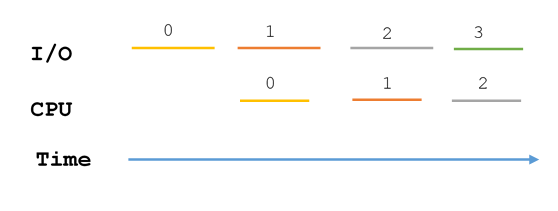
However, if the processing takes much less time per buffer than reading in does, as in our wordcount program, double buffering provides little benefit:

On the other hand, if we had 10 files on 10 different disk drives, and we wanted to count all their words at once, multitasking could improve performance:
1) Do I/O for all 10 devices in parallel (multiple buffers)
2) Then, as long as the CPU takes 1/10 of the time to process a buffer as it takes to read in, we can keep the CPU constantly busy and finish wordcount for all 10 files in the same time it takes to run wordcount once.
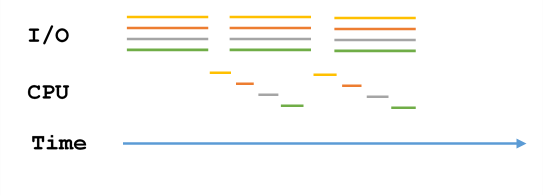
3) The Biggest Problem
III. How to Scale Up (or How to Cope with Complexity)
In order to implement these optimizations without rewriting all the applications, we will use the following techniques:
1) Modularity
Definition: Modularity is taking your program and splitting it up into pieces (or modules), where each individual piece becomes more manageable than the whole.
A hand-waving proof: The cost of maintaining a module with N lines of code is roughtly O(N^2), because the number of relationships between a pair of lines of code is O(N^2). Also, since maintenance is mostly dealing with bug reports, you have to first find a bug (O(N)), and then in order to fix it you have to find where the fix goes, also an O(N) operation.
That aside, it is generally good to have modularity in order to keep maintenance costs low. Note, however, that this is limited by the fact that the number of possible interactions between modules if also O(N^2).
2) Abstraction
Definition: Abstraction is dividing and connecting modules in the right way, such that the maintenance job becomes easier.
We want to find the pieces of a program which divide nicely, in a way that solves the abstraction problem and the modularity problem. This is a goal for this course.
How do you measure the quality of modularity and abstraction?
Simplicity involves both ease of use and ease of learning, and one of the two does not imply the other. Ease of learning is denoted by a short manual, but a short manual does not imply ease of use. For example, a Turing machine is simple to learn to use, but not very much fun to program.
2) Robustness
To be robust is to be tolerant of errors, large inputs, and so on. Your program should still work when operating under harsh conditions: if the device is flaky, if the problem is large, or if hackers are attempting to break in.
If one module runs into an error, other modules should not be affected.
Typically, modularity will cost you some performance. You will have to build interfaces between modules, a design problem. At runtime, crossing module boundaries will cost in terms of CPU and memory: these minor costs are inevitable. Occasionally, you will have major costs that come up when you have to ferry a question and its answer is across many modules just to do something simple: this should be avoided, but drawing the boundaries between modules poorly will make this issue unavoidable.
4) FlexibilityOne example of this is the Unix/Linux file system. '\n' is not a special character in UNIX, and there's no special line processing at all: carriage returns, newlines, or a combination are all supported. It is up to the application to figure out where the line boundaries are: the cost of flexibility is that it decreases simplicity. If you want UNIX to read a line of input, you must write a lot of code.
It is important to remember that there are trade-offs between these things.
IV. Interfacing
Communicating between the part of the OS that does I/O and the rest
Deciding on an interface to use between the part of the OS that does I/O and the rest of the OS is trying to find the best dividing line between these two sections. We specify this interface with function declarations inside the OS that other applications can call. We begin by considering a simple and bad design for the interface:
What makes this design good, and what makes it bad?
This interface has unbounded work, meaning that if passed a very long line, it will take seemingly forever for the answer to come back. We need a bound on the amount of work it needs to get something done. Furthermore, this interface also has unbatched work: if the input is just empty lines, the application will have to call readline() over and over again, resulting in a lot of function call overhead for each line of input, even though the amount of work to be done is in fact relatively small.
2) Robustness
With big lines of data, applications will crash when memory runs out.
3) Neutrality
This interface forces a line ending convention on the application, so it is not neutral.
4) Simplicity
The only benefit of this interface is that it's simple, but that is not enough to overcome its shortcomings in other design principles.
Now, we work from the other direction: instead of starting with a simple, bad design, we will start with something very low-level that we know works: we will reuse our read_ide_sector() interface from the wordcount program (previous lecture):
How can we improve this design?
1) Robustness: not very good, since it does not report I/O errors. We should at least have it returning a bool so that we know whether or not it successfully read a sector. In fact, considering that it could have failed for many reasons and that it could be useful to know those reasons, we can make it return an int so that it can return different values for different errors.
2) This design assumes that each disk sector is 512 bytes. Instead of doing this, we should specify how many bytes to read and not worry about the exact sector. This would result in:
where byte_offset is the byte offset from the start of that file/device.
3) In order to add support for other types which are not char*:
4) Then, we realize that on the x86-64 processor, bufsize is limited to 2 GiB: in order to improve flexibility, we instead use the system-dependent type size_t, giving us:
size_t is an unsigned long, 64 bits on the x86-64.
5) Also, we could use the type off_t for byte offset, which is a 64-bit signed quantity on both the x86 and the x86-64, since 32 bits is not sufficient to describe a byte offset even on the x86. We obtain:
6) Then, in order to tell how many bytes were successfully read, we will use a return type of ssize_t (a long):
Similar to Linux read, our read will return -1 for all errors and set errno appropriately. Notice that this interface will still run into problems if the value of bufsize is greater than ssize_max.
As it turns out, our design has been approaching Unix read(). So, let us examine the remaining differences between our interface and Unix read():
1) Unix read takes an int fd, which allows reading from any file. This is an opaque file handle, and the OS keeps track of all the detail.
2) The byte offset goes away, and Unix read is simple:
This is due to several reasons, including one of the Big Ideas of Unix:
Everything outside the program is a file.
Disk, flash, network, mouse, keyboard, display, etc: everything is modeled with the same API (they're all represented as files!), since the idea behind Unix is to build a good kind of modularity that works with anything.
In the Unix file system, there are 2 major categories of I/O devices:
Random access devices: an arbitrary piece of memory can be retrieved from this relatively quickly. Disk and RAM are random access.
Stream: data moves like a stream through the system, and when it passes it never returns. Network, mouse, keyboard, and display are examples of stream devices.
In order to support stream in addition to random access, we must discard the notion of byte offset. The advantage of this is that it allows our API to work with streams. The disadvantage is that we lose random access capability.
In order to counter this and bring back random access capability, we have another system call:
The OS has to keep track of the current file position: it starts at 0 and adds N to the file position every time N bytes is read, and lseek() sets the file position.
The idea behind this design is that the extra complexity is worth the extra abstraction. However, this doesn't change the fact that 2 system calls (read() and lseek()) take longer that one, due to overhead.
Thus, modern Unix systems also have a function, pread(), to combine the two:
The addition of pread essentially reverses the decision of the original designers and adds complexity in order to get back performance. In most cases, however, pread() is unnecessary.