CS111: Lecture 3
Scribe Notes for Monday, 2016-01-11
By Connor Kenny, Justin Liu, and Lake Mossman
Last time: Figured out how to boot the word counting program but couldn't get it to do anything.
Solution: How to write the answer to the screen:
- Programmed I/O (special in byte out byte) ← Don't use this time
- Memory Mapped I/O ← Use this instead!
- Instead of special instructions, just use loads and stores
- Use movb instruction, but not actually on memory - instead on I/O space in memory
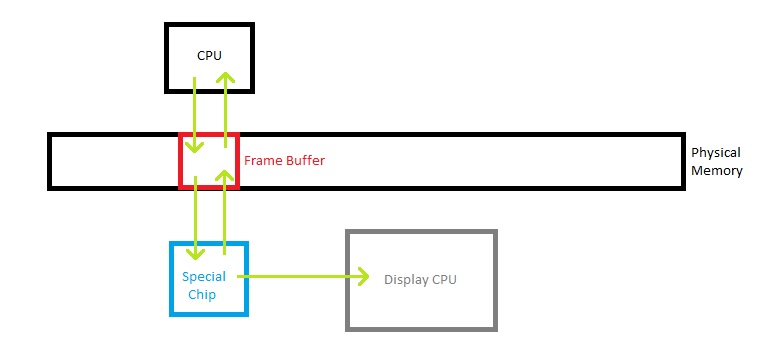
- Small region of physical memory that is a frame buffer, not RAM in ordinary sense
- Think of it like a special chip in RAM
- Display CPU - read bytes out of display RAM and puts on screen 60x/sec
- Screen = 80 x 25 grid of characters
- Each entry is single character, model it as an array of 80x25 16 bit quantities
- Lower 8 bits = ASCII
- Higher 8 bits = graphical appearance (white on black, blinking, etc.)
- At location 0xb8000
- 80 x 25 x 2 = 4000 bytes (decimal)
- Convert to Hex to figure out upper bound of array
- Write a function to print - let formatting be gray on black - high order bits are 7:
void output_to_screen(long n) {
/* WRONG - SEE NOTES FOR EXPLANATION
long *p = (long *) 0xb8000;
*p = n;
*/
short *p = (short ) 0xb8000 + 80*25/2 – 80/2;
do {
--*p = (7 << 8) | (n % 10 + ‘0’);
n /= 10;
} while ( n != 0);
}
- Notes about above code:
- The input, n, is the number of words that we want to output to the screen
- Can't use int in argument because we could have more than 2^31 words
- Initially set *p to be long → incorrect because it stores gibberish in extra bytes
- Use short because it holds 2 bytes - perfect for our 16 bit implementation
- Can't use 0xb8000 because that will print answer in the bottom right corner
- Need to add 80*25/2 to get halfway up the screen on right side
- Need to subtract 80/2 to get to middle of screen
- Initially had ++*p and a while loop instead of a do while
- This is incorrect because it would print backwards!
- This line shifts 7 (our formatting preference) over 8 bits and ORs it with the least significant digit (returned as character by adding with '0')
void main(void) {
long nwords = 0;
bool inword = 0;
int s = 1000;
char buf[512];
for (;;) {
read_ide_sector(s++, buf);
for (int j = 0; j < sizeof(buf); j++) {
if (!buf[j])
done(nwords);
bool isletter = ‘a’ <= buf[j] && buf[j] <= ‘z’ || ‘A’ <= buf[j] && buf[j] <= ‘Z’;
nwords += isletter & ~inword;
inword = isletter;
}
}
}
- Notes about main:
- There is no return because there is no OS (nothing to return to)
- Need inword to determine if inside word or about to enter new word
- s is chosen arbitrarily as a high number to avoid stepping on anything useful (can't use 0 because that is the Master Boot Record, other low numbers could be the word count program itself)
- Want data to signify the end of the buffer
- We choose nullbyte ('\0'), but this is not universal
- Write the done(long nwords) function:
void done (long nwords) {
output_to_screen(nwords);
halt();
}
- Notes about done:
- If there is no halt, this would return to main, and it would continue to count
- This would continue on forever, so we use halt to make sure it stops!
- If there is no halt, this would return to main, and it would continue to count
Complaints / "Bugs" / Issues:
- CPU talks to both RAM and disk control
- Copies the data twice (Disk controller to CPU, CPU to RAM)
- Common problem for PIO
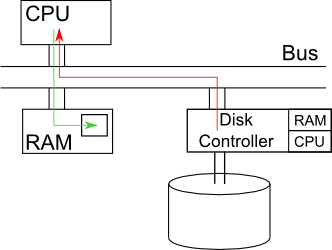
source: http://www.cs.ucla.edu/classes/fall10/cs111/scribe/3a/
- Solution - DMA (direct memory access)
- Disk controller can be bus master
- Go straight from disk controller to RAM which leads to less bus traffic
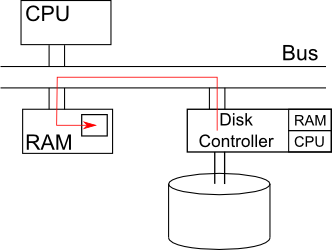
source: http://www.cs.ucla.edu/classes/fall10/cs111/scribe/3a/
- Catch - CPU needs to be notified when DMA happens
- CPU can be notified somehow using techniques (we don't know yet)
- This adds complexity because we need to be prepared for a signal at any time
- Another Catch - End up copying data back to CPU anyway
- We have to check for null bytes
- Notes about DMA:
- In our case, it does not increase performance because data fits in the cache
- DMA has much better effects when data is larger (doesn't fit in cache)
- In our case, it does not increase performance because data fits in the cache
- Copies the data twice (Disk controller to CPU, CPU to RAM)
Suppose our app is a cryptography app.
This requires lots of CPU power, especially if there is a 10,000 bit key.
CPU is split between doing I/O and ECC (elliptic curve cryptography)
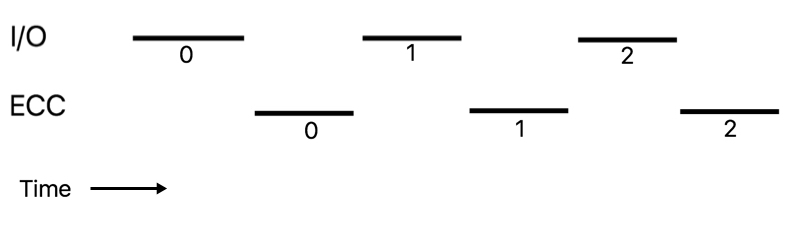
In this case, CPU usage is only 50%
- Half the time spent waiting for I/O
- Half the time is spent doing work (ECC)
A solution to get to 100%: use double buffering
Double buffering is the act of reading the next buffer's data while processing the current buffer.
This can almost double the performance if the time needed to read and to compute are the same.
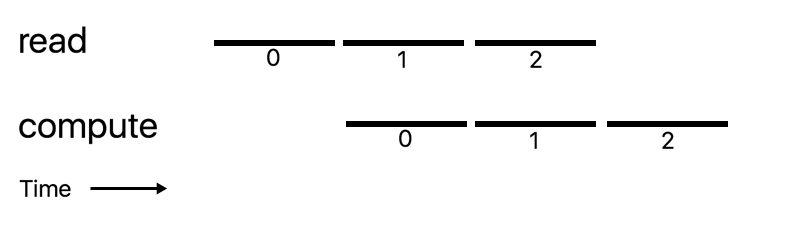
Suppose we applied double buffering to our word count program. Will we get double the performance?
No, because our computation is very fast compared to our reading (reading from a hard disk drive is relatively slow).
It would go from:
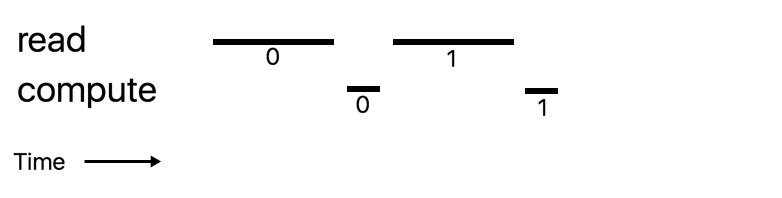
to
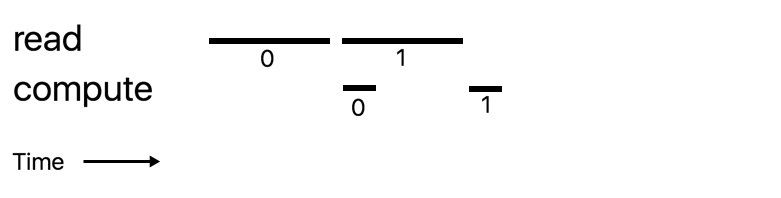
Which is not much of a performance gain.
Would it ever make sense to do triple buffering?
Yes, if you had 3 different actions to be performed at the same time, e.g. read, write, and compute.
How else can we speed up?
Suppose instead of just having 1 file, we have 10 files on 10 disk drives, and we want to count all of them at once.
We can speed this up with multitasking, where we do the I/O in parallel and the computation in sequence. As long as the computation is 10x faster than the reading, the computation for all 10 files can be done during the parallel reading of the next 10 files.
If we want to achieve all of these performance increases for our word count program, we would need to write the code for multitasking, DMA, etc. ourselves, which would be very difficult and time consuming.
Additionally, if we wanted to do these for other functions that we write, we would have to rewrite everything, so it is very hard to generalize and scale up our program.
How can we scale up these programs?
How can we get fancier performance tricks without rewriting every application?
Two techniques:
- Modularity - splitting programs into pieces
- Each piece becomes easily manageable
- The cost of maintaining module with N times is O(N^2)
- Why does the cost of maintenance grow faster than the number of lines?
- The number of relationships between pairs is N^2
- If you have a bug in the module, you must:
- find out where the bug is, which takes O(N) time
- find out where the fix goes, which also takes O(N) time
- Main point: there is a big benefit in keeping modules small
- Abstraction
- Drawing lines between modules in the right places
- Taking a messy program and finding the natural divisons
- Finding divisions in such a way that makes maintenance easier
- e.g. if you can arrange so that double buffering code does not care about everything else, and everything else does not care about double buffering code, the problem is solved
How do you measure the quality of modularity and abstraction in a program?
- Simplicity
- The simpler the OS is, the better
- Simplicity could mean ease of use, or ease of learning
- Ease of use: difficulty to write code for the OS
- Ease of learning: difficulty to learn to use the OS
- Robustness
- How well does the system behave when under harsh conditions?
- Harsh conditions could be errors, large inputs, flaky devices, attacks from outside, etc.
- Performance
- How fast does the program run?
- Many times, better performance = less robust and more complicated, but the faster OS usually wins in the marketplace
- Modularity costs performance (minor costs are inevitable)
- If modularity is badly set up (such as a module must go through several other modules to talk to the desired one), the costs could be huge
- Flexibility
- How well can the OS be redirected? Can it do a lot of different things with the same interface?
- Consists of a lack of assumptions (e.g. do not assume that sectors are 512 bytes)
- Neutrality
- OS does not care what apps do with the data, it just gets the data to them
- Example: Linux model where it treats every file as a stream of bytes, not giving special function to newline, etc.
- Cost to this flexibility: programs are a little harder to write (less simplicity)
I/O Interface
How could we design a read function?
char *readline(FILE *f);
This is a BAD DESIGN for OS.
Why is it bad?
- Performance
- This function reads a line from a file and returns a pointer to the line
- Suppose this line is very long
- This function will be very slow (it is performing unbounded work)
- WHen you try to read a large line, it could seem like it's taking forever, which is not a good design for the user
- Suppose the input file is just a large collection of empty lines
- This function will keep calling the function over and over just to read single newline characters
- This is a lot of overhead function class cost just to read newlines
- Robustness
- If the input goes on forever, memory will keep getting allocated
- Eventually, the program will try to allocate too much memory and crash
- Neutrality
- This function forces the '\n' convention for ending a line
- Some people may want carriage returns rather than newlines to indicate the end of a line
- Simplicity
- Yes, this function is simple (the only thing good about it)
Now let's try approaching it from the other direction: good performance, but not as simple:
void read_ide_sector(int s, char *buf);
- This is bad because it does not tell us anything about I/O errors.
bool read_ide_sector(int s, char *buf);
- This tells us if it worked or not, but we want more information about what goes wrong if it fails.
int read_ide_sector(int s, char *buf);
- This can tell us more info because it returns an int, so different return values can mean different types of errors (Robustness++, Simplicity--)
- One problem: what if sectors are not 512 bytes? We ant to be able to specify how many bytes to read.
int read (int byte_offset, char *buf, int bufsize);
- Now we do not need to worry about how many bytes there are per sector (Simplicity++, Neutrality++)
- Because
bufsizeis an int, this function is limited to 2^31 bytes = 2 GiB
ssize_t read (off_t byte_offset, void *buf, size_t bufsize);
- Here we changed all of the int types to *_t types so that they could fit more information, and they take into account the CPU architecture in their sizes (Neutrality++)
- size_t is an unsigned long, 64-bit on x86_64 and 32-bit on x86
- off_t is a 64-bit unsigned long on both architectures
- ssize_t is a signed long, so that the function can return the number of bytes read on success (which is always 0 or positive), or it can return -1 on error
- Caution: size_t can represent larger values than ssize_t, so
bufsizemust be a value that is able to be return as an ssize_t - Since we want the buffer to be able to take in chars, floats, doubles, ints, etc. we make it void *, which takes in any type of pointer (Flexibility++)
We want to generalize this so that it can handle any type of file.
UNIX read:
ssize_t read (int fd, void *buf, size_t bufsize);
- The file descriptor (fd) tells us which file to read, and the OS keeps track of file info
- There is no
byte_offsetin this implementation
Big idea of UNIX: everything outside the program is a file (disk, flash, network, mouse, keyboard, display)
The above read function treats every file as a stream of bytes so that it will work with any type of file. To do this, it gets rid of byte_offset, which inherently gets rid of random access.
To get back random access, we have another function:
lseek(int fd, off_t where, int flag);
So now you can move disk arm/flash pointer to a certain byte in the file with lseek, and start reading from there, implementing random access (Performance++, Simplicity--).
One problem with this: suppose I want to do a lot of random access reads, then I would have to do two instructions for each read.
Solution: another function
pread(...)
This combines lseek and read to implement random access reading (Simplicity++).
So far we have talked about where to split things up, but not how to do it.
Mechanisms for modularity:
- Function (or method) calls
- Caller calls functions, waits for them to return, then does something with the return value
- + Simple, well understood, fast
- - Things can go wrong - run out of stack space, infinite loops, smash stack, etc.
- Client-server
- Break application into different virtual computer
- + This is more robust (handles problems better)
- - Slow, not good enough for high performance applications
- Virtualization
- Eggert will talk about this in the next lecture.
Summary:
This working example of creating a word count program without an operating system emphasizes the benefits of having an OS. All of the ways that were suggested to speed up the program, such as DMA, double buffering, and multitasking, require a lot of code in order to make them function correctly, and if we did not have an operating system, we would need to write all of this code ourselves, and possibly modify it for every program that we write. The solution to these problems are modularity, i.e. splitting up the program into smaller pieces, and abstraction, or finding the natural divisions in a program. These two concepts are evident in most well-known operating systems, and Professor Eggert went on to describe the aspects by which one can measure the quality of modularity and abstraction in a given OS.
One aspect, simplicity, is the measure of how simple an OS is to learn how to use and to write code for. Another feature, Robustness, defines how well a system behaves under harsh conditions. Performance measures how fast a program can run, and usually is a cost to modularity. Lastly, flexibility describes how well an OS can be used for a lot of different tasks. Professor Eggert then iterated over the implementation of a read function, trying to balance these aspects in the best way possible, ending up with the UNIX implementation of read, which he described as "perfect". He ended the lecture by introducing different mechanisms by which modularity can be achieved: function calls, client-server interaction, and virtualization.
References:
Dam, Tran, Amir Vajid, Richard Yu, and Eric Zheng. "Lecture 3: Modularity
and Virtualization." CS 111 Scribe Notes. N.p., 30 Sept. 2010. Web. 18
Jan. 2016. <http://www.cs.ucla.edu/classes/fall10/cs111/scribe/3a/>.
Saltzer, J. H., and Frans Kaashoek. Principles of Computer System Design:
An Introduction. Burlington, MA: Morgan Kaufmann, 2009. Print.