Lecture 8: Scheduling and Synchronization
James Kang, Isaac Kim, Matthew Ku, Vincent Jin
Metrics
How can we know that our scheduler is working well?
- People will inevitably complain about our product so we need metrics to see how well our scheduler is working.
- The idea of metrics has already long been in existence.
Consider the Ford company in circa 1920 and imagine that an order for 500 Model T's is placed from Chicago. Here is an example timeline of how the order would be carried out:
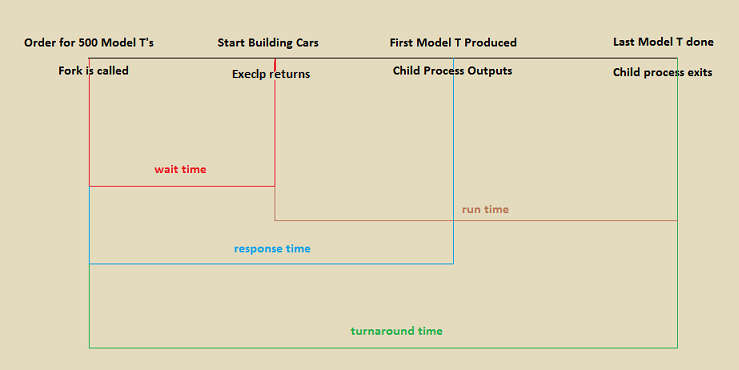
The steps to complete the order of 500 Model T's act as parallels to events within a program.
There are some situations where the machinery needs to alter something in order to meet a desired goal. For example, if another order came in for Model A cars, the machinery would take time to set up production for Model A’s. This time taken to change machinery is called the context switch time. During this time, no cars are being made.
The gaps in time (wait time, response time, turnaround time, etc.) are what are used in metrics. Whichever of these gaps is most important depends on your application. For example, video games will generally value response time while managing a payroll values turnaround time.
Some higher level properties that can also be used as metrics are:
- Throughput: The number of “useful” instructions per second. (Cars created/month)
- Utilization: To what extent is the CPU always doing something. (Measured from 0 to 1)
- Fairness: When there are multiple processes looking for CPU time, how likely is it that a process starve (need a resource but wait forever).
- Latency: The turnaround time.
Throughput and utilization are heavily related; increasing one usually increases the other. On the other hand, throughput competes with fairness and latency; generally, increasing throughput hurts fairness and increases latency.
Scheduling Policies
Here is an example problem:

We will be looking at utilization and average wait time for different types of scheduling policies. Utilization is calculated as the total time it takes to complete all processes, and wait time is the difference between the time of execution and the time of arrival. The following sequences display the processes being run at intervals of one second. A ^ indicates the time a context switch takes.
Let’s begin with a simple policy: First Come, First Served (FCFS).
FCFS
AAAAA^BB^CCCCCCCCC^DDDD
Utilization: 20/(20 + 3^)
Average wait time: (0 + (4+^) + (5+2^) + (13+3^)) / 4 = (11+3^)/2 = 5.5 + 1.5^ seconds
Is there a way for us to decrease the average wait time without affecting utilization? In order to do so, we try a different policy: Shortest Job First (SJF). Here we assume the job length is known. This assumption is reasonable in well controlled environments, such as those where a single process has been run numerous times.
SJF
AAAAA^BB^DDDD^CCCCCCCCC
Utilization: 20/(20 + 3^)
Average wait time: (0 + (4+^) + (4+2^) + (9+3^)) / 4 = (17+6^)/4 = 4.25 + 1.5^ seconds
SJF results in a shorter average wait time with the same amount of utilization as FCFS, but is not as fair as FCFS. An issue with SJF is that a long job may wait “forever,” even if the amount of work at any given time is bounded. This occurs when shorter jobs keep arriving before the long job can finish. In order to solve this problem, we use preemption. A preemptive scheduling policy is one that gives each process a set amount of time to use the CPU, called a scheduling quantum, before preempting/interrupting the process and giving CPU time to the next process in queue. The first use of preemption we will examine is a combination of preemption and FCFS.
CFS + Preemption (Round Robin)
A^B^C^D^A^B^C^D^A^C^D^A^C^D^A^CCCCC
Utilization: 20/(20+15^)
Average wait time: (0 + ^ + 2^ + 3^) / 4 = 3^/2 = 1.5^ seconds
When comparing the utilization and average wait time of the FCFS policy with and without preemption, we see that preemptive scheduling policies tend to have lower rates of utilization because of the greater number of context switches. The upside is that the policy is more fair and has a lower average wait time. However, if processes In order to prevent starvation, new arrivals of processes should be put at the end of the queue, not at the beginning. Our above example doesn’t do this, so let’s try it!
This is how a preemptive scheduler that places arrivals at the end of the queue would execute the same set of processes:
A^A^B^A^C^B^A^D^C^A^D^C^D^C^D^CCCCC
Utilization: 20/(20+15^)
Average wait time: (0 + (1 + 2^) + (2 +4^) + (4 + 7^)) / 4 = (7 + 13^) / 4 = 1.75 + 3.25^ seconds
While the average wait time is longer than if we had placed new arrivals at the beginning of the queue, this method is more fair.
SJF + Preemption
SJF will function very similarly with the addition of preemption. Applying preemption to SJF does not change much since the next process in the queue will be the shortest job, the process that is already running.
Synchronization
Synchronization is the coordination of actions in a shared address space.
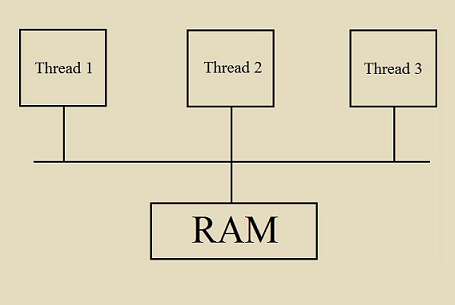
In the diagram above, threads load to and store from RAM. This is a recipe for races and is dangerous by default!
The simplest way to solve this problem is to run a single threaded application. It may be more worth it to shut off your second core than to go through synchronization; however, this becomes less practical with a larger amount of cores.
The goals of synchronization are:
- To maintain data consistency (RAM will be consistent across the threads T1, T2, and T3)
- Do so efficiently (One solution is to use single threading)
- Do so clearly, simply. and flexibly (Similar to the features of orthogonality)
There are three main ways to achieve synchronization:
- Sequence coordination: “X must occur before Y”
- Isolation: “X and Y have no variables in common” (X and Y cannot share info)
- Atomicity: "X cannot interrupt Y. Y is either done or has not started when X is called."
The most complex of these three ways is use of atomicity. More specifically, atomicity is a property of a multistep action such that there is no evidence that it is composite above the layer that implements it.
These are some properties of atomic processes:
- Observability: Even if shared variables and race conditions result in wrong information, it does not matter if the user cannot see them and is not affected by it at the end.
- Serializability: Even if multithreaded and multiprocess applications result in operations being completed out of order, it does not matter if the end result is not different from the application completed in order.
Let’s say we have a bank account with $100 dollars. Both Eggert and his brother can withdraw and deposit from this account.
//Naive implementations of deposit and withdraw:
long long balance;
void deposit(long long amt){ void withdraw(long long amt){
balance += amt; balance -=amt;
} }
//Neither check for errors, so let’s change that.
bool deposit(long long amt){ bool withdraw(long long amt){
if(0 < amt && amt <= LLONG_MAX-balance){ if(0 < amt && amt < balance){
balance += amt; balance -=amt;
return true; return true;
} }
else return false; else return false;
} }
These functions now check for errors, but there are still race conditions which could cause fatal errors. Suppose Eggert and his brother have LLONG_MAX - 5 dollars in the bank and both decide to deposit 3 dollars at the same time at different ATMs. If both instances of deposit load the balance value before the other has incremented the balance, the if statement will return true for both, adding a net total of six to balance and causing long long overflow. This happens because the deposit function is not atomic; the standard way of achieving atomicity is by creating critical sections.
Critical Sections
Critical sections are portions of code in which at most one program counter should be executing on behalf of an object. While making critical sections very large will make the program safer, they will hurt performance by reducing parallelism if they are too large. On the other hand, critical sections that are too small will not be able to fix all race conditions. Balancing these two extremes is the Goldilocks Principle.
How to find critical sections:
- Look for shared writes.
- Expand the critical section to include dependent reads and intervening computation.
- Repeat step 2 until the sections don’t get any larger.
If the shared variables are only being read, there is no need to use the Goldilocks Principle.