CS111, Winter 2016
Lecture by: Professor Eggert
Scribe Notes by: Megan Williams
1. Critical Sections and Deadlock
When implementing critical sections we have to follow the Goldilocks principal to make sure our critical sections are neither too big nor too small. We have to be especially careful when implementing critical sections with multiple locks to avoid deadlock. Recall the banking problem from Lecture 8. We are able to add or remove funds from a bank account. We now want to have a new function transfer() that allows us to transfer funds from one account to another. We have already learned that when adding or removing funds from an account we need locks to protect the bank balance or else we will introduce race conditions. Thus we need to implement a critical section for transfer(). Lets try implementing transfer() with two critical sections. We will have two locks: one for each bank account. Transfer is implemented as:
transfer(from_amount, to_account) {
lock(from);
REMOVE funds from from_amount
unlock(from);
//<—— Potential error here!
lock(to);
ADD funds to to_account
unlock(to);
}
Even with the locks around these two sections, there is still potential errors with this implementation. If we were
to look at the account balances above at the instance in the code when we have unlocked from but have not yet locked to, it will appear as though the funds we are transferring have simply vanished. This is not correct. In order for our code to be correct, any time we are not in a critical section we need to be able to look into the account balances and either have all the money transferred or no money transferred. Thus, having two critical sections is not right. We need to increase the size of the critical section to include everything. Our new function now becomes:
transfer(from_amount, to_account) {
lock(from);
lock(to);
REMOVE funds from from_amount
ADD funds to to_account
unlock(from);
unlock(to);
}
Now we have solved our atomicity problem. However, we have another problem: we might get deadlock! We have to be extremely careful with how our processes can obtain locks. If one process has the from lock and another process has the to lock, and both are trying to grab the other lock, then they will be stuck waiting for the other lock indefinitely. Neither of these processes will be able to proceed. This is known as deadlock.
What if we want to run an audit at the bank? We want to have some function audit(all objects) that will lock all objects at the same time and run the audit. However, running the audit takes time. For this period of time all objects will be locked and people will not be able to access their money. This is generally bad.
We can use the following solutions:
1. Run the audit at 3 A.M. when fewer people are trying to access their money.
2. (better solution) Have the file system take a snapshot. Temporarily lock all of the objects and quickly take a snapshot. Then release the locks and run the audit on the snapshot. This way we do not have to lock all the objects for very long but can still get an accurate audit.
2. Practicality/ Mechanisms of Critical Sections
How do you enforce critical sections? We will examine enforcing critical sections for a uniprocessor and multiprocessor
1. Uniprocessor
We only have one process running at a time. This makes implementing critical sections easier, but there are still issues that can occur. For example, interrupts can cause cause problems. Even doing something as simple as balance += amt can be interrupted.
This addition is actually implemented as multiple machine code instructions that could be interrupted in the middle of the addition. To enforce critical sections we MUST DISABLE INTERRUPTS. Signals can mess with our process, for example clock interrupts can cause us to lose control of the CPU at any time and cause the critical section to be not protected.
There are a few good solutions to deal with interrupts in uniprocessors:
A. One solution to this is to use cooperative multitasking. If we recall from previous lectures, cooperative multitasking relies on processes to make systems calls to switch between processes, as opposed to preemptive multitasking which forces a context switch between processes based on a timer. However, it is important to keep in mind that cooperative multitasking can cause starvation because it may allow one process to hog the CPU.
B. Another solution is to temporarily disable interrupts with calls to pthread_sigmask()
2. Multiprocessor
In addition to dealing with the issues above, we also have to deal with processes accessing the same objects when dealing with multiprocessors. For example, lets assume we have multiple processes accessing a pipe. Our pipe is implemented as follows:
struct pipe {
char buf[1024];
unsigned r,w;
};
A visual representation of a pipe is below. The red section of the pipe corresponds to data that has been written and not yet been read. r and w increment each time a read or write is done. The pipe also wraps around.
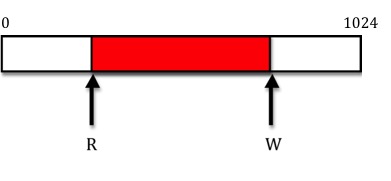
In our implementation r and w are similar to pointers and represent the current read and write positions in the pipe. When we write we increase w and when we read we increase r. When r = w = 0, the pipe is empty. If w is 1024 larger than r, the pipe is full. We allow w and r to grow without bound, and each time we access the pipe we use w mod 1024 and r mod 1024. Using modulus guarantees we are always in bounds and also will automatically implement the wrap around feature of pipes.
We will now write functions to read from the pipe and write from the pipe. write_pipe() writes a character c to a pipe p. We implement this function to return a bool that indicates if the write happened. read_pipe() reads a character in the pipe and returns an int corresponding to the character.
bool write_pipe(struct pipe *p, char c) {
if (p->w - p->r = 1024) //check if buffer is full
return false;p->buf[p->w++%1024] = c //writes to buf at position w mod1024
//and then increments w
return true;
}
int read_pipe(struct pipe *p) {
if (p->w == p->r) //check if pipe is empty
return CHARMIN-1; //By subtracting 1 from CHARMIN
//we ensure this cannot correspond to a value returned from a successful read
return p->buf[p->r++%1024]; //read from location r mod 1024 and increment r
}
These implementations of write_pipe() and read_pipe() are buggy on a multiprocessor. What if we have one process P1 trying to read to the pipe while another process P2 reads from it? We might see that P1 evaluates the if-statement and sees the pipe is full as P1 is reading from the pipe. P1 evaluates the if-statement before P2 returns. Then P2 finishes and the pipe is no longer full, but P1 is not aware of this and returns false indicating the pipe is full even though the pipe isn’t full. This is a race condition.
We can fix this by adding a lock member to the pipe structure:
struct pipe {
char buf[1024];
unsigned r,w;
lock_t l;
};
We can use this lock to ensure that only one process can access the pipe at a time. In the code below, the function lock() guarantees that only one process will be able to grab the lock and enter the critical section at a given time. Our new write function becomes:
bool writepipe(struct pipe *p, char c) {
lock(&p->l);
if (p->w - p->r == 1024) //check if buffer is full
return false;
p->buf[p->w++%1024] = c; //writes to buf at position w mod 1024
//and then increments w
unlock(&p->l);
return true;
}
This code has one huge bug. What if we lock the pipe, then evaluate the if-statement and find that the pipe is full? We then return, but we never unlocked the pipe! No other process will be able to access the pipe after the pipe. We need to make sure we always unlock the pipe before we return. Our new correct read and write functions are implemented below:
bool writepipe(struct pipe *p, char c) {
lock(&p->l);
if (p->w - p->r == 1024) { //check if buffer is full
unlock(&p->l);
return false;
}
p->buf[p->w++%1024] = c; //writes to buf at position w mod 1024
//and then increments w
unlock(&p->l);
return true;
}
int read_pipe(struct pipe *p) {
lock(&p->l);
int c = p->r==p->w? p->buf[p->r++%1024]:CHARMIN-1;
unlock(&p->l);
return c ;
}
3. Implementing Lock and Unlock Functions
Now we know how to correctly use lock()and unlock()functions to enforce critical sections. But how do we implement the lock()and unlock()functions? There are two main ways in which we can implement these functions:
A) Implement them as system calls. This is easy to do, but it requires trapping and executing in kernel mode. This is time consuming, and if we are making lots of calls to lock() and unlock() then the function calls implementation will not be fast enough for most applications.
B) Implement them as plain machine instructions. This better solution is to use hardware access and machine instructions.
Software implementation of locking:
Let’s try doing a software implementation of locking. We will use create a lock represented as a char variable:
typedef char lock_t;
If the lock has a value of 1 then it is locked and if it equals 0 then it is unlocked.
We will have lock() and unlock() functions defined as follows:
void lock(lock_t *l){
while (*l) //precondition: don’t have lock
continue; *l = 1; //post condition: have lock
}
void unlock(lock_t *l) {
*l = 0;
}
This implementation has a race condition! What if two processes evaluate the loop in lock() at the same time. Both processes see that the lock is unlocked and exit the while loop before the other process can grab the lock. They then both grab the lock at the same time. This implementation does not work.
Another issue with software implementations is caching. With caching, when a process does a store into a variable, we do the store into a cache instead of in RAM. Later, if that process wants to access that variable then then RAM will be updated to match the cache. But what if another process tries to access this variable? Let’s say we have a process P1 do a store into a variable called lock:
*lock = 1;
This writes a value of 1 into a cache before it gets stored in RAM. What if another process P2 checks the lock by looking at the RAM before 1 stored into the RAM? P2 will see an old value for the lock, possibly a value of 0 indicating that the lock is unlocked, when in fact it is locked. This P2 to grab the lock when P1 already has it. Thus two processes obtain the lock, and this is very bad. A solution to this is to turn off caching. However, this makes the program extremely slow.
Hardware implementation of locking:
A better way to implement locking is to use a hardware implementation.
In the hardware we have the following atomic instructions:
1. lock incl x
This increments x by 1. This is reliable and does work atomically. If two CPUs issue this instruction on a variable at the same, then x will be incremented by 2, which is not guaranteed if we do an increment instruction that is not atomic.
2. xchngl
This can atomically swap two values. It allows us to implement locks. xchgl works like the following code, except for it guarantees that everything is done atomically:
int xchgl (int *p, int val) {
int old = *p;
*p = val;
return old;
}
We can thus implement lock() using xchgl with the following code:
void lock(int *l) {
while (xchgl(l, 1))
continue;
}
xchgl will return the old value of the lock. As long as the old value of the lock is 1, the lock is not free. We must wait until the lock value becomes 0 to exit the loop. Then we set the lock to 1 to indicate that we have locked it, and we can finally return from lock().
What if we want to do an arbitrary computation on x atomically? For example we want to compute
x = f(x);
where f(x) is some function
We can do
lock(&l);
x = f(x);
unlock(&l);
But we can also implement this without locks. Let’s try doing the computation using xchngl:
int old = x;
int new = f(x);
while (xchgl(&x, new) != old)
continue;
This seems like it might work, but in fact there is a race condition. What if the value of x was changed sometime after we had stored x in old, but before we called xchgl? Then the return value of xchgl will never be old and the program will enter an infinite loop.
We can implement an atomic arbitrary computation by using an atomic instruction called compare and swap (CAS). The compare and swap instruction works like the following code, in which cas() executes everything atomically:
bool cas(int *p, int old, int new) {
if (*p == old) {
*p = new;
return true;
}
else
return false;
}
do {
int old = x;
while (cas(&x, old, f(x));
In this code we keep doing the computation on x until we get the correct value. If someone changes x in the middle of the computation, cas() will return false and we will repeat the loop again until it works.
How big should the lock be?
What size should we make the lock variable?
Not too large: what if we have a lock size of __int128. This is a 128-bit quantity. One load and store is 64 bytes on an x86-64. Thus, to store a value of this size takes 2 instructions. What if we are interrupted in the middle of the instructions? Doing a store into this variable is not atomic and introduces race conditions.
Also not too small: what if we have a 1-bit lock? To access this value we have to load the corresponding byte and do a shift to get the correct bit. This also requires multiple instructions and introduces race conditions.
A good size for a lock is an int. On an x86-64 this is a 64-bit quantity.
4. Types of Locking
A. Coarse Grain
What if we have have a big dictionary with lots of words? If we want to access one word we lock the entire dictionary. This is not the best implementation. We might be trying to do multiple accesses that will not interfere with each other, yet we lock the entire dictionary each time. We can change our lock implementation to have a lock for each word, thus multiple words can be accessed by different processes at once.
Similarly, what if we have multiple processes accessing multiple pipes?
We can implement this with just one global lock for all pipes.
lock_t l global_lock;
We thus access a pipe with
lock(&global);
DO WORK
unlock(&global);
With this implementation, if we have N threads trying to access pipes, then we have 1 pipe working while N-1 threads wait. However, not all of the N-1 threads that are waiting are necessarily waiting on the pipe that the one running process is working on. These processes are waiting when they don’t need to be waiting.
This is an example of coarse grain locking. Coarse grain locking is characterized by having only 1 lock protecting access to all shared data.
Advantages of coarse grain locking: Easy to implement, simple
Disadvantages: Causes a performance bottleneck. If a bunch of threads try to access pipes at the same time, they all run one by one and this takes a long time. Some processes might be waiting unnecessarily.
B. Fine Grain Locking:
We have one lock per pipe. Fine grain locking is where we subdivide all the objects of interest and give each its own lock. This will reduce our bottleneck issue. If we have a lot of processes accessing pipes, all of the processes can run in parallel as long as they are accessing different pipes. However, there might still be a performance bottleneck if they are all trying to access the same pipe.
Fine grain locking would be implemented with a pipe structure where each pipe has its own lock like below:
struct pipe {
data
lock_t l;
};
C. Really Fine Grain Locks:
We can even have a finer grain than 1 lock per pipe!
What if we had two locks for a pipe, a read lock and a write lock:
struct pipe {
char buf[1024];
unsigned r,w;
lock_t rl, wl;
};
Here we have a read lock rl and a write lock wl. Recall the read and write functions for pipes we implemented earlier. Below write_pipe() is implemented with our new locking system. read_pipe() is implemented in a similar way.
bool write_pipe(struct pipe *p, char c) {
lock(&p->wl);
if (p->w - p->r == 1024) { //ISSUE HERE
unlock(&p->l);
return false;
}
p->buf[p->w++%1024] = c;
unlock(&p->wl);
return true;
}
This implementation is flawed. This will allow us to do reads and writes at the same time, and this is bad!
In our implementation, write only modifies w and read only modifies r. Because of our locks, only one process can modify r and and only one process can modify w at a given time. Therefore, it seems like there will not be a race condition here. However, we can see in the code above that write_pipe() looks at both w and r. The fact that write_pipe() looks at r when read_pipe() might be modifying r causes a race condition.
5. Scheduling
When a process tries to get a lock and fails, it waits for the lock to become available. In the meantime, we can schedule another process. Our code looks like:
while (c = readpipe(p) == CHARMIN-1)
yield();
do_work();
How do we decide which process to schedule next in the call to yield()?
Lets say our scheduler is juggling n processes: 2 writers, j+1 readers, and some other processes that don’t deal with pipes.
Our processes are represented in the picture below:
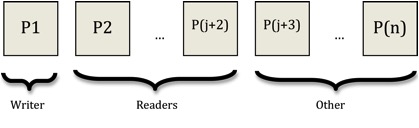
Currently the pipe is empty, so all of the readers cannot do any useful work. We give control to P3, a reader, and it immediately calls yield() again because the pipe is still empty. We then do a context switch and run P4. We then proceed to do a context switch to each reader, while accomplishing absolutely no work. This creates a lot of overhead. Our overhead is proportional to the number of threads trying to use the pipe but cannot.
There is an easy solution to reduce the overhead:
Put the readers to sleep until the pipe is no longer empty. We put a process to sleep by setting a bit in its process table that indicates they are waiting for some condition to be true. In this example, the condition we are waiting for to be true is that the pipe is no longer empty. When we finally write to the pipe we can wake up the sleeping readers. This method of putting waiting processes to sleep is called blocking. We will learn more about implementing blocking next lecture.