Fault-Tolerant Cluster Testbed Project
Clusters of commercial off-the-shelf
(COTS) processors inteconnected by high-speed SANs or LANs are
increasingly
used for cost-effective high-performance parallel computing. Typically,
in such systems, every node runs a local copy of an off-the-shelf
operating
system that is not designed to manage a distributed cluster. Cluster
management
middleware (CMM) runs between the applications and the operating system
and provides resource allocation, scheduling, coordination of fault
tolerance
actions, and coordination of the interaction between the cluster and
external
devices. The cluster management middleware is critical to overall
system
reliability since if the cluster management middleware fails, the
system
is lost.
The Fault-Tolerant Cluster
Testbed (FTCT) project is motivated by JPL/NASA's Remote Exploration
and
Experimentation (REE) project. The goal of REE is to use COTS hardware
and software to deploy scalable supercomputing technology in space. In
this environment, fault tolerance is more critical than for most
earth-bound
systems due to the much higher fault rate of COTS hardware in space.
The focus of the FTCT project
is on developing and evaluating algorithms and implementations of fault
tolerant cluster managers. Some of the critical factors driving this
work
are the need to deal with realistic fault models, the need to minimize
the performance and power overheads of the fault tolerant mechanisms,
and
the need to support soft real-time requirements. In addition, the
cluster
management middleware must provide the mechanisms needed to support, as
a separate layer, application-level fault tolerance for critical
applications.
System Structure
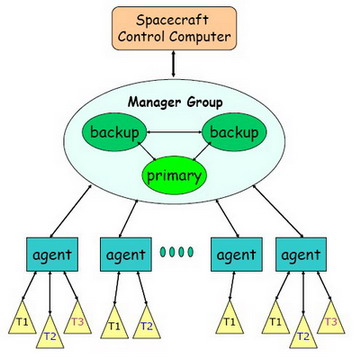 The system consists
of a group of actively replicated
managers, an agent process on each node, and a library for user
applications.
The manager group performs cluster-level decision making, is
responsible
for resource allocation, scheduling, and coordination of system level
monitoring
and fault recovery procedures. An agent process on each node sends node
status information to the manager group, performs commands at the node
on behalf of the manager group, and provides an interface between
application
processes and the cluster management middleware (CMM).
The system consists
of a group of actively replicated
managers, an agent process on each node, and a library for user
applications.
The manager group performs cluster-level decision making, is
responsible
for resource allocation, scheduling, and coordination of system level
monitoring
and fault recovery procedures. An agent process on each node sends node
status information to the manager group, performs commands at the node
on behalf of the manager group, and provides an interface between
application
processes and the cluster management middleware (CMM).
Messages exchanged among managers, and between managers
and agents are authenticated (signed) to ensure that faulty
nodes
cannot forge messages from other nodes, even if the message is
forwarded
by the faulty node. Manager replicas transmit commands to the
agents.
Outputs produced by the manager replicas are voted on by agents. Agents
act only when receiving identical authenticated commands from at least
two manager replicas. Hence, a manager replica that stops or generates
incorrect commands cannot corrupt the system. If a manager replica
fails,
a new manager replica is restarted using the states of the remaining
two
manager replicas.
Key Features
Active Replication for the Fault-Tolerant Central Manager
Detection of arbitrary (Byzantine)
failures requires
multiple active replicas and continuous comparison of the results. In
order
to avoid a lengthy interruption for recovery when a discrepancy is
detected,
more than two replicas are needed. With the classic TMR scheme that is
currently implemented in FTCT, any single failure can be tolerated
since
there will always be two manager replicas that agree on each result.
With active replication, all replicas
execute and
generate outputs independently. In the absence of failures, they must
produce
the same outputs in the same order. This requires all inputs to be
delivered
to the replicas in the same order and processing to be deterministic.
Hence,
a reliable group communication protocol must be used to transmit
messages
to the manager replicas.
FTCT uses an atomic multicast protocol similar
to the group communication protocol used in Amoeba, which is a
fixed-sequencer-based
protocol, with the primary manager as the sequencer.
Some of the management functionalities,
such as gang scheduling, are time triggered. Scheduling these
time based events and the external message events on the manager
replicas introduces indeterminism that may cause inconsistency among
the replicas. In order to avoid that, we defined group time
events and developed a deterministic scheduling algorithm to
process them consistently and reliably on all manager replicas.
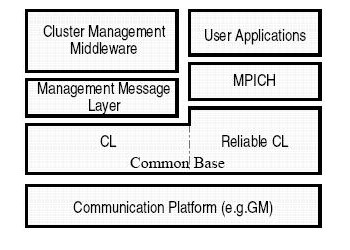
Portable Communication Layer
The interprocessor communication for
the FTCT
system is implemented on top of a light weight communication
infrastructure that provides optimized communication interface for both
the management middleware and parallel applications. It is designed for
portability and for efficient operation on top of different network
platforms, such as Myrinet/GM, UDP and TDP, with very low overhead
(avoids extra copying for message transmission).
Fault Detection
FTCT employs three key mechanisms for
fault detection:
inconsistent outputs from the manager replicas, missing heartbeats, and
identification of corrupt, forged, or missing messages. Inconsistent
outputs
from the manager replicas are detected by the voting mechanism.
Heartbeat
mechanism is used to detect crash/stop failures. Members of the manager
group send periodic heartbeats to each other and agents send periodic
heartbeats
to the manager group. Missing heartbeats indicate a likely faults.
Coding is used to detect message corruption. In addition,
as mentioned earlier, all the messages transmitted by members of the
CMM
are authenticated. The use of authenticated messages is critical to
detecting
any attempt by the primary manager replica to modify messages to the
manager
group. All messages to the manager group are acknowledged independently
by the replicas. Hence, if the primary manager replica modifies,
discards
or reorders messages before sending them to the backup manager
replicas,
the agents will detect the problem as inconsistent or missing
acknowledgements
from members of the manager group.
Manager Self-Diagnosis and
Reconfiguration
With active triplication, if one
replica is faulty
the remaining working replicas still form a majority and the group can
continue to function correctly. However, the faulty replica must still
be identified and repaired or replaced. Otherwise, a future fault in
some
other component of the system (such as another replica) may combine
with
the faulty replica and drive the system into a state from which it
cannot
recover.
Faulty manager replicas can be detected
by comparing
all the replica outputs. With the FTCT CMM, this is done by the agents.
However, agents may be faulty and thus cannot be trusted to correctly
identify
faulty manager replicas. Instead, an agent that detects an
inconsistency
reports it by sending point-to-point messages to all the members of the
group. After that, the manager self-diagnosis procedure is initiated.
During the diagnosis procedure, the manager replicas reach agreement on
a diagnosis point and compare their state (checksum of their state) to
identify the faulty replica. The manager group then goes through a
reconfiguration to replace the faulty replica with a new one. The
diagnosis and reconfiguration are non blocking: the management
functionalities are still available while the diagnosis and
reconfiguration are on going. The self diagnosis and reconfiguration
allows us to build a long lived management system.
An Out-of-Band Signaling Mechanism
for Applications
Application-level fault tolerance
schemes
can be facilitated by a mechanism that allows the application processes
to exchange messages out-of-band from the normal application MPI
interprocess
communication. For example, an acceptance test in an application
process
may fail and the desired roll-forward recovery mechanism may require
informing
all the processes of the task, which are running on other nodes. At
this
point, the processes on the other node may not be receiving messages
(e.g.,
a process may be stuck in an infinite loop). The out-of-band
communication
mechanism implemented in FTCT allows a process of a task to cause an
asynchronous
message to be delivered to all other members of the task.
In order to implement the out-of-band
signaling feature,
the FTCT CMM provides application processes with the ability to
``signal''
the local agent. The agent propagates the asynchronous message by
sending
it to the manager group, which forwards it to the agents on all the
nodes
running processes of the same parallel task. Each agent at such a nodes
uses UNIX signals to interrupt the application process and then deliver
the message.
PUBLICATIONS
- Ming Li, Daniel Goldberg, Wenchao Tao, and Yuval Tamir, "Fault-Tolerant Cluster Management for
Reliable
High-Performance Computing," 13th International Conference on
Parallel and Distributed Computing and Systems,
Anaheim, CA, pp. 480-485 (August 2001).
(PDF PS)
- Daniel Goldberg, Ming Li, Wenchao Tao, and Yuval Tamir, "The Design and Implementation of a
Fault-Tolerant
Cluster Manager," Computer Science Department Technical
Report CSD-010040, University of California,
Los Angeles, CA (October 2001).
(PDF, PS)
- Ming Li, Wenchao Tao, Daniel Goldberg, Israel Hsu, Yuval Tamir,
"Design and Validation of Portable Communication Infrastructure
for Fault-Tolerant Cluster Middleware,"
IEEE International Conference on Cluster Computing,
Chicago, IL, pp. 266-274 (September 2002).
(PDF)
- Ming Li and Yuval Tamir, "Practical Byzantine Fault Tolerance
Using
Fewer than 3f+1 Active Replicas,"
17th International Conference on Parallel and Distributed
Computing Systems,
San Francisco, CA (September 2004).
(PDF)