CompSci 142 / CSE 142 Winter 2018 | News
| Course Reference | Schedule | Project Guide
This webpage was adapted from Alex
Thornton’s offering of CS 141
CompSci 142 / CSE 142 Winter 2018
Project #2
Due date and time: 11:59pm, Sunday, January 28, 2018.
Late homework will not be
accepted.
Introduction
Now that we have completed writing a Scanner that tokenizes input Crux
source files, we can proceed with implementing the next part of the compiler: a
Parser. Because our crux.Parser
will ultimately do more than task, we split the implementation into smaller
pieces.
The grammar given in the Crux Specification describes the appearance of sentences within the Crux language. Because Crux is a computer language, some (but not all) of these sentences can be translated into valid Crux programs. In this project, we shall implement a recursive descent parser for the Crux language. The parser will act as a recognizer, allowing us to reject sentences which have syntax errors (invalid or misplaced tokens), because they could not possibly be Crux source code.
What's Recursive Descent?
The Crux language language has been purposefully designed as LL(1) for
simplicity of parsing. It can be parsed from Left to right, constructing
a Leftmost derivation with only 1 token of lookahead. Remarkably,
this feature allows us to directly map each rule in Crux's left-factored
grammer with a clause of a recursive procedure. During execution of the parse,
the Parser will start at the top of the parse tree (rule program) and recursively call itself (program calls declaration_list)
descending down through the tree until bottoming out at a terminal (such as those
in rule literal).
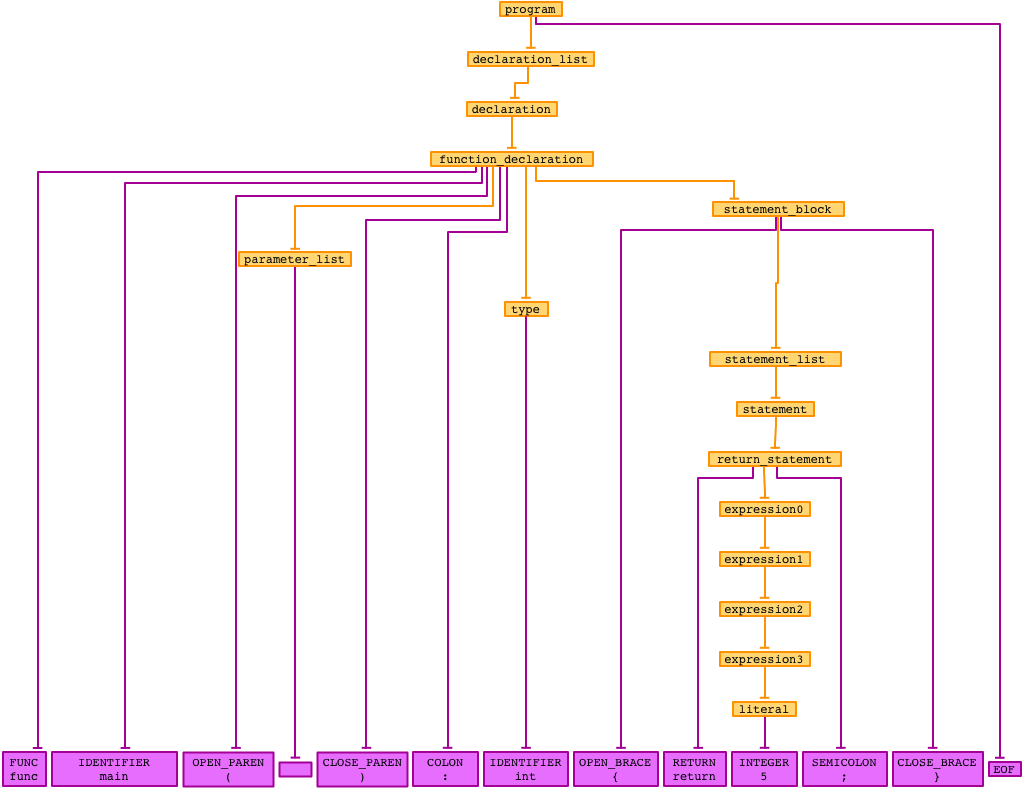
Consider an example sentence in the Crux language:
func main() : int {return 5;}
The
corresponding parse tree is shown to the right (click on it for larger
version). All of the grammar production rules involved in describing this
sentence are present in the tree (shown to the right, click on it for a larger
version). The crux.Parser calls a method
for each one of the parser rules (orange boxes) in the tree. For example, the function_declaration method calls the parameter_list method after it has read the FUNC, IDENTIFIER(main),
and OPEN_PAREN tokens.
Notice
that some of the productions consume none of the tokens. The main function in our example has no arguments, so
the parameter_list production
consumes the empty string, depicted as an empty token-styled box. Therefore the
parameter_list method must
be able to quit and return without accidentally eating the following CLOSE_PAREN token.
Left-Factoring Removes Infinite Recursion
Implementing each rule as a mutually recursive method in the parser can lead to accidental infinite loops. Consider the following (very tiny) grammar, and pseudo-code implementation:
letter := letter "a" | "a" . |
void letter() { switch(currentToken) { case /*first choice*/: letter(); eatToken("IDENTIFIER(a)"); case /*second choice*/: eatToken("IDENTIFIER(a)"); }} |
What
happens if the letter
method always tries the first choice?
First
we call letter, which again calls letter without consuming any tokens of input. The
second call in turn calls letter
without consuming any tokens of input. The third call again calls letter without consuming any input. And so on,
until the Java runtime environment says we made too many calls to letter by throwing a java.lang.StackOverflowError.
This
is a contrived example, and shows the problem rather directly. In realistic
grammars, we may have production rules that double-back on themselves in a
mutually recursive fashion. For example, it might be a longer chain: expression calls term
calls factor calls back to expression. We still have to remove the
left-recursion in a process known as left-factoring, as shown
in class.
FirstSets Allow Predictive Choice
Once
we have a grammar that allows us to compose a recursive descent parser without
worry of infinite loops, we notice that some of the productions have more than
one available expansion. For example, consider a hypothetical statement rule, and its pseudoccode
implementation:
statement := variable-declaration | statement-block . |
void letter() { switch(currentToken) { case ???: variable_declaration(); break; case ???: statement_block(); break; case default: error("couldn't make a choice"); }} |
What
if variable_declaration and statement_block both started with "var"? How will the parser be able to
decide, from looking just at the currentToken
which case it should execute?
We
can make sure that there is only one unique branch to execute by computing
what's called the FirstSet
of each non-terminal production rule. The above example happens to be
contrived, because when we look at the grammar rules for variable_declaration we see that it may start with
either a VAR or ARRAY token, while statement_block
always begins with a OPEN_BRACE.
FirstSet(variable_delaration)
shares no common tokens with FirstSet(statement_block),
so the parser is always able to choose uniquely between these two possible
paths, with no information other than the currentToken.
What do I need to implement?
The Crux Grammar section of the Crux Specification. Your program should be able to read input from the Scanner, parsing the stream of tokens one at a time, and printing the grammar rules executed. For simplification purposes, we will not implement error recovery. It is expected that your Parser reports the first syntax error (if any) it encounters and quits.
For
convenience, you may get a start on this lab by using a pre-made Lab2_Parser.zip project, which contains a crux.Compiler skeleton for executing a crux.Parser. As before, you are both allowed and
encouraged to make your program easier to read and maintain by implementing
helper functions with good names.
What's Changed Since the Last Lab?
crux.Compiler.mainhas been changed to create a Parser, call it'sparsemethod, report the parse tree and any syntax errors.
Designing the Parser
Because the parser has already several tasks to accomplish, it makes sense to first sketch some components of the design.
Reading Input
The
Parser gets it's input from a stream of tokens returned from the Scanner. It's
not necessary (nor allowed) to look more than one token ahead. This means that
we need only one field currentToken
to store the current position in the token stream.
Sometimes,
like when stepping over an OPEN_PAREN
this token needs to be consumed. The parser need only report a syntax error if
the current token happens to be different than the one expected (OPEN_PAREN At other times, like when detecting
whether the optional ELSE
branch is present, the token is only consumed if it matches the one expected.
Because the else clause is optional, the parser would not report a syntax error
if the current token happened to be different. Rather, it would consider the if_statement finished, and pick up where it left
off (likely statement_list). Already,
we can see that, depending on the grammar, sometimes the current token should
be eaten and the token stream advanced and sometimes not; sometimes an error
should be reported and sometimes not.
To support a matrix of possibilities I suggest the following helper functions:
|
Name |
Advance stream? |
Report Error? |
Purpose? |
|
|
No |
No |
Examine the current token. |
|
|
When token matches |
No |
Allow matching tokens to be consumed. |
|
|
When token matches |
When token doesn't match |
Report errors on unexpected tokens. |
Furthermore,
these questions will sometimes be asked not on individual crux.Token.Kinds, but on a collection of them. For
example, if the Parser has to decide whether there were more statements in a statement_list, it's convenient to call have on the statement's
FirstSet. Each of the above
three functions should be overloaded to receive either a Token.Kind or a NonTerminal.
Recording the Parse Tree
The recursive descent parser has a method for each production rule in the grammar. When it parses a sentence, it naturally makes a sequence of methods calls that correspond to a pre-order traversal of the parse tree. All that is required in the project, is to record this sequence.
The
crux.Parser contains one
field and two methods for tracking the sequence of production rules:
StringBuffer parseTreeBuffer; A field for storing the sequence of production rules.
void enterRule(NonTerminal); Called whenever the parser enters a production rule.void exitRule(NonTerminal); Called whenever the parser exits a production rule.String parseTreeReport(); A method to retrieve the production rule sequence.
Reporting Syntax Errors
The
crux.Parser contains a
method specifically for reporting syntax errors: reportSyntaxError(Token
tok). This method produces an easy to read error report, which we
should expect to find useful when writing test Crux programs for the full
compiler. Despite the fact that (in this lab) only one error will be reported,
the parser has a StringBuffer
errorBuffer field that records errors for later query.
Developing FirstSets
Each
of production rules has associated with it a Set<Token.Kind>
which describes the collection of tokens which may begin that clause in the
grammar. In contrast to terminals (Tokens produced by the Scanner), only the
non-terminals (production rules|parser methods) have FirstSets. Because the
grammar is already established, these sets never change, so a enum NonTerminal is a perfect fit.
Ordinarily,
it would be cumbersome to compute, for every rule in the grammar, a FirstSet.
However, Java has an "anonymous class construction" idiom (with
regrettably verbose syntax). This feature allows computational construction (at
Java compile time) of the FirstSets. A contrived snippet (not from the
Crux grammar) is given below, to show the convenience and use of the Set.add and Set.addAll
methods:
factor := "not" expression | designator . |
FACTOR(new HashSet private static final long serialVersionUID = 1L; { add(Token.Kind.NOT); addAll(DESIGNATOR.firstSet); }}) |
In
this example, we must be sure that DESIGNATOR
is listed before FACTOR.
Otherwise, the Java compiler will complain that DESIGNATOR doesn't exist when
it tries to run the addAll
line in FACTOR.
Testing
Test cases are available in this tests.zip file. The provided tests are not meant to be exhaustive. You are strongly encouraged to construct your own. (If chrome gives you a warning that "tests.zip is not commonly downloaded and could be dangerous" it means that Google hasn't performed an automated a virus scan. This warning can be safely ignored, as the tests.zip file contains only text files.)
Restrictions
- The
crux.Parsermust read each token, one at a time, only as needed, using thenext()method ofcrux.Scanner - Naming Convention: NonTerminals are all uppercase with an underscore "_" where the production rule has hyphen "-".
- Naming Convention: Parser methods are all lowercase with an underscore "_" where the production rule has hyphen "-".
Deliverables
A
zip file, named Crux.zip, containing the following files (in the crux package):
- crux.NonTerminal.java, which holds the FirstSets of all production rules in the grammar.
- crux.Parser.java, which performs grammar recognition of an input text.
- crux.Scanner.java, which performs incremental tokenization of an input text.
- crux.Compiler.java, which houses the main() function that begins your program.
- crux.Token.java, which represents a string of characters read in the input text.
Please
follow this
link for a discussion of how to submit your document. Remember that we do
not accept paper submissions of your assignments, nor do we accept them via
email under any circumstances.
·
Adapted from a similar document from CS 141 Winter 2013 by Alex
Thornton,