Machine
Speedup for Xeon, Opteron and Power5+ processors over the best single-threaded version
Performance improvement over maximal fusion, and over the best reference auto-parallelizing compiler
24 H/W threads
16 H/W threads
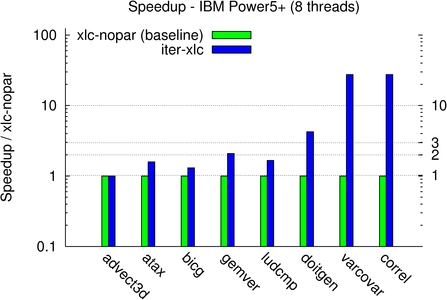
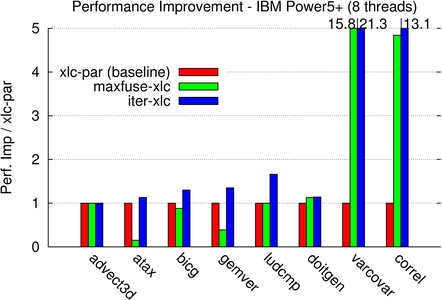
8 H/W threads
| [<< home] [news] [description] [documentation] [download] [installation] [performance results] [publications] [history] | On development, version 1.2 available |
PoCC is a flexible source-to-source iterative and model-driven compiler, embedding most of the state-of-the-art tools for polyhedral compilation. The main features are:
PoCC embeds powerful Free software for polyhedral compilation. This software is accessible from the main driver, and several IR conversion functions allows to communicate easily between passes of the compiler.
Communication: three groups are available for subscription
Please note that the two following documents are highly preliminary, and incomplete. The documentation will be improved soon. In the meantime, don't hesitate to contact the author for any question.
The stable mode of PoCC does not require any software beyond
a working GNU toolchain and Perl.
Several other modes are
available through the SVN version of PoCC (available on request). To
use those other modes such as base, devel
and irregular, some software is additionally required to
build the development version of PoCC:
PoCC features several modes to configure the compiler. The
default mode for the installer is stable. To change it and
use a development mode, change the value of
the POCC_VERSION variable at the beginning of
the install.sh file.
The installation of PoCC is packaged in an installer
script install.sh. PoCC is not aimed at being installed
in a specific location on the system. Instead, append
the pocc-1.1/bin directory to your PATH
variable to use PoCC from any location.
$> tar xzf pocc-1.2.tar.gz $> cd pocc-1.2 $> ./install.sh $> export PATH=$PATH:`pwd`/bin
For a test run of the compiler:
$> pocc gemver.c [PoCC] Compiling file: gemver.c [PoCC] INFO: pass-thru compilation, no optimization enabled [PoCC] Running Clan [PoCC] Running Candl [PoCC] Starting Codegen [PoCC] Running CLooG [CLooG] INFO: 3 dimensions (over 5) are scalar. [PAST] Converting CLAST to PoCC AST [PoCC] Using the PAST back-end [PoCC] Output file is gemver.pocc.c. [PoCC] All done.
To inspect the available options:
$> pocc --help PoCC, the Polyhedral Compiler Collection, version 1.2. Written by Louis-Noel Pouchet <pouchet@cs.ucla.edu> Major contributions by Cedric Bastoul, Uday Bondhugula, and Sven Verdoolaege. Available options for PoCC are: (S) -> stable option, should work as expected (E) -> experimental option, use at your own risk (B) -> broken option, will likely not work short long status description -h --help (S) Print this help -v --version (S) Print version information -o --output <arg> (S) Output file [filename.pocc.c] --output-scop (S) Output scoplib file to filename.pocc.scop --cloogify-scheds (S) Create CLooG-compatible schedules in the scop --bounded-ctxt (S) Parser: bound all global parameters to >= -1 --default-ctxt (S) Parser: bound all global parameters to>= 32 --inscop-fakearray (E) Parser: use FAKEARRAY[i] to explicitly declare write dependences --read-scop (S) Parser: read SCoP file instead of C file as input --no-candl (S) Dependence analysis: don't run candl --candl-dep-isl-simp (E) Dependence analysis: simplify with ISL --candl-dep-prune (E) Dependence analysis: prune redundant deps --polyfeat (E) Run Polyhedral Feature Extraction --polyfeat-rar (E) Consider RAR dependences in PolyFeat -d --delete-files (S) Delete files previously generated by PoCC --verbose (S) Verbose output --quiet (S) Minimal output -l --letsee (S) Optimize with LetSee --letsee-space <arg> (E) LetSee: search space: [precut], schedule --letsee-walk <arg> (B) LetSee: traversal heuristic: [exhaust], random, skip, m1, dh, ga --letsee-dry-run (S) Only generate source files --letsee-normspace (E) LetSee: normalize search space --letsee-bounds <arg> (E) LetSee: search space bounds [-1,1,-1,1,-1,1] --letsee-mode-m1 <arg> (E) LetSee: scheme for M1 traversal [i+p,i,0] --letsee-rtries <arg> (E) LetSee: set number of random draws [50] --letsee-prune-precut (E) LetSee: prune precut space --letsee-backtrack (E) LetSee: allow bactracking in schedule mode -p --pluto (S) Optimize with PLuTo --pluto-parallel (S) PLuTo: Wavefront parallelization --pluto-tile (S) PLuTo: polyhedral tiling --pluto-l2tile (E) PLuTo: perform L2 tiling --pluto-fuse <arg> (S) PLuTo: fusion heuristic: maxfuse, [smartfuse], nofuse --pluto-unroll (E) PLuTo: unroll loops --pluto-ufactor <arg> (E) PLuTo: unrolling factor [4] --pluto-polyunroll (B) PLuTo: polyhedral unrolling --pluto-prevector (S) PLuTo: perform prevectorization --pluto-multipipe (E) PLuTo: multipipe --pluto-rar (S) PLuTo: consider RAR dependences --pluto-rar-cf (S) PLuTo: consider RAR dependences for cost function only --pluto-lastwriter (E) PLuTo: perform lastwriter dependence simplification --pluto-scalpriv (S) PLuTo: perform scalar privatization --pluto-bee (B) PLuTo: use Bee --pluto-quiet (S) PLuTo: be quiet --pluto-ft (S) PLuTo: CLooG ft --pluto-lt (S) PLuTo: CLooG lt --pluto-ext-candl (S) PLuTo: Read dependences from SCoP --pluto-tile-scat (S) PLuTo: Perform tiling inside scatterings --pluto-bounds <arg> (S) PLuTo: Transformation coefficients bounds [+inf] -n --no-codegen (S) Do not generate code --cloog-cloogf <arg> (S) CLooG: first level to scan [1] --cloog-cloogl <arg> (S) CLooG: last level to scan [-1] --print-cloog-file (S) CLooG: print input CLooG file --no-past (E) Do not use the PAST back-end --past-hoist-lb (S) Hoist loop bounds --pragmatizer (S) Use the AST pragmatizer --ptile (S) Use PTile for parametric tiling --ptile-fts (S) Use full-tile separation in PTile --punroll (S) Use PAST loop unrolling --register-tiling (E) PAST register tiling --punroll-size <arg> (S) PAST unrolling size [4] --vectorizer (S) Post-transform for vectorization --codegen-timercode (E) Codegen: insert timer code --codegen-timer-asm (E) Codegen: insert ASM timer code --codegen-timer-papi (E) Codegen: insert PAPI timer code -c --compile (S) Compile program with C compiler --compile-cmd <arg> (S) Compilation command [gcc -O3 -lm] --run-cmd-args <arg> (S) Program execution arguments [] --prog-timeout <arg> (E) Timeout for compilation and execution, in second
To run iterative search among possible precuts, with tiling and parallelization enabled:
$> pocc --letsee --pluto-tile --pluto-parallel --verbose gemver.c [...]
We experimented on three high-end machines: a 4-socket Intel hexa-core Xeon E7450 (Dunnington) at 2.4GHz with 64 GB of memory (24 cores, 24 hardware threads), a 4-socket AMD quad-core Opteron 8380 (Shanghai) at 2.50GHz (16 cores, 16 hardware threads) with 64 GB of memory, and an 2-socket IBM dual-core Power5+ at 1.65GHz (4 cores, 8 hardware threads) with 16 GB of memory.
All systems were running Linux 2.6.x. We used Intel ICC 10.0 with
options -fast -parallel -openmp referred to as
icc-par, and with -fast referred to as
icc-nopar, GCC 4.3.3 with options -O3 -msse3
-fopenmp as gcc, and IBM/XLC 10.1 compiled for Power5
with options -O3 -qhot=nosimd -qsmp -qthreaded referred to as
xlc-par, and -O3 -qhot=nosimd referred as
xlc-nopar. We report the performance of the precut
iterative compilation mode of PoCC as iter-xx when used on top
of the xx compiler. Precut search is enabled in PoCC with
options --letsee-space precut, and tiling and parallelization for precuts with --pluto-tile --pluto-parallel.
We consider 8 benchmarks, typical from compute-intensive sequences of algebra operations. atax, bicg and gemver are compositions of BLAS operations, ludcmp solves simultaneous linear equations by LU decomposition, advect3d is an advection kernel for weather modeling and doitgen is an in-place 3D-2D matrix product. correl creates a correlation matrix, and varcovar creates a variance-covariance matrix, both are used in Principal Component Analysis in the StatLib library. The time to compute the space, pick a candidate and compute a full transformation is negligible with respect to the compilation and execution time of the tested versions. In our experiments, the full compilation process takes a few seconds for the smaller benchmarks, and up to about 1 minute for correl on Xeon.
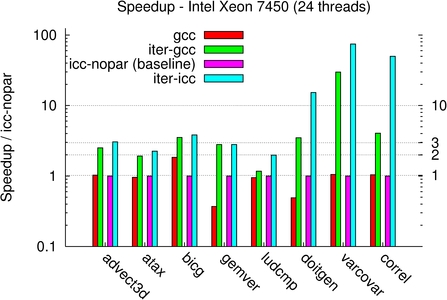
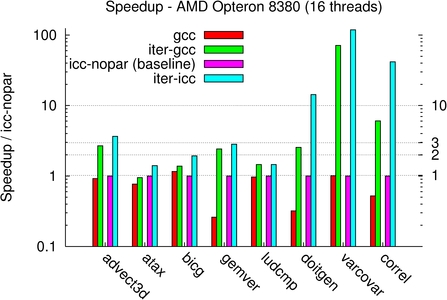
For doitgen, correl and varcovar, three compute-bound benchmarks, our technique exposes a program with a significant parallel speedup of up to 112x on the Opteron machine. Our optimization technique goes far beyond parallelizing programs, and for these benchmarks locality and vectorization improvements were achieved by our framework. For advect3d, atax, bicg, and gemver we also observe a significant speedup, but this is limited by memory bandwidth as these benchmarks are memory-bound. Yet, we are able to achieve a solid performance improvement for those benchmarks over the native compilers, of up to 3.8x for atax on the Xeon machine and 5x for advect3d on the Opteron machine. For ludcmp, although parallelism was exposed, the speedup remains limited as the program offers little opportunity for high-level optimizations. Yet, our technique outperforms the native compiler, by a factor up to 2x on the Xeon machine.
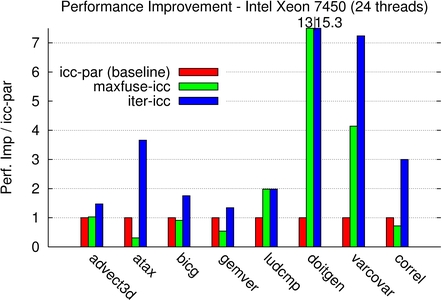
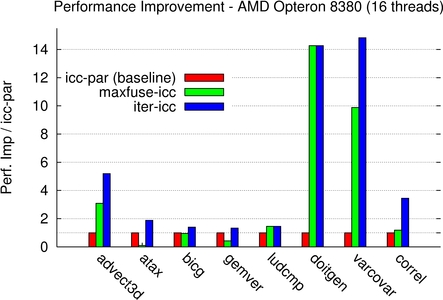
For the Xeon and Opteron machines, the iterative process outperforms ICC 10 with auto-parallelization, with a factor between 1.2x for gemver on Intel to 15.3x for doitgen. For both of these kernels, we also compared with an implementation using Intel Math Kernel Library (MKL) 10.0 and AMD Core Math Library (ACML) 4.1.0 for the Xeon and Opteron machines respectively, and we obtain a speedup of 1.5x to 3x over these vendor libraries.
For varcovar, our technique outperforms the native compiler by a factor up to 15x. Although maximal fusion significantly improved performance, the best iteratively found fusion structure allows for a much better improvement, up to 1.75x better. Maximal fusion is also outperformed for all but ludcmp and doitgen for some machines only. This highlights the power of the method to discover an efficient balance between parallelism (both coarse-grain and fine-grain) and locality.
On the Power5+ machine, on all but advect3d the iterative process outperforms XLC with auto-parallelization, by a factor between 1.1x for atax to 21x for varcovar.
Machine |
Speedup for Xeon, Opteron and Power5+ processors over the best single-threaded version |
Performance improvement over maximal fusion, and over the best reference auto-parallelizing compiler |
|
4-sockets Intel Dunnington Xeon E7450 24 H/W threads |
|
|
|
4-sockets AMD Shangai Opteron 8380 16 H/W threads |
|
|
|
2-sockets IBM dual-core Power5+ 8 H/W threads |
|
|
PoCC was supported in part by the EU-funded ACOTES project (European Union's Sixth Framework IST together with NXP, STMicroelectronics, Nokia, INRIA, IBM Haifa Research Lab and Universitat Politecnica de Catalunya)
| Advanced Compiler Technologies for Embedded Streaming: |

|
2/18/2013: Release of pocc-1.2
--pluto-tile-scat and --cloogify-scheds options together.