General Introduction
We propose a simple yet effective background subtraction method that learns and maintains dynamic texture models within spatio-temporal video patches (i.e. video bricks).
In our method, the scene background is decomposed into a number of regular cells, within which we extract a series of video bricks. The background modeling is solved by pursuing manifolds (i.e. learning subspaces) with video bricks at each background location (cell). By treating the series of video bricks as consecutive signals, we adopt the ARMA (Auto Regressive Moving Average) model to characterize spatio-temporal statistics in the subspace.
In the applications, we apply the proposed method in ten complex scenes outperform other state-of-the-art approaches.
Representation
We segment a video into cells and regard background in each cell as a spatio-temporal manifold consisting of small brick-like video patches. Video bricks with small size include relative simple content and can be thus generated by few bases (components), as shown in Fig.1.
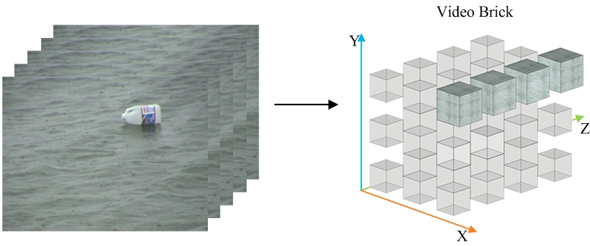
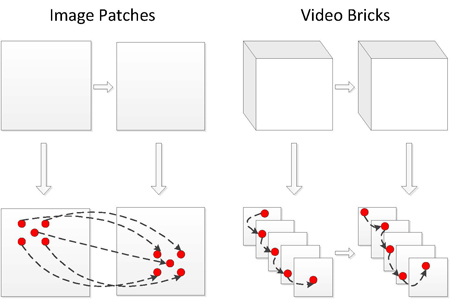
As illustrated in Fig.2, the dynamic models within image patches in the left panel and within video bricks in the right panel. The video brick representation enables us to capture more complex appearance and motion variations.
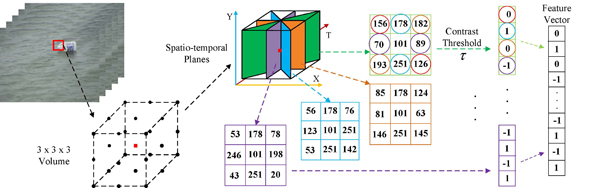
In order to make the algorithm more robust against illumination variances and background clutters, inspired by LBP operator, we design a novel descriptor, CS-STLTP, for encoding video bricks.
Learning
Initial Learning
In the initial learning stage, each manifold can be analytically learned, given sequences of video bricks. We employ a sub-optimal yet analytical solution proposed by S. Soatto et al.[3]
Online Learning
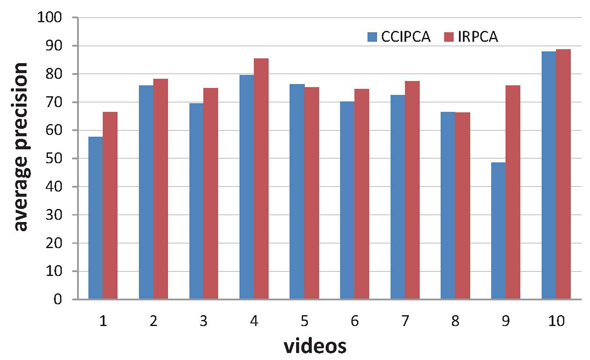
In the online learning stage, these manifolds can be automatically updated in real-time using the incremental subspace learning algorithm. Candid Covariance-Free IPCA (CCIPCA) has been applied for this task in [4,5]. In this work, we employ a recently proposed incremental robust PCA, namely IRPCA [6], which shows superior performance in experiments.
Experiments
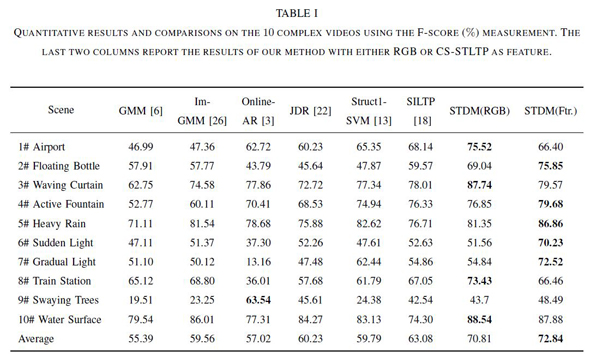
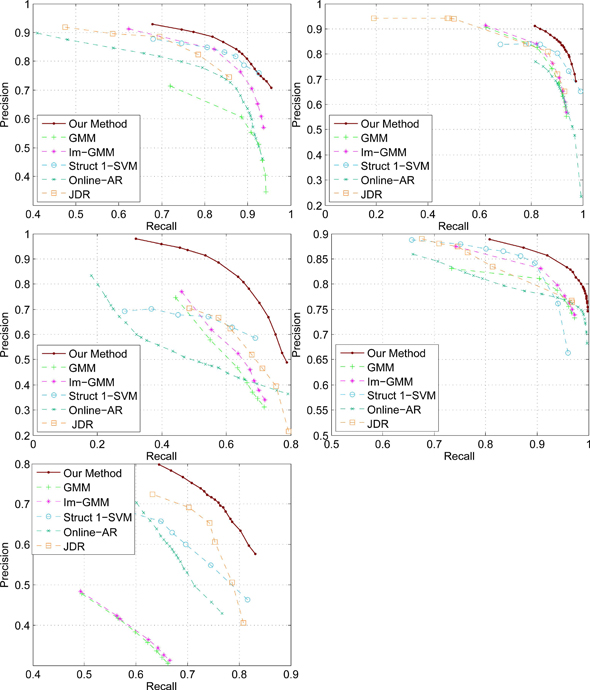
We evaluate our method on 10 videos. Two of them (AirportHall and Trainstation) from the PETS database include crowded pedestrians and moving cast shadows; five highly dynamic scenes including waving curtain active fountain, swaying trees, water surface; the others contain extremely difficult cases such as heavy rain, sudden and gradual light changing.
We compare the proposed method (STDM) with six start-of-the-art online background subtraction algorithms including Gaussian Mixture Model (GMM) as baseline, improved GMM (Im-GMM), online auto-regression model (Online-AR), non-parametric model with scale-invariant local patterns (SILTP), discriminative model using generalized Struct 1-SVM (Struct 1-SVM), and the Bayesian joint domain-range (JDR) model.
PR curves on 5 videos: first row left, the scene including a dynamic curtain and indistinctive foreground objects (i.e. having similar appearance with backgrounds); first row right, the scene with heavy rain; second row left, an indoor scene with the sudden lighting changes; second row right, the scene with dynamic water surface; third row, a busy airport.
Sampled results of background subtraction generated by our approach and other competing methods. The complete results can be found in the supplemental videos.

Comparison of different incremental subspace learning approaches.
Reference
- [1] Complex Background Subtraction by Pursuing Dynamic Spatio-temporal Manifolds. L. Lin, Y. Xu, X. Liang, J.H. Lai. IEEE Transactions on Image Processing (TIP), 2013. under revision. [pdf]
- [2] Moving Object Segmentation by Pursuing Local Spatio-Temporal Manifolds. Y. Xu. Undergraduate Thesis, 2012. [technical report]
- [3] Dynamic Textures. S. Soatto, G. Doretto, and Y. Wu. International Journal of Computer Vision (IJCV), 52(2):91–109, 2003.
- [4] Background Modeling and Subtraction of Dynamic Scenes. A. Monnet, A. Mittal, N. Paragios, V. Ramesh. In Proc. of IEEE International Conference on Computer Vision (ICCV), 2003.
- [5] Background Modeling by Subspace Learning on Spatio-Temporal Patches. Y. Zhao, H. Gong, Y. Jia, and S.C. Zhu. Pattern Recognition Letters, 33:1134–1147, 2012.
- [6] Dynamic textures. S. Soatto, G. Doretto, and Y. Wu. International Journal of Computer Vision (IJCV), 52(2):91–109, 2003.