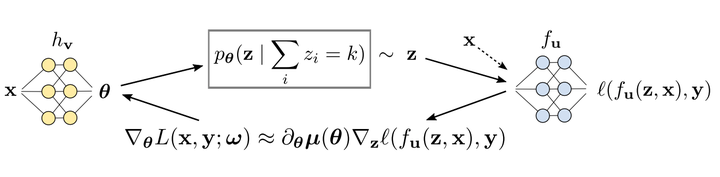 SIMPLE Pipeline
SIMPLE Pipeline
Abstract
k-subset sampling is ubiquitous in machine learning, enabling regularization and interpretability through sparsity. The challenge lies in rendering k-subset sampling amenable to end-to-end learning. This has typically involved relaxing the reparameterized samples to allow for backpropagation, with the risk of introducing high bias and high variance. In this work, we fall back to discrete k-subset sampling on the forward pass. This is coupled with using the gradient with respect to the exact marginals, computed efficiently, as a proxy for the true gradient. We show that our gradient estimator, SIMPLE, exhibits lower bias and variance compared to state-of-the-art estimators, including the straight-through Gumbel estimator when k=1. Empirical results show improved performance on learning to explain and sparse linear regression. We provide an algorithm for computing the exact ELBO for the k-subset distribution, obtaining significantly lower loss compared to SOTA.
Zhe Zeng
Ph.D. student in AI
My research goal is to enable machine learning models to incorporate diverse forms of constraints into probabilistic inference and learning in a principled way, by combining machine learning (probabilistic modeling, neuro-symbolic AI, Bayesian deep learning) and formal methods.