CS 111 Fall 2009
Modularity and Virtualization
Scribe Notes for Lecture 3: October 1st, 2009
by Li Soon Tay, Youngho Ka, Moon Bae
Performance is key!
Following from the last lecture, we will focus on the performance issues of the previously discussed operating system. It is slow!
To speed it up, there are 3 methods we can use:
1) Read 255 sectors from the hard disk at once
This saves on operational overhead, but uses more RAM for each load cycle, and performs unnecessary work reading redundant bits.
2) DMA (Direct Memory Access)
This is a hardware trick to make I/O faster.
The old method: The bus is used twice. Once for data to move from the disk controller to the CPU, and once for it to move between the CPU and the RAM.
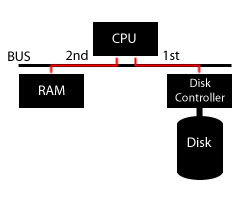
DMA: The controller talks to the RAM directly to send data, and notifies the CPU when it is done.
This means that our previously defined read_ide_sector() function has to be redefined to accomodate these operations.
3) Double Buffering (Overlapping reading and computing)
Instead of the traditional method of running operations one at a time, we can run two operations concurrently in parallel, by the use of an extra buffer.
The following picture may illustrate this better.
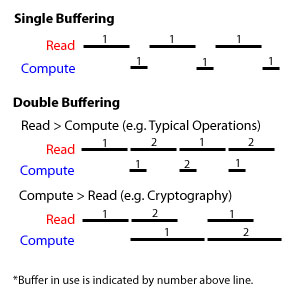
Double buffering can thus speed up the performance of our O/S. We can consider the use of triple buffering to run 3 different processes at one time to solve overhead problems, but there may be the problem of the HDD being able to read only one sector at a time.
Again, to do this many of our previously defined functions have to be rewritten.
Typical software engineering issues
The main breakdown of the issues relating to our previous operating system example:
1) It is too much of a pain to modify the system to fit changing needs or make improvements.
2) It is too hard to reuse parts of the program or maintain it. Right now we can only cut and paste, and are unable to reuse code in a more elegant manner.
3) It is too hard to run programs simultaneously (as it uses all the computer resources at once).
4) It is too hard to recover from errors (both hardware and software). It could result in the HDD wearing out due to looped reading, or cause the system to crash.
Today we will focus on points 1 and 2, which will make it easier to change our system and reuse code.
Why modular code?
A complicated system such as Microsoft Windows Vista probably has around 30 million lines of code, and it cannot be fully understood by 1 person. It is thus logical to break it into smaller systems each understood by a person or group. As such, each part of a system can be managed and maintained more efficiently.
To illustrate this point, let us assume that the cost of fixing a bug is proportional to module size, and examine the effect on findings bugs given an arbitrary system.
Let
N represent lines of code
M represent number of modules
B represent number of bugs
Debug time assuming no modules (hence M = 1) is proportional to B*N.
If there are M modules, debug time is proportional to (B/M)*(N/M)*M = B*N/M (only for bugs that reside in a single module).
As a general rule, the more modules we have, the less debug time is required. We can thus use this model as a good estimate of the required debug time for bugs that reside in only one module, as most bugs occur in single modules. However, we do take into account that some bugs can span across multiple modules, and more time will be needed to examine all the different modules relating to the bug, in turn increasing debug time.
Modularity against complexity
Modularity is one of the best weapons against complexity. We can consider certain factors that are of interest:
1) Performance (may be affected): Generally modularity boosts performance, but due to CPU and RAM overhead this may not always be true. The goal here is to reduce this penalty.
2) Simplicity: Too many modules may in turn further complicate things. We are looking for a reasonable mean between the number of modules and complexity.
3) Debugging: Modules allow for the isolation of faults. This is also a subset of robustness, which the ideal case is that a failure in one part will not hurt the entire system.
4) Flexibility: The ability to change parts of code on demand, with lack of assumptions. This allows for easy reuse of code.
Redefining the API
As mentioned earlier, we need to redefine certain functions so that they are more modular.
A very good example to focus on would be the read_ide_sector() function.
As discussed in class, to ensure modularity this read function has to be revised multiple times so that it can fit a wide range of purposes. In other words, we want it to be as general as possible. We will begin with the version derived from the last lecture, then step through each revision while examining the reasons for change.
void read_ide_sector(int s, char *a);
s represents the sector number to read from, and the character pointer a is used to store the read data.
Return type of void does not allow for error checking: use int to return result of read
Name read_ide_sector limits to only IDE hard disks, want flexibility for other interfaces: remove ide
Name sector limits to 512 bytes a sector (typical size is 512, other sectors can have 1024 or 2048 bytes): use bytes instead
Add size argument to specify number of bytes to read for
int read_bytes(int s, char *a, int size);
This function does not handle more than 1 disk: add extra argument dev to specify which device to read from
int read_bytes(int dev, int s, char *a, int size);
Data types of arguments limited in size (in this case int): use more appropriate data types dev_t, off_t, size_t
There are marked differences when it comes to the preferential use of off_t and size_t as compared to int. For the x86 32-bit processor architecture, int is signed 32-bits, off_t is signed 64-bits, and size_t is unsigned 32-bits. For the x86 64-bit processor, int is still signed 32-bits, off_t is still signed 64-bits, but size_t is now unsigned 64-bits. This allows us to refer to larger address locations on disks with ever-increasing capacities.
int read_bytes(dev_t dev, off_t o, char *a, size_t size);
Argument o allows us to read between sectors, by specifying a starting address followed by the size of bytes to read.
However, since the O/S remembers where the head is on any particular disk, we can use an argument to specify either the absolute address of the location to read, or an offset relative to the current position. We then add a flag to indicate which one of the two is required, and use it to indicate whether it is an absolute address or a relative offset (1 indicates it is relative, 0 indicates it is absolute). This ability is observed in the lseek() function described below. Following an lseek() operation, we can then use the read() function (also described below) to obtain the data from the disk.
This pair of functions is the typical method by which files are read in Linux (more on the read() and lseek() functions). However, for compatibility reasons, this version of the read_byte() function still exists in Linux to facilitate a single function retrieval of data from disk. It is also more efficient to use read_byte() for random access.
int read(dev_t dev, char *a, size_t size);
off_t lseek(dev_t dev, off_t o, int flag);
Here, lseek() returns the new seek location as its return value.
Using these two functions, we are still unable to read 2 files on 1 device. To solve this problem, we use file descriptors (more on file descriptors). File descriptors allow us to point to different files on the same device
int read(int fd, char *a, size_t size);
off_t lseek(int fd, off_t o, int flag);
In the design of these functions, we have avoided the use of globalized variables. This is crucial because global variables can cause many problems, especially with processors today that are capable of hyperthreading (certain registers or areas of memory can become hotspots, which is undesirable).
An extra trivia:
The old 16-bit seek() operation was defined as follows:
int seek(int fd, int sector, int flag);
The l is used in lseek() to differentiate it from the old seek() function.
Implementation of the API
Our read() function has 2 properties. Firstly it is an abstraction, which means that it is simpler than the underlying machine. Secondly, it is a virtualization. This means that read() handles the machine on its own, and the caller needs not/does not have access to the underlying machine.
These 2 properties are ideal properties of modularization.
How to implement virtualization (or enforce modularity)
The most basic way to do this is to hope that the programmer does the right thing, making use of the honor system. However, understandably this is not a very reliable approach. We thus have to look at function call modularity to accomplish virtualization. This usually means that there is an extra layer of function calls between the application and the underlying operation.
To do this we can examine some code that makes use of function calls. However, before we do that it is imperative to learn how memory typically looks like in computers.
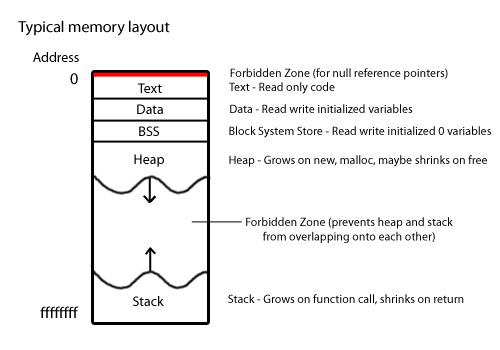
From above, we can see that the area we are most concerned with is the stack, where return addresses and other function-related data are stored.
Now, an example using a recursive factorial function (inefficient version):
int fact(int n) {
if (n == 0)
return 1;
return n * fact(n-1);
}
After compiling with GCC the machine code is:
pushl %ebp // %ebp: Input
movl $1, %eax // %eax: Return value
movl %esp, %ebp // %esp: Stack pointer | %ebp: Base pointer
movl 8(%ebp), %edx // Add 8 to ebp, copy to edx
testl %edx, %edx // %edx: Arithmetic
je .L6
.L5: imull %edx, %eax
decl %eax
jne .L5
.L6: popl %ebp
ret
The corresponding C code that can be derived from this machine code:
*--sp = bp;
ax = 1;
bp = sp;
dx = sp[2];
if (edx == 0) goto L6;
ax *= dx;
if (ax--) goto L5;
bp = *sp++;
Notice that after compiling there is no recursion in this code!
With a main routine that calls the above factorial program (with an arbitrary value):
pushl $10
call fact
add $4, %esp
We can see that it is possible
for the program to add 4 bytes (a word is 4 bytes long) to the
stack pointer, which will then point at the intended return address of this program (taking in mind the typical layout of memory, where the stack builds upwards to lower address values). If the program decides to change this return address
to another location in memory, which can potentially contain malicious code, or even so far as to access beyond the end of the stack, the consequences may be disastrous.
Function calls are implemented via the ABI (more on Application Binary Interface), which is a sort of contract between the caller and the callee. In our example, the caller is the O/S, and the callee is the program.
Given the above example, we can see that this contract can easily be broken.
A non-exhaustive list of ways to break the contract:
1) The callee can put a return value into dx.
2) The callee can mess up the stack pointer.
3) The callee can move $27, 48(sp). This can potentially modify a random variable in the caller's variable list.
4) The callee can refuse to return, resulting in an infinite loop. The callee can also pop everything off the stack, or run other malicious code.
As one can see, this contract relies on the honor system, which in other words is called soft modularity, and it is not robust.
We want hard modularity. This way, a failure in one module will not affect the rest of the system.
Ways to implement hard modularity
1) We can use a client/service organization, where the callee is run on a different machine, and there are no shared states. The advantage that this approach provides is that the caller can now handle any infinite looping in the callee. However, it is slow, especially for smaller programs, due to the overhead of running on a different machine. This can also be complicated, because the programmer has to take into account the different situations that may occur, and it will necessarily be complex if it is to be robust.
An example: A caller sends a request to calculate the factorial of 6 to a callee. The callee will listen for the input, receive and decode it, then compute its factorial. After that, the callee will send the result back to the caller. The caller will then receive this result.
Caller: send("!6", callee);
Callee: listen for input
Callee: v = receive();
Callee: decode(v);
Callee: compute 6!
Callee: send("720");
Caller: v = receive();
2) To isolate the caller and the callee, we can also use an x86 emulator. In this case, the callee runs in the emulator, which is invoked by the caller. The emulator is designed to catch loops or errors in the callee, by checking for all memory references and I/O instructions. However, not all loops can be caught by the emulator, due to the halting problem. The downside of this approach is that it is slow, considering once again the overheads involved in setting up the emulator.
3) The most commonly used method today is a virtualizable processor. This approach allows the callee to normally run at full speed. However, whenever the callee tries to access any of the caller's registers or RAM, it is stopped by the caller, and the caller takes control. The caller may then take appropriate steps to handle the situation. Otherwise, if nothing out of the ordinary happens, the program runs normally in an isolated environment.
End of Notes