Scribed by: Georgi Baghdasaryan
In the last section, we introduced a Very Secured Word Counter (VSWC) - a standalone application that securely counts number of words in a given file. Here we will cover different issues related to VSWC's implementation as well as introduce you to the principle of modularity.
Some problems with our standalone application are:
First, we will focus on VSWC's performance issues. We will cover three major ways of improving program performance:
Other ways, like getting a faster drive (e.g. SSD) or going RAID, are possible but will not be discussed here.
Let's consider the case when data processing takes less time than reading data into a buffer.

As it can be seen from the above picture, a lot of time is spent on reading data into a buffer and context-switching. Increasing the the buffer size would result in minimizing the time program spends on switching between reading and processing (context-switching), as shown below.

Method pros and cons:
+ Batching lessens overhead (assuming that we read data from big files).
-- Memory issue -- program can run out of memory (RAM) while reading data into a buffer, in case the buffer size is bigger than the RAM. So, we actually might have a problem with choosing a correct size for the buffer.
-- Wasted work for small files -- program will be getting too much of unnecessary data in case if provided file is small.
Now, let's look at the case when data processing takes as much time as copying data from disk to RAM does.

In this case, we have a single buffer. As it can be seen from above figure, CPU and I/O devices each have large idling time, because one has to wait for the other one to finish, before it can start its own task. This scheme has an occupancy issue, since only one device can do useful work at a time.
Double buffering is one of the ways to solve this problem. It allows CPU to work on data from the first buffer while I/O writes to the second one, and then they switch. This is illustrated in the figure below.

As it can be seen from the above figure, reading and processing happen almost in parallel when we take advantage of double buffering.
Method pros and cons:
+ No idle time => Double buffering lowers the execution time by a factor of 2 if CPUtime ~ I/O time, but it is still faster than a single buffer even if CPUtime != I/O time.
-- Twice as much RAM is needed
Question: We just showed that double buffering
doubles the speed of the program, will triple buffering
decrease execution time by a factor of 3?
Answer: No, one buffer would be extra for several reasons:
It might be useful to draw diagrams to understand the above answer.
In VSWC, we used insl extensively as our method for copying data from hard disk to RAM. However, insl instruction is slow. As it was designed, it transports data from the disk to CPU, and then to RAM. Since all three components (disk, CPU and RAM) shares the same bus, this method is effectively occupying it for twice as long as is needed, slowing down other parts of the system as many operations require the shared bus to be free. Figure below shows how insl works.
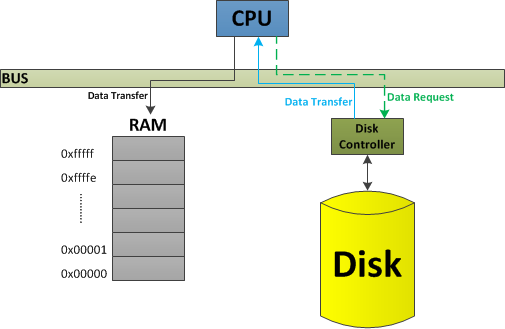
To correct this problem, we can use a method of data transport known as Direct Memory Access (DMA) to access data on disk. In DMA, disk controller issues the transfer of data to the RAM directly, skipping the middle-man – CPU. In this way, bus used only one time (instead of two as in the case of PIO), which improves the overall performance of our program. Following graph shows an example of Direct Memory Access.
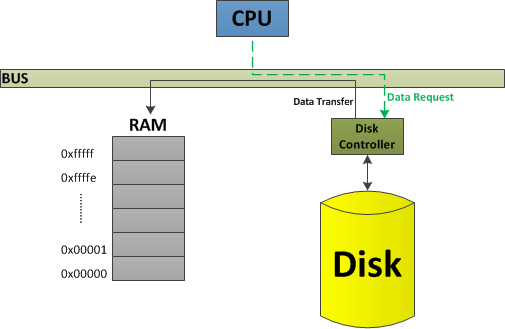
In the above section we attempted to solve the problem of VSWC's poor performance. Here, we will redirect our attention to problems of modifying, maintaining, debugging and reusing previously written code. Using modularity and abstraction is one of the ways to attempt solving these issues.
Modularity is a degree to which system's components may be separated and recombined. In other words, modularity represents how well a big system can be broken into manageable pieces, which can be changed without a need to alter other modules. We use it to break big programs into parts, mainly improve the maintenance.
Example: Analyzing the effect of Modularity on finding and fixing bugs.
Notation:Comparing cases (1) and (2), we see that with M modules, we reduce the amount of time to find and fix all bugs to 1/M of the original time (without modules).
Question: Does it mean that the more modules we use the easier it will be to maintain the program?One of the ways to decide what kind of modularization to choose is to consult modularity metrics:
Supporting modularity is a very good as well as important coding practice. In order to support modularity, it is discouraged to use lots of global variables and to create one function that does all the work. Global variables may introduce undefined behaviors when changed from different functions, while one huge function (just like Turing Machine)is incapable of supporting modularity.
Here are three basic methods one can follow for creating modular code:
Soft modularity can be though as a division of a big program into small independent blocks without using any "special" (e.g. hardware) techniques. Function modularity can serve as a nice example of soft modularity.
Separating code into functions separates processes from each other. This allows each process to be considered individually, which makes the debugging much easier. In addition, functional modularity allows functions to be reused in different programs, which makes the code even more modular.
Recursion is a special case of function call where the caller is also the callee. We shall examine the code for a factorial function as an example.
int fact(int n) {
if (n == 0)
return 1;
return n * fact(n-1);
}
And here is how the ASSEMBLY code for this function would look like:
fact: pushl %ebp ; *--sp = bp movl $1, %eax ; ax = 1 movl %esp, %ebp ; bp = sp subl $8, %esp ; sp = sp -8 movl %ebx, -4(%ebp) ; bp[-1] = bx movl 8(%ebp), %ebx ; bx = bp[2] testl %ebx, %ebx ; if (n != 0) jne .L5 ; goto .L5 .L1 movl -4(%ebp), %ebx ; bx = bp[-1] movl %ebp, %esp ; sp = bp popl %ebp ; bp = *sp++ ret ; ip = *sp++ .L5 leal -1(%ebx), %eax ; ax = bx -1 movl %eax, (%esp) ; *sp = ax call fact ; *sp++ = ip // ip = fact imull %ebx, %eax ; ax = ax * bx jmp .L1
Soft modularity depends on modules working together. There is a certain amount of trust between the caller and the callee. In consequence, any errors suffered by one module may propagate into another, as modularity is not enforced and the contract may be broken regardless of programmer's intentions.
A caller-callee contract (i.e. an agreement between the caller and callee of the function) is necessary for creating functional modularity, so that this process would work without security breaches and/or bugs.
The unwritten caller-callee contract consists of the following conditions:
Anything can go wrong in the case if caller-callee contract is violated. Thus, in order to have enforced modularity, it is necessary to use external mechanisms that limit interaction between modules.
Hard modularity restricts interaction between modules and validates expected results from a module. One way to do is this by organizing modules as clients and services, which communicate through requests and responses respectively.
Hard modularity is enforced because since the client and the service do not share memory, and modules can check the validity of the messages sent between them. In consequence, hard modularity via client/service is much slower than soft modularity.
In the factorial example, hard modularity can be implemented with a web service available at a URL such as http://factorial.cs.ucla.edu/fact=23 and the factorial of 23 would be printed in the browser. In this example factorial.cs.ucla.edu is the service and the browser is the client. If for some reason the web service goes into an infinite loop is becomes unavailable, the browser as an automatic response to stop waiting for a response or to display an availability error.
Conceptually the service and the client are on separate computers but using the OS, the two modules can exist on the same computer.
We can simulate the client/server organization on one computer by using virtualization. This means that a separate virtual computer is used to execute a module.
For example in the case of the factorial function, using a virtual x86 machine we can have an instruction called factl which produces the same results as that stores its return value in %eax. The factl instruction executes in a virtual memory and eliminates the possibility of memory overwriting from other modules.
Virtualization causes extra overhead and we need to speed up the process for it to be usable.