Lecture 12: File System Design
Mahir Shah
November 17th, 2014
Table of Contents
1. Introduction
File System: A data structure (on disk and in RAM) that provides an abstraction representing a collection of files. A file system is a hybrid data structure, which lives on the disk and in memory.
2. Simple File System (1974)
The figure below describes the file system architecture:
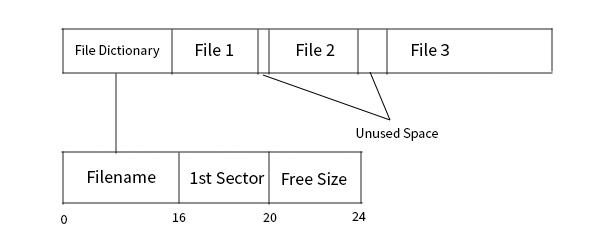
This file system can be thought of as an array of files. Each file is allocated contiguously and at the beginning of the array, a file dictionary is stored. This dictionary stores important metadata regarding the files, including the filename, the location of the start of the file in the array, and how much free size is left in the sector.
This type of file system is similar to those found in RT-11 operating systems. This is because of the inherent reliability that comes with using a file system like this.
| Pros | Cons |
|---|---|
| Simple architecture and implementation | the max number of files is determined by the directory size |
| fewer seeks if I/O is sequential | file size (bounds) must be known in advance |
| Internal fragmentation is rampant. Since the files are allocated along sector boundaries, there is wasted space left at the end of a sector. | |
| External fragmentation also occurs. You may have enough free space in the file system to store a file, but it may not be contiguous, so you cannot store the file. |
3. FAT File System (~1977)
- goal is to lessen fragmentation
- eliminate external fragmentation
- lessen internal fragmentation
The figure below describes the file system architecture:
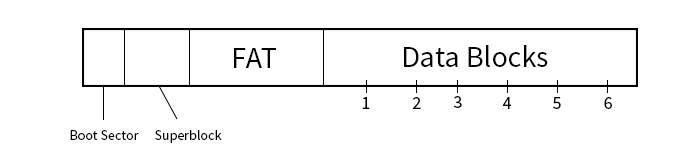
- 1. Boot Sector:
- This is initially empty but can be loaded with the Master Boot Record.
- 2. Superblock:
- This holds data about the system like the version, block size, and block number of the root directory
- 3. FAT (File Allocation Table):
-
An array of 16-bit block numbers, which can be 3 possible values:
- -1 indicates a free block
- 0 indicates EOF, or the next block has nothing
- A Block number i, indicates the next block in this file
- 4. Data Blocks
- The files are stored here, but split amongst different blocks--each of size 4 KiB
- metadata is mixed in with the data
- The block sizes would no longer be powers of 2
In the FAT filesystem the directory entries are files! Below is an image describing a FAT directory entry:

| Pros | Cons |
|---|---|
| No external fragmentation | Linked List implementation means that there can be slow sequential access |
| Files can grow dynamically | Internal fragmentation still exists |
| Very hard to move files between directories |
One possible solution to fix slow sequential access is to defragment, where same file blocks are moved to be sequential. But there are major disadvantages to this:
- It can be unreliable if the power goes out or if something unexpected happens
- The process can slow and intensive
4. Inode-Based File System (~1973)
Found in Unix v7 (1977). Below is a diagram of the file system:
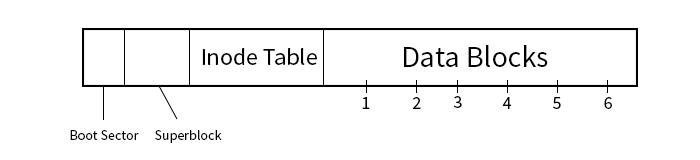
- 1. Boot Sector:
- This is initially empty but can be loaded with the Master Boot Record.
- 2. Superblock:
- This holds data about the system like the version, block size, and inode number of the root directory
- 3. Inode Table:
-
An array of metadata for each file, including which blocks the file is stored in.
- The first part of the of the inode entry contains file information like the owner, group, permissions, time stamp, size, and the link count
- The next ten numbers in the inode entry correspond to the block numbers in which the file is stored
- The next section is a pointer to an "indirect block". This indirect block consists of pointers that point to blocks with block numbers.
- If there is additional space needed, a double indirection can be created by creating an indirect block that points to other indirect blocks.
- 4. Data Blocks
- The files are stored here, but split amongst different blocks--each of size 8 KiB
5. BSD File System (~1980)
Also called the fast file system-this is very similar to the Inode based file system. Below is a diagram:
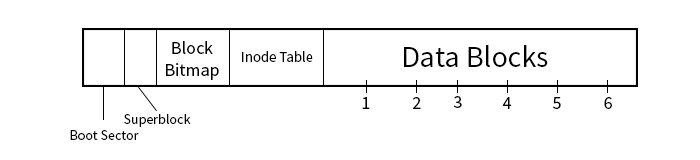
- 1. Boot Sector:
- This is initially empty but can be loaded with the Master Boot Record.
- 2. Superblock:
- This holds data about the system like the version, block size, and inode number of the root directory
- 3. Block Bitmap
- Each bit tells if the corresponding block is free
- 4. Inode Table:
-
An array of metadata for each file, including which blocks the file is stored in.
- The first part of the of the inode entry contains file information like the owner, group, permissions, time stamp, size, and the link count
- The next ten numbers in the inode entry correspond to the block numbers in which the file is stored
- The next section is a pointer to an "indirect block". This indirect block consists of pointers that point to blocks with block numbers.
- If there is additional space needed, a double indirection can be created by creating an indirect block that points to other indirect blocks.
- 5. Data Blocks
- The files are stored here, but split amongst different blocks--each of size 8 KiB
| Pros | Cons |
|---|---|
| Finding free space is faster via the bitmap | more internal fragmentation |
| hard links | |
| lseek is faster becuase no need to go through linked list |
Hard Links
In the FAT file system it was very hard to move a file from one directory to another. In an inode based file system, moving files between directories can be done in the following way:
link("d/xyz", "e/xyz");
unlink("d/xyz");
When we use link, we don't rename the file, but create a directory entry that points to the same inode. This is called a hard link. When we use unlink, we destroy the old directory entry, which effectively moves the file to the new directory.
Each inode keeps track of the number of links pointing to it. This is how the operating system knows when to reclaim storage.
How can we create a file with link count 0?
fd = open("file", O_RDWR | O_CREAT ...);
unlink("file");
read(fd, ...);
write(fd, ...);
fstat(fd, &st); //st.nlink_t = 0
We created a file with link count 0 because storage is not reclaimed until:
- Link count = 0
- Last file descriptor is closed. The RAM records open files.
How do we interpret file names?
For example, if we open "a/b/c/d" how do we interpret this? We read left to right and match each directory to an inode number. If we know a/b's inode number we can find a/b/c's inode number, and then advance the cursor to "d" and repeat the process.