Efficient Contextual Representation Learning With Continuous Outputs
Liunian Harold Li, Patrick H. Chen, Cho-Jui Hsieh, and Kai-Wei Chang, in TACL, 2019.
SlidesDownload the full text
Abstract
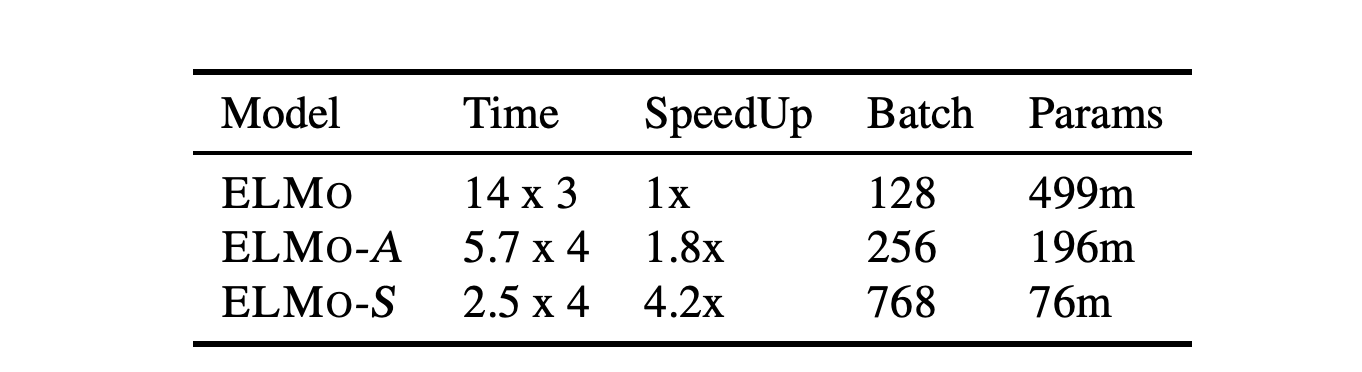
Contextual representation models have achieved great success in improving various downstream natural language processing tasks. However, these language-model-based encoders are difficult to train due to their large parameter size and high computational complexity. By carefully examining the training procedure, we observe that the softmax layer, which predicts a distribution of the target word, often induces significant overhead, especially when the vocabulary size is large. Therefore, we revisit the design of the output layer and consider directly predicting the pre-trained embedding of the target word for a given context. When applied to ELMo, the proposed approach achieves a 4 times speedup and eliminates 80% trainable parameters while achieving competitive performance on downstream tasks. Further analysis shows that the approach maintains the speed advantage under various settings, even when the sentence encoder is scaled up.
Bib Entry
@inproceedings{li2019efficient,
author = {Li, Liunian Harold and Chen, Patrick H. and Hsieh, Cho-Jui and Chang, Kai-Wei},
title = {Efficient Contextual Representation Learning With Continuous Outputs},
booktitle = {TACL},
year = {2019}
}
Related Publications
-
Distributed Block-diagonal Approximation Methods for Regularized Empirical Risk Minimization
Ching-pei Lee and Kai-Wei Chang, in Machine Learning Journal, 2019.
Full Text Code Abstract BibTeX DetailsDetailsDesigning distributed algorithms for empirical risk minimization (ERM) has become an active research topic in recent years because of the practical need to deal with the huge volume of data. In this paper, we propose a general framework for training an ERM model via solving its dual problem in parallel over multiple machines. Our method provides a versatile approach for many large-scale machine learning problems, including linear binary/multi-class classification, regression, and structured prediction. Comparing with existing approaches, we show that our method has faster convergence under weaker conditions both theoretically and empirically.
@inproceedings{LD17, author = {Lee, Ching-pei and Chang, Kai-Wei}, title = {Distributed Block-diagonal Approximation Methods for Regularized Empirical Risk Minimization}, booktitle = {Machine Learning Journal}, year = {2019} } -
Robust Text Classifier on Test-Time Budgets
Md Rizwan Parvez, Tolga Bolukbasi, Kai-Wei Chang, and Venkatesh Saligrama, in EMNLP (short), 2019.
Full Text Slides Code Abstract BibTeX DetailsDetailsWe propose a generic and interpretable learning framework for building robust text classification model that achieves accuracy comparable to full models under test-time budget constraints. Our approach learns a selector to identify words that are relevant to the prediction tasks and passes them to the classifier for processing. The selector is trained jointly with the classifier and directly learns to incorporate with the classifier. We further propose a data aggregation scheme to improve the robustness of the classifier. Our learning framework is general and can be incorporated with any type of text classification model. On real-world data, we show that the proposed approach improves the performance of a given classifier and speeds up the model with a mere loss in accuracy performance.
@inproceedings{parvez2019robust, author = {Parvez, Md Rizwan and Bolukbasi, Tolga and Chang, Kai-Wei and Saligrama, Venkatesh}, title = {Robust Text Classifier on Test-Time Budgets}, booktitle = {EMNLP (short)}, year = {2019} } -
Efficient Contextual Representation Learning With Continuous Outputs
Liunian Harold Li, Patrick H. Chen, Cho-Jui Hsieh, and Kai-Wei Chang, in TACL, 2019.
Full Text Slides Video Abstract BibTeX DetailsDetailsContextual representation models have achieved great success in improving various downstream natural language processing tasks. However, these language-model-based encoders are difficult to train due to their large parameter size and high computational complexity. By carefully examining the training procedure, we observe that the softmax layer, which predicts a distribution of the target word, often induces significant overhead, especially when the vocabulary size is large. Therefore, we revisit the design of the output layer and consider directly predicting the pre-trained embedding of the target word for a given context. When applied to ELMo, the proposed approach achieves a 4 times speedup and eliminates 80% trainable parameters while achieving competitive performance on downstream tasks. Further analysis shows that the approach maintains the speed advantage under various settings, even when the sentence encoder is scaled up.
@inproceedings{li2019efficient, author = {Li, Liunian Harold and Chen, Patrick H. and Hsieh, Cho-Jui and Chang, Kai-Wei}, title = {Efficient Contextual Representation Learning With Continuous Outputs}, booktitle = {TACL}, year = {2019} } -
Structured Prediction with Test-time Budget Constraints
Tolga Bolukbasi, Kai-Wei Chang, Joseph Wang, and Venkatesh Saligrama, in AAAI, 2017.
Full Text Slides Abstract BibTeX DetailsDetailsWe study the problem of structured prediction under test-time budget constraints. We propose a novel approach applicable to a wide range of structured prediction problems in computer vision and natural language processing. Our approach seeks to adaptively generate computationally costly features during test-time in order to reduce the computational cost of prediction while maintaining prediction performance. We show that training the adaptive feature generation system can be reduced to a series of structured learning problems, resulting in efficient training using existing structured learning algorithms. This framework provides theoretical justification for several existing heuristic approaches found in literature. We evaluate our proposed adaptive system on two real-world structured prediction tasks, optical character recognition (OCR) and dependency parsing. For OCR our method cuts the feature acquisition time by half coming within a 1% margin of top accuracy. For dependency parsing we realize an overall runtime gain of 20% without significant loss in performance.
@inproceedings{bolukbasi2017structured, author = {Bolukbasi, Tolga and Chang, Kai-Wei and Wang, Joseph and Saligrama, Venkatesh}, title = {Structured Prediction with Test-time Budget Constraints}, booktitle = {AAAI}, year = {2017} } -
A Credit Assignment Compiler for Joint Prediction
Kai-Wei Chang, He He, Hal Daume III, John Langford, and Stephane Ross, in NeurIPS, 2016.
Full Text Code Abstract BibTeX DetailsDetailsMany machine learning applications involve jointly predicting multiple mutually dependent output variables. Learning to search is a family of methods where the complex decision problem is cast into a sequence of decisions via a search space. Although these methods have shown promise both in theory and in practice, implementing them has been burdensomely awkward. In this paper, we show the search space can be defined by an arbitrary imperative program, turning learning to search into a credit assignment compiler. Altogether with the algorithmic improvements for the compiler, we radically reduce the complexity of programming and the running time. We demonstrate the feasibility of our approach on multiple joint prediction tasks. In all cases, we obtain accuracies as high as alternative approaches, at drastically reduced execution and programming time.
@inproceedings{chang2016credit, author = {Chang, Kai-Wei and He, He and III, Hal Daume and Langford, John and Ross, Stephane}, title = {A Credit Assignment Compiler for Joint Prediction}, booktitle = {NeurIPS}, year = {2016} } -
Learning to Search Better Than Your Teacher
Kai-Wei Chang, Akshay Krishnamurthy, Alekh Agarwal, Hal Daume; III, and John Langford, in ICML, 2015.
Full Text Video Code Abstract BibTeX DetailsDetailsMethods for learning to search for structured prediction typically imitate a reference policy, with existing theoretical guarantees demonstrating low regret compared to that reference. This is unsatisfactory in many applications where the reference policy is suboptimal and the goal of learning is to improve upon it. Can learning to search work even when the reference is poor? We provide a new learning to search algorithm, LOLS, which does well relative to the reference policy, but additionally guarantees low regret compared to deviations from the learned policy: a local-optimality guarantee. Consequently, LOLS can improve upon the reference policy, unlike previous algorithms. This enables us to develop structured contextual bandits, a partial information structured prediction setting with many potential applications.
@inproceedings{chang2015learninh, author = {Chang, Kai-Wei and Krishnamurthy, Akshay and Agarwal, Alekh and III, Hal Daume; and Langford, John}, title = {Learning to Search Better Than Your Teacher}, booktitle = {ICML}, year = {2015} } -
Structural Learning with Amortized Inference
Kai-Wei Chang, Shyam Upadhyay, Gourab Kundu, and Dan Roth, in AAAI, 2015.
Full Text Poster Abstract BibTeX DetailsDetailsTraining a structured prediction model involves performing several loss-augmented inference steps. Over the lifetime of the training, many of these inference problems, although different, share the same solution. We propose AI-DCD, an Amortized Inference framework for Dual Coordinate Descent method, an approximate learning algorithm, that accelerates the training process by exploiting this redundancy of solutions, without compromising the performance of the model. We show the efficacy of our method by training a structured SVM using dual coordinate descent for an entity-relation extraction task. Our method learns the same model as an exact training algorithm would, but call the inference engine only in 10% . 24% of the inference problems encountered during training. We observe similar gains on a multi-label classification task and with a Structured Perceptron model for the entity-relation task.
@inproceedings{chang2015structural, author = {Chang, Kai-Wei and Upadhyay, Shyam and Kundu, Gourab and Roth, Dan}, title = {Structural Learning with Amortized Inference}, booktitle = {AAAI}, year = {2015} }