CS 111 Fall 2014 : Lecture 10: File System
by Yoo Jung Choi, Dong Joon Kim, Han Sung Lee, and Seung Won Yoon
Table of Contents
- File System Needs
- File System Examples
- Hardware Components For File System
- File System Performance Metrics
- Performance Metrics Examples
File System Needs
File System has three needs:
-
Organization
- The system needs to organize the disk space in order to access memory easily.
-
Performance
- The system needs to be able to access memory efficiently and fast.
-
Reliability
- The system needs all the data accesses to be reliable. You do not want loss of data.
Note:
There will be trade-offs. The system designer may need to select one from three needs.
File System Examples
-
Definition:
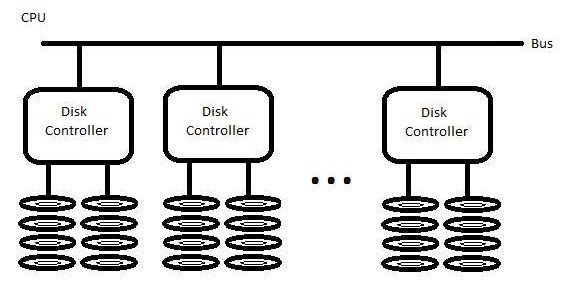
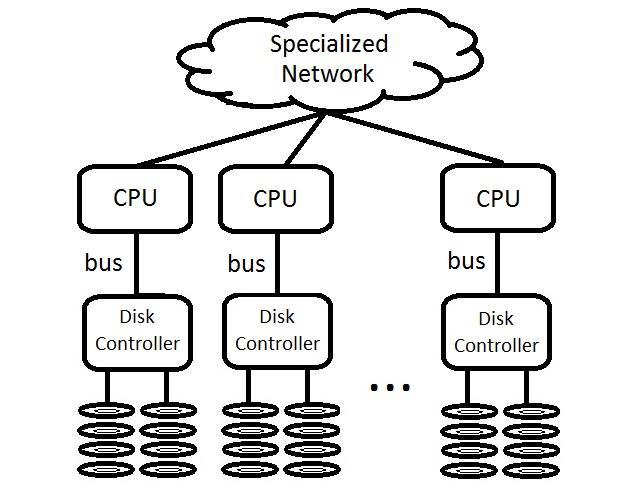
File system designed for multiple shared hard drives. It contains multiple CPUs, buses, and disk controllers. There are multiple buses because the traditional design of many disk controllers being connected to single bus would cause severe performance hit. CPUs and buses are attached to special network so that one CPU can get data from another bus that is not conencted to itself.
-
Striping
- Split single file data among different CPU/drive in stripes. Slow because reading a file requires talking to different CPUs.

-
Distributed metadata
- Catalog itself is distributed. Having a central catalog that maps files to locations creates a bottleneck, if all start talking to that catalog.
-
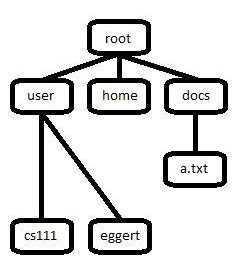
Efficient directory indexing
- If directory contains too many files, it is impractical to store entire directory in cache, and thus file access becomes slow. Use a tree structure for efficient indexing. (i.e. 2-3 tree)
-
Distributed locking
- Locking system to synchronize multiple shared resources. It is very hard to implement.
-
Partition awareness
- The system needs to function even when there is network partition due to problem in the network. Majority part of the partition gets both read and write access, while the minority part gets read-only access.
-
File System staying live during maintenance
- Do not want system to go down during routine maintenance.
Hardware Components For File System
Traditional hierarchy of hardware components:
- CPU registers (fastest forms of storage commonly available)
- CPU cache L1
- CPU cache L2
- RAM
- Flash drive
- Disk drive
- Backup tapes (very slow)
Note:
As you move down this hierarchy, cost per unit goes down but efficiency of access goes up.
File System Performance Metrics
Performance metrics:
- Latency - turnaround time from request to response
- Throughput - rate of request completions (in bytes per second)
- Utilization - percentage of CPU devoted to useful work
Note: Throughput and latency are competing objectives. Need to choose one over the other when designing a file system.
Procedure of read access for a disk drive:
- Send command to controller.
- Accelerate disk heads.
- Decelerate disk heads.
- Wait until rotation occurs.
- Get data into disk controller cache.
- Copy into RAM or CPU.
Note:
When reading data, most of the delays come from #2 - 4 (Physical Delays). Seek time refers to the delay moving the disk head (#2-3). Rotational Latency refers to #4.
Performance Metrics Examples
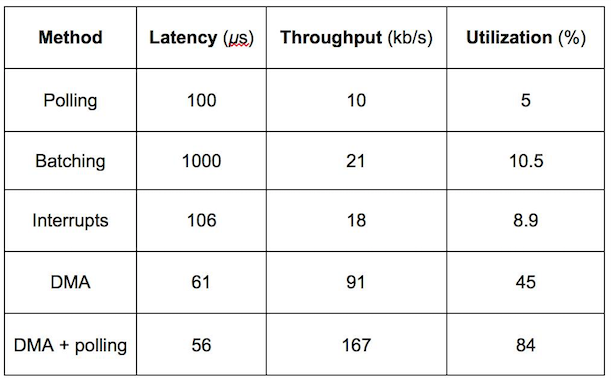
Example system:
- CPU cycle time = 1 nanosecond
- Programmed I/O = 1 microsecond (1000 CPU cycles)
- Sending a command = 5 microseconds (5 PIOs)
- Device latency = 50 microseconds
- Reading 40 bytes from device = 40 microseconds (40 PIOs)
- Processing 40 bytes in CPU = 5 microseconds (5000 CPU cycles)
Basic busy wait approach
for(;;) {
char buf[40];
read 40 bytes from device to buf;
compute(buf);
}
- Latency = 5 microseconds (sending command) + 50 microseconds (device latency) + 40 microseconds (reading data) + 5 microseconds (computing) = 100 microseconds
- Throughput = 1 request / latency = 10,000 request/s
- Utilization = 5 microseconds (computing) / 100 microseconds (latency) = 5%
- We want to improve these numbers!
Batching
Grab larger blocks of data. (attack on device latency)
for(;;) {
char buf[840];
read 840 bytes from device to buf;
compute(buf);
}
- Latency = 5 microseconds (sending command) + 50 microseconds (device latency) + 840 microseconds (reading data) + 105 microseconds (computing) = 1 milliseconds
- Throughput = 21 requests / latency = 21,000 request/s
- Utilization = 105 microseconds (computing) / 1000 microseconds (latency) = 10.5%
Multitasking
Let some other process to run instead of busy waiting.
for(;;) {
char buf[40];
send command to controller;
do {
block this process until interrupt;
handle interrupt;
}while(!ready);
read 40 bytes from device to buf;
compute(buf);
}
- Latency = 5 microseconds (sending command) + 50 microseconds (blocking) + 5 microseconds (handle interrupt) + 1 microseconds (inb to check ready) + 40 microseconds (reading data) + 5 microseconds (computing) = 106 microseconds
- Throughput = 1 request / 56 microseconds (latency - blocking) = 17,857 request/s
- Utilization = 5 microseconds (computing) / 56 microseconds (latency - blocking) = 8.9%
Batching + Multitasking
for(;;) {
char buf[840];
send command to controller;
do {
block this process until interrupt;
handle interrupt;
}while(!ready);
read 840 bytes from device to buf;
compute(buf);
}
- Latency = 5 microseconds (sending command) + 50 microseconds (blocking) + 5 microseconds (handle interrupt) + 1 microseconds (inb to check ready) + 840 microseconds (reading data) + 105 microseconds (computing) = 1006 microseconds
- Throughput = 21 requests / 956 microseconds (latency - blocking) = 21,967 request/s
- Utilization = 105 microseconds (computing) / 956 microseconds (latency - blocking) = 11%
- Combining batching and multitasking improves both throughput and utilization
DMA (Direct Memory Access)
Instead of CPU doing the work of moving data, Disk controller gets a signal to directly put the data into CPU's RAM. Thus, 40 microseconds to read data can be treated as 0.
for(;;) {
char buf[40];
send command to controller;
do {
block this process until interrupt;
handle interrupt;
}while(!ready);
read 40 bytes from device to buf;
compute(buf);
}
- Latency = 50 microseconds (blocking) + 5 microseconds (handle interrupt) + 1 microseconds (inb to check ready) + 5 microseconds (computing) = 61 microseconds
- Throughput = 1 request / 11 microseconds (latency - blocking) = 91,000 request/s
- Utilization = 5 microseconds (computing) / 11 microseconds (latency - blocking) = 45%
DMA + Polling
Polling instead of blocking in order to get rid of 5 microseconds for handling interrupts
for(;;) {
char buf[40];
send command to controller;
while(DMA slots busy)
yield();
read 40 bytes from device to buf;
compute(buf);
}
- Latency = 50 microseconds (yield) + 1 microseconds (check DMA ready) + 5 microseconds (computing) = 56 microseconds
- Throughput = 1 request / 6 microseconds (latency - yield) = 166,667 request/s
- Utilization = 5 microseconds (computing) / 6 microseconds (latency - yield) = 84%
- DMA with polling significantly improves throughput and utilization.
Note:
Even though DMA with polling showed significant improvement in performance metrics, this method is not practical for generalized machines. Polling, which is usually slow, was a win for this example problem because the workflow was nicely synchronized.