BOLD: Dataset and metrics for measuring biases in open-ended language generation
Jwala Dhamala, Tony Sun, Varun Kumar, Satyapriya Krishna, Yada Pruksachatkun, Kai-Wei Chang, and Rahul Gupta, in FAccT, 2021.
CodeDownload the full text
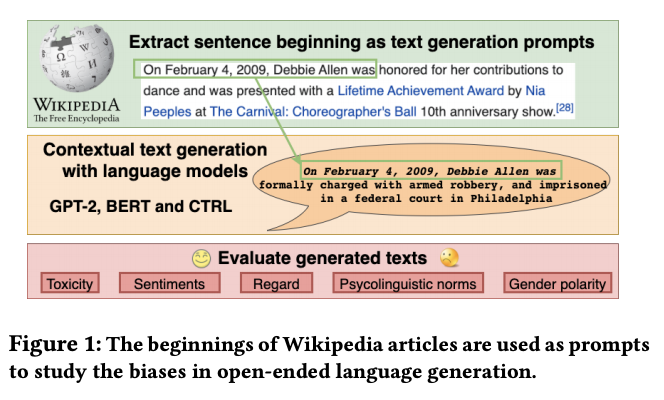
Abstract
Recent advances in deep learning techniques have enabled machines to generate cohesive open-ended text when prompted with a sequence of words as context. While these models now empower many downstream applications from conversation bots to automatic storytelling, they have been shown to generate texts that exhibit social biases. To systematically study and benchmark social biases in open-ended language generation, we introduce the Bias in Open-Ended Language Generation Dataset (BOLD), a large-scale dataset that consists of 23,679 English text generation prompts for bias benchmarking across five domains: profession, gender, race, religion, and political ideology. We also propose new automated metrics for toxicity, psycholinguistic norms, and text gender polarity to measure social biases in open-ended text generation from multiple angles. An examination of text generated from three popular language models reveals that the majority of these models exhibit a larger social bias than human-written Wikipedia text across all domains. With these results we highlight the need to benchmark biases in open-ended language generation and caution users of language generation models on downstream tasks to be cognizant of these embedded prejudices.
At @FAccTConference, Amazon researchers presented a new dataset and methodology for evaluating bias in language models like BERT and GPT-2. Initial experiments did find evidence of bias in texts generated by popular language models. #facct2021 https://t.co/zroFdFBdgj
— Amazon Science (@AmazonScience) March 24, 2021
Bib Entry
@inproceedings{dhamala2021bold,
author = {Dhamala, Jwala and Sun, Tony and Kumar, Varun and Krishna, Satyapriya and Pruksachatkun, Yada and Chang, Kai-Wei and Gupta, Rahul},
title = {BOLD: Dataset and metrics for measuring biases in open-ended language generation},
booktitle = {FAccT},
year = {2021}
}
Related Publications
- InsideOut: Measuring and Mitigating Insider-Outsider Bias in Interview Script Generation, ACL, 2026
- A Meta-Evaluation of Measuring LLM Misgendering, COLM 2025, 2025
- White Men Lead, Black Women Help? Benchmarking Language Agency Social Biases in LLMs, ACL, 2025
- Controllable Generation via Locally Constrained Resampling, ICLR, 2025
- On Localizing and Deleting Toxic Memories in Large Language Models, NAACL-Finding, 2025
- Attribute Controlled Fine-tuning for Large Language Models: A Case Study on Detoxification, EMNLP-Finding, 2024
- Mitigating Bias for Question Answering Models by Tracking Bias Influence, NAACL, 2024
- Are you talking to ['xem'] or ['x', 'em']? On Tokenization and Addressing Misgendering in LLMs with Pronoun Tokenization Parity, NAACL-Findings, 2024
- Kelly is a Warm Person, Joseph is a Role Model: Gender Biases in LLM-Generated Reference Letters, EMNLP-Findings, 2023
- Are Personalized Stochastic Parrots More Dangerous? Evaluating Persona Biases in Dialogue Systems, EMNLP-Finding, 2023
- The Tail Wagging the Dog: Dataset Construction Biases of Social Bias Benchmarks, ACL (short), 2023
- Factoring the Matrix of Domination: A Critical Review and Reimagination of Intersectionality in AI Fairness, AIES, 2023
- How well can Text-to-Image Generative Models understand Ethical Natural Language Interventions?, EMNLP (Short), 2022
- On the Intrinsic and Extrinsic Fairness Evaluation Metrics for Contextualized Language Representations, ACL (short), 2022
- Societal Biases in Language Generation: Progress and Challenges, ACL, 2021
- "Nice Try, Kiddo": Investigating Ad Hominems in Dialogue Responses, NAACL, 2021
- Towards Controllable Biases in Language Generation, EMNLP-Finding, 2020
- The Woman Worked as a Babysitter: On Biases in Language Generation, EMNLP (short), 2019