Mitigating Gender Bias Amplification in Distribution by Posterior Regularization
Shengyu Jia, Tao Meng, Jieyu Zhao, and Kai-Wei Chang, in ACL (short), 2020.
Slides CodeDownload the full text
Abstract
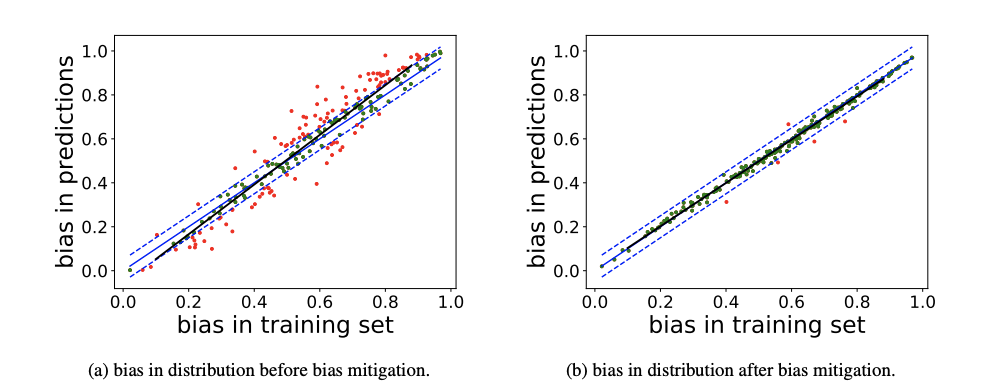
Advanced machine learning techniques have boosted the performance of natural language processing. Nevertheless, recent studies, e.g., Zhao et al. (2017) show that these techniques inadvertently capture the societal bias hiddenin the corpus and further amplify it. However,their analysis is conducted only on models’ top predictions. In this paper, we investigate thegender bias amplification issue from the distribution perspective and demonstrate that thebias is amplified in the view of predicted probability distribution over labels. We further propose a bias mitigation approach based on posterior regularization. With little performance loss, our method can almost remove the bias amplification in the distribution. Our study sheds the light on understanding the bias amplification.
[1/3] Our EMNLP17 paper (https://t.co/JVuBNCoi7X) demonstrates bias amplification in model’s top predictions. How about in distribution? Check our #acl2020nlp paper "Mitigating Gender Bias Amplification in Distribution by Posterior Regularization". https://t.co/JVuBNCoi7X. pic.twitter.com/Om6j0xxC3d
— Jieyu Zhao (@jieyuzhao11) June 20, 2020
Bib Entry
@inproceedings{jia2020mitigating,
author = {Jia, Shengyu and Meng, Tao and Zhao, Jieyu and Chang, Kai-Wei},
title = {Mitigating Gender Bias Amplification in Distribution by Posterior Regularization},
booktitle = {ACL (short)},
year = {2020},
presentation_id = {https://virtual.acl2020.org/paper_main.264.html}
}
Related Publications
- Measuring Fairness of Text Classifiers via Prediction Sensitivity, ACL, 2022
- Does Robustness Improve Fairness? Approaching Fairness with Word Substitution Robustness Methods for Text Classification, ACL-Finding, 2021
- LOGAN: Local Group Bias Detection by Clustering, EMNLP (short), 2020
- Towards Understanding Gender Bias in Relation Extraction, ACL, 2020
- Mitigating Gender in Natural Language Processing: Literature Review, ACL, 2019
- Gender Bias in Coreference Resolution: Evaluation and Debiasing Methods, NAACL (short), 2018
- Men Also Like Shopping: Reducing Gender Bias Amplification using Corpus-level Constraints, EMNLP, 2017