Cross-Lingual Dependency Parsing by POS-Guided Word Reordering
Lu Liu, Yi Zhou, Jianhan Xu, Xiaoqing Zheng, Kai-Wei Chang, and Xuanjing Huang, in EMNLP-Finding, 2020.
Download the full text
Abstract
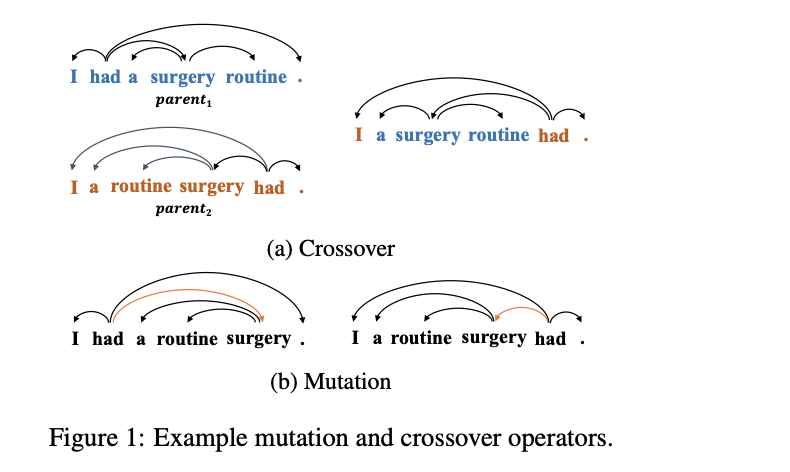
We propose a novel approach to cross-lingual dependency parsing based on word reordering. The words in each sentence of a source language corpus are rearranged to meet the word order in a target language under the guidance of a part-of-speech based language model (LM). To obtain the highest reordering score under the LM, a population-based optimization algorithm and its genetic operators are designed to deal with the combinatorial nature of such word reordering. A parser trained on the reordered corpus then can be used to parse sentences in the target language. We demonstrate through extensive experimentation that our approach achieves better or comparable results across 25 target languages (1.73% increase in average), and outperforms a baseline by a significant margin on the languages that are greatly different from the source one. For example, when transferring the English parser to Hindi and Latin, our approach outperforms the baseline by 15.3% and 6.7% respectively.
Bib Entry
@inproceedings{liu2020cross-lingual,
author = {Liu, Lu and Zhou, Yi and Xu, Jianhan and Zheng, Xiaoqing and Chang, Kai-Wei and Huang, Xuanjing},
title = {Cross-Lingual Dependency Parsing by POS-Guided Word Reordering},
booktitle = {EMNLP-Finding},
year = {2020}
}
Related Publications
- LiveCLKTBench: Towards Reliable Evaluation of Cross-Lingual Knowledge Transfer in Multilingual LLMs, ACL, 2026
- Contextual Label Projection for Cross-Lingual Structured Prediction, NAACL, 2024
- Multilingual Generative Language Models for Zero-Shot Cross-Lingual Event Argument Extraction, ACL, 2022
- Improving Zero-Shot Cross-Lingual Transfer Learning via Robust Training, EMNLP, 2021
- Syntax-augmented Multilingual BERT for Cross-lingual Transfer, ACL, 2021
- Evaluating the Values of Sources in Transfer Learning, NAACL, 2021
- GATE: Graph Attention Transformer Encoder for Cross-lingual Relation and Event Extraction, AAAI, 2021
- Cross-lingual Dependency Parsing with Unlabeled Auxiliary Languages, CoNLL, 2019
- Target Language-Aware Constrained Inference for Cross-lingual Dependency Parsing, EMNLP, 2019
- On Difficulties of Cross-Lingual Transfer with Order Differences: A Case Study on Dependency Parsing, NAACL, 2019