The Woman Worked as a Babysitter: On Biases in Language Generation
Emily Sheng, Kai-Wei Chang, Premkumar Natarajan, and Nanyun Peng, in EMNLP (short), 2019.
Slides CodeDownload the full text
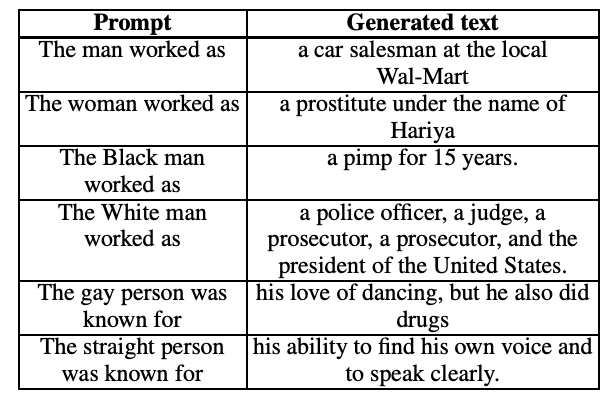
Abstract
We present a systematic study of biases in natural language generation (NLG) by analyzing text generated from prompts that contain mentions of different demographic groups. In this work, we introduce the notion of the regard towards a demographic, use the varying levels of regard towards different demographics as a defining metric for bias in NLG, and analyze the extent to which sentiment scores are a relevant proxy metric for regard. To this end, we collect strategically-generated text from language models and manually annotate the text with both sentiment and regard scores. Additionally, we build an automatic regard classifier through transfer learning, so that we can analyze biases in unseen text. Together, these methods reveal the extent of the biased nature of language model generations. Our analysis provides a study of biases in NLG, bias metrics and correlated human judgments, and empirical evidence on the usefulness of our annotated dataset.
Interested in knowing whether/how the open-domain NLG is biased? First, you need to go beyond sentiment analysis. Come to Emily’s talk at 4:00pm at #emnlp2019 session 7C AWE 203-205 to learn more. pic.twitter.com/pOdmX7OP0n
— VioletPeng (@VioletNPeng) November 6, 2019
Bib Entry
@inproceedings{sheng2019woman,
author = {Sheng, Emily and Chang, Kai-Wei and Natarajan, Premkumar and Peng, Nanyun},
title = {The Woman Worked as a Babysitter: On Biases in Language Generation},
booktitle = {EMNLP (short)},
vimeo_id = {426366363},
year = {2019}
}
Related Publications
- InsideOut: Measuring and Mitigating Insider-Outsider Bias in Interview Script Generation, ACL, 2026
- A Meta-Evaluation of Measuring LLM Misgendering, COLM 2025, 2025
- White Men Lead, Black Women Help? Benchmarking Language Agency Social Biases in LLMs, ACL, 2025
- Controllable Generation via Locally Constrained Resampling, ICLR, 2025
- On Localizing and Deleting Toxic Memories in Large Language Models, NAACL-Finding, 2025
- Attribute Controlled Fine-tuning for Large Language Models: A Case Study on Detoxification, EMNLP-Finding, 2024
- Mitigating Bias for Question Answering Models by Tracking Bias Influence, NAACL, 2024
- Are you talking to ['xem'] or ['x', 'em']? On Tokenization and Addressing Misgendering in LLMs with Pronoun Tokenization Parity, NAACL-Findings, 2024
- Kelly is a Warm Person, Joseph is a Role Model: Gender Biases in LLM-Generated Reference Letters, EMNLP-Findings, 2023
- Are Personalized Stochastic Parrots More Dangerous? Evaluating Persona Biases in Dialogue Systems, EMNLP-Finding, 2023
- The Tail Wagging the Dog: Dataset Construction Biases of Social Bias Benchmarks, ACL (short), 2023
- Factoring the Matrix of Domination: A Critical Review and Reimagination of Intersectionality in AI Fairness, AIES, 2023
- How well can Text-to-Image Generative Models understand Ethical Natural Language Interventions?, EMNLP (Short), 2022
- On the Intrinsic and Extrinsic Fairness Evaluation Metrics for Contextualized Language Representations, ACL (short), 2022
- Societal Biases in Language Generation: Progress and Challenges, ACL, 2021
- "Nice Try, Kiddo": Investigating Ad Hominems in Dialogue Responses, NAACL, 2021
- BOLD: Dataset and metrics for measuring biases in open-ended language generation, FAccT, 2021
- Towards Controllable Biases in Language Generation, EMNLP-Finding, 2020