UniFine: A Unified and Fine-grained Approach for Zero-shot Vision-Language Understanding
Rui Sun, Zhecan Wang, Haoxuan You, Noel Codella, Kai-Wei Chang, and Shih-Fu Chang, in ACL-Finding, 2023.
Download the full text
Abstract
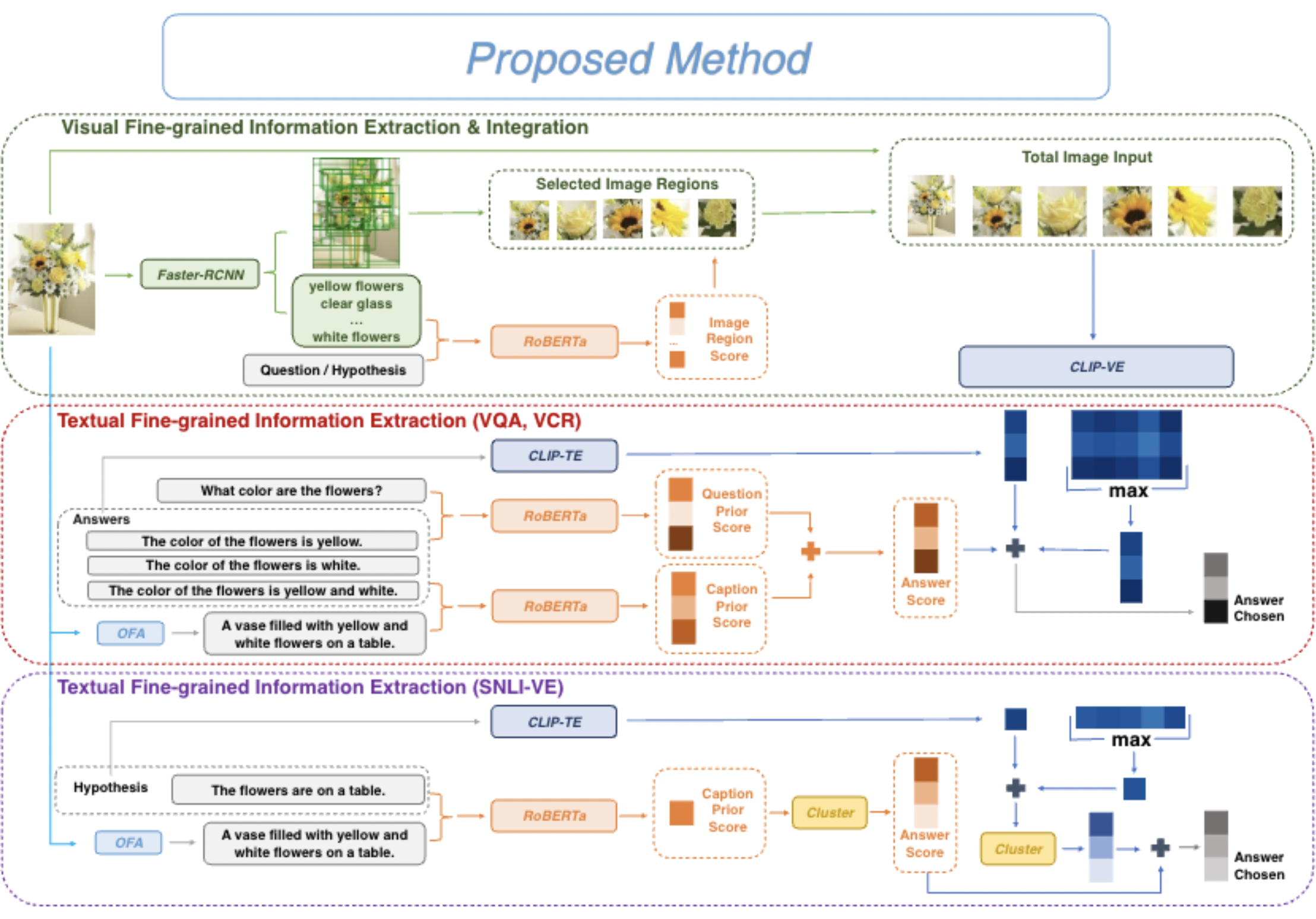
Vision-language tasks, such as VQA, SNLI-VE, and VCR are challenging because they require the model’s reasoning ability to understand the semantics of the visual world and natural language. Supervised methods working for vision-language tasks have been well-studied. However, solving these tasks in a zero-shot setting is less explored. Since Contrastive Language-Image Pre-training (CLIP) has shown remarkable zero-shot performance on image-text matching, previous works utilized its strong zero-shot ability by converting vision-language tasks into an image-text matching problem, and they mainly consider global-level matching (e.g., the whole image or sentence). However, we find visual and textual fine-grained information, e.g., keywords in the sentence and objects in the image, can be fairly informative for semantics understanding. Inspired by this, we propose a unified framework to take advantage of the fine-grained information for zero-shot vision-language learning, covering multiple tasks such as VQA, SNLI-VE, and VCR. Our experiments show that our framework outperforms former zero-shot methods on VQA and achieves substantial improvement on SNLI-VE and VCR. Furthermore, our ablation studies confirm the effectiveness and generalizability of our proposed method.
Bib Entry
@inproceedings{sun2023unifine,
author = {Sun, Rui and Wang, Zhecan and You, Haoxuan and Codella, Noel and Chang, Kai-Wei and Chang, Shih-Fu},
title = {UniFine: A Unified and Fine-grained Approach for Zero-shot Vision-Language Understanding},
booktitle = {ACL-Finding},
year = {2023},
presentation_id = {https://underline.io/events/395/posters/15279/poster/78004-unifine-a-unified-and-fine-grained-approach-for-zero-shot-vision-language-understanding}
}
Related Publications
- Where Fact Ends and Fairness Begins: Redefining AI Bias Evaluation through Cognitive Biases, EMNLP-Finding, 2025
- The Male CEO and the Female Assistant: Evaluation and Mitigation of Gender Biases in Text-To-Image Generation of Dual Subjects, ACL, 2025
- JourneyBench: A Challenging One-Stop Vision-Language Understanding Benchmark of Generated Images, NeurIPS (Datasets and Benchmarks Track), 2024
- The Factuality Tax of Diversity-Intervened Text-to-Image Generation: Benchmark and Fact-Augmented Intervention, EMNLP, 2024
- MACAROON: Training Vision-Language Models To Be Your Engaged Partners, EMNLP-Finding, 2024
- Dataset Bias Mitigation in Multiple-Choice Visual Question Answering and Beyond, EMNLP-Findings, 2023
- Resolving Ambiguities in Text-to-Image Generative Models, ACL, 2023