Multi-Task Learning for Document Ranking and Query Suggestion
Wasi Ahmad, Kai-Wei Chang, and Hongning Wang, in ICLR, 2018.
CodeDownload the full text
Abstract
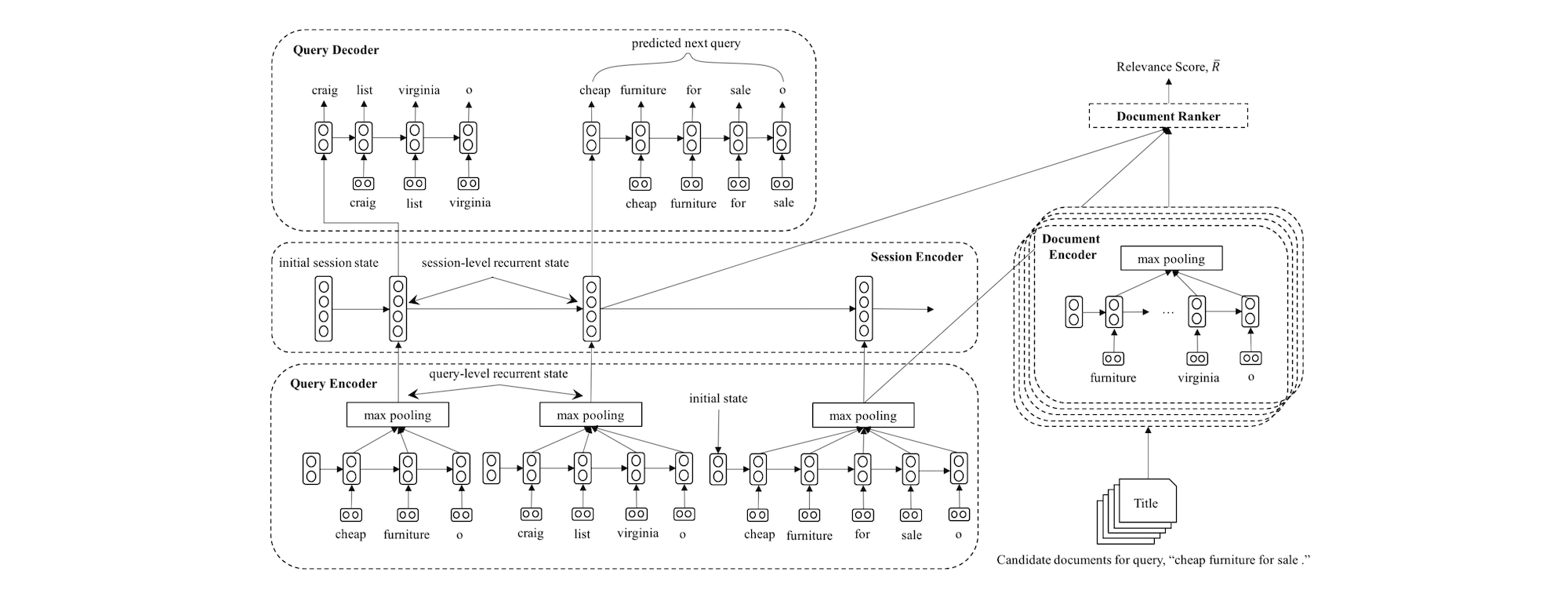
We propose a multi-task learning framework to jointly learn document ranking and query suggestion for web search. It consists of two major components, a document ranker and a query recommender. Document ranker combines current query and session information and compares the combined representation with document representation to rank the documents. Query recommen tracks users’ query reformulation sequence considering all previous in-session queries using a sequence to sequence approach. As both tasks are driven by the users’ underlying search intent, we perform joint learning of these two components through session recurrence, which encodes search context and intent. Extensive comparisons against state-of-the-art document ranking and query suggestion algorithms are performed on the public AOL search log, and the promising results endorse the effectiveness of the joint learning framework.
Bib Entry
@inproceedings{ahmad2018multitask,
author = {Ahmad, Wasi and Chang, Kai-Wei and Wang, Hongning},
title = {Multi-Task Learning for Document Ranking and Query Suggestion},
booktitle = {ICLR},
year = {2018}
}
Related Publications
- A Transformer-based Approach for Source Code Summarization, ACL (short), 2020
- Context Attentive Document Ranking and Query Suggestion, SIGIR, 2019
- Multifaceted Protein-Protein Interaction Prediction Based on Siamese Residual RCNN, ISMB, 2019
- Intent-aware Query Obfuscation for Privacy Protection in Personalized Web Search, SIGIR, 2018
- Counterexamples for Robotic Planning Explained in Structured Language, ICRA, 2018
- Word and sentence embedding tools to measure semantic similarity of Gene Ontology terms by their definitions, Journal of Computational Biology, 2018