ParaAMR: A Large-Scale Syntactically Diverse Paraphrase Dataset by AMR Back-Translation
Kuan-Hao Huang, Varun Iyer, I.-Hung Hsu, Anoop Kumar, Kai-Wei Chang, and Aram Galstyan, in ACL, 2023.
Area Chair’s Award
Download the full text
Abstract
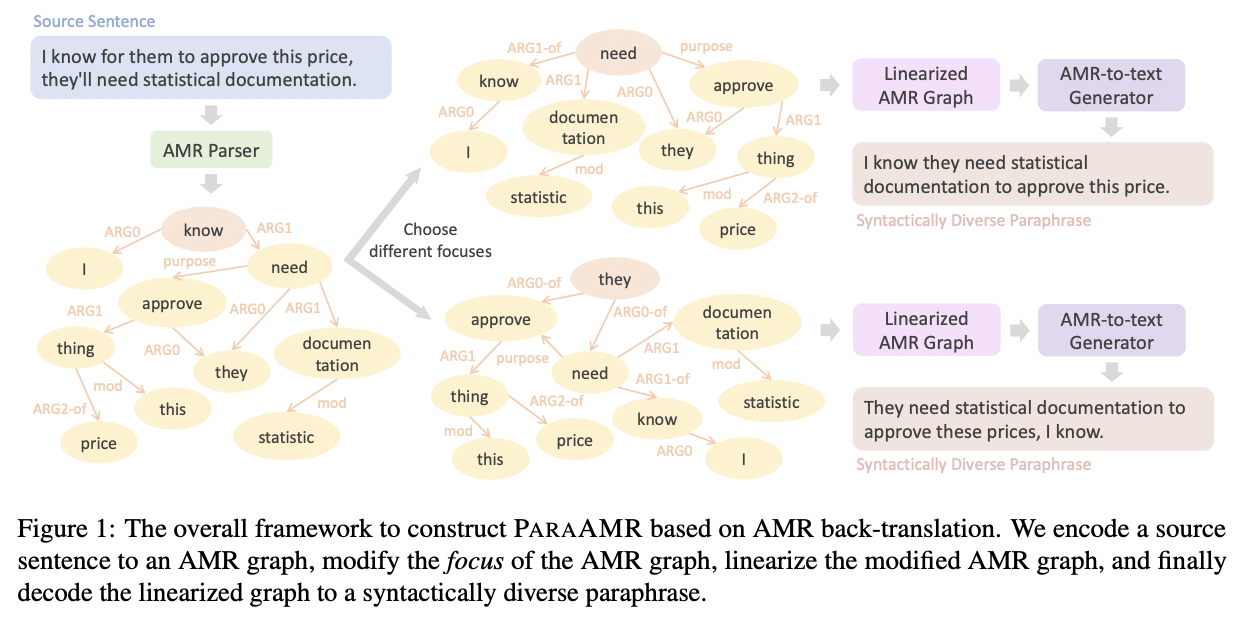
Paraphrase generation is a long-standing task in natural language processing (NLP). Supervised paraphrase generation models, which rely on human-annotated paraphrase pairs, are cost-inefficient and hard to scale up. On the other hand, automatically annotated paraphrase pairs (e.g., by machine back-translation), usually suffer from the lack of syntactic diversity – the generated paraphrase sentences are very similar to the source sentences in terms of syntax. In this work, we present ParaAMR, a large-scale syntactically diverse paraphrase dataset created by abstract meaning representation back-translation. Our quantitative analysis, qualitative examples, and human evaluation demonstrate that the paraphrases of ParaAMR are syntactically more diverse compared to existing large-scale paraphrase datasets while preserving good semantic similarity. In addition, we show that ParaAMR can be used to improve on three NLP tasks: learning sentence embeddings, syntactically controlled paraphrase generation, and data augmentation for few-shot learning. Our results thus showcase the potential of ParaAMR for improving various NLP applications.
Bib Entry
@inproceedings{huang2023paraarm,
author = {Huang, Kuan-Hao and Iyer, Varun and Hsu, I-Hung and Kumar, Anoop and Chang, Kai-Wei and Galstyan, Aram},
title = {ParaAMR: A Large-Scale Syntactically Diverse Paraphrase Dataset by AMR Back-Translation},
booktitle = {ACL},
presentation_id = {https://underline.io/events/395/posters/15227/poster/76600-paraamr-a-large-scale-syntactically-diverse-paraphrase-dataset-by-amr-back-translation},
year = {2023}
}
Related Publications
- MuirBench: A Comprehensive Benchmark for Robust Multi-image Understanding, ICLR, 2025
- ConTextual: Evaluating Context-Sensitive Text-Rich Visual Reasoning in Large Multimodal Models, ICML, 2024
- CASA: Causality-driven Argument Sufficiency Assessment, NAACL, 2024
- PLUE: Language Understanding Evaluation Benchmark for Privacy Policies in English, ACL (short), 2023