What Does BERT with Vision Look At?
Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, and Kai-Wei Chang, in ACL (short), 2020.
Slides CodeDownload the full text
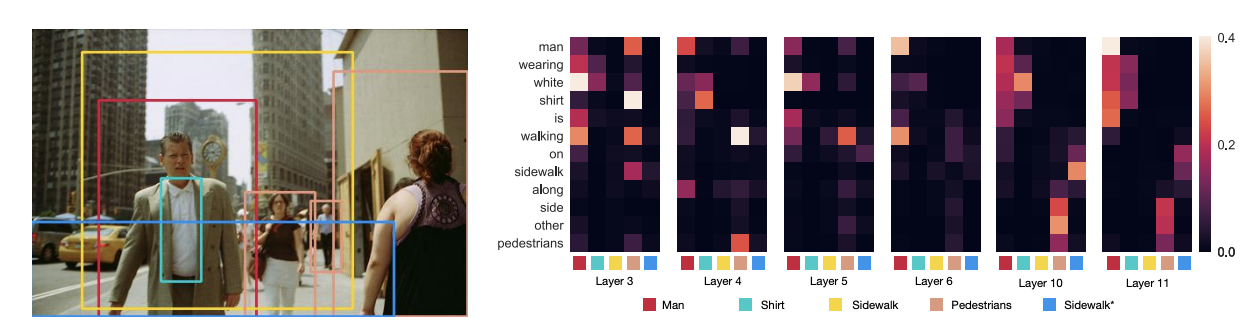
Abstract
Pre-trained visually grounded language models such as ViLBERT, LXMERT, and UNITER have achieved significant performance improvement on vision-and-language tasks but what they learn during pre-training remains unclear. In this work, we demonstrate that certain attention heads of a visually grounded language model actively ground elements of language to image regions. Specifically, some heads can map entities to image regions, performing the task known as entity grounding. Some heads can even detect the syntactic relations between non-entity words and image regions, tracking, for example, associations between verbs and regions corresponding to their arguments. We denote this ability as \emphsyntactic grounding. We verify grounding both quantitatively and qualitatively, using Flickr30K Entities as a testbed.
hot off the press -- VisualBert: A simple and performant baseline for vision and language. Language + image region proposals -> stack of Transformers + pretrain on captions = SOTA or near on 4 V&L problems. https://t.co/uQ4O2Jhe2S @LiLiunian +Cho-Jui Hsieh +Da Yin @kaiwei_chang
— Mark Yatskar (@yatskar) August 12, 2019
Bib Entry
@inproceedings{li2020what,
author = {Li, Liunian Harold and Yatskar, Mark and Yin, Da and Hsieh, Cho-Jui and Chang, Kai-Wei},
title = {What Does BERT with Vision Look At?},
booktitle = {ACL (short)},
presentation_id = {https://virtual.acl2020.org/paper_main.469.html},
year = {2020}
}